 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Singers: A Review of Deep-Learning-based Singing Voice Synthesis Approaches
Jan 20, 2026Recent advances in singing voice synthesis (SVS) have attracted substantial attention from both academia and industry. With the advent of large language models and novel generative paradigms, producing controllable, high-fidelity singing voices has become an attainable goal. Yet the field still lacks a comprehensive survey that systematically analyzes deep-learning-based singing voice synthesis systems and their enabling technologies. To address the aforementioned issue, this survey first categorizes existing systems by task type and then organizes current architectures into two major paradigms: cascaded and end-to-end approaches. Moreover, we provide an in-depth analysis of core technologies, covering singing modeling and control techniques. Finally, we review relevant datasets, annotation tools, and evaluation benchmarks that support training and assessment. In appendix, we introduce training strategies and further discussion of SVS. This survey provides an up-to-date review of the literature on SVS models, which would be a useful reference for both researchers and engineers. Related materials are available at https://github.com/David-Pigeon/SyntheticSingers.
TCSinger 2: Customizable Multilingual Zero-shot Singing Voice Synthesis
May 20, 2025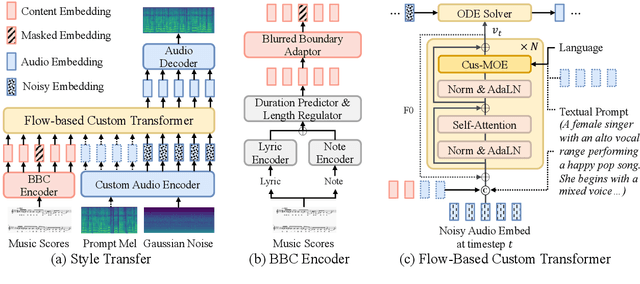
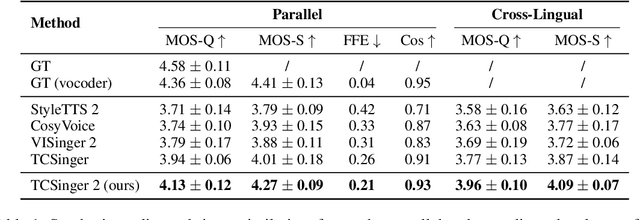
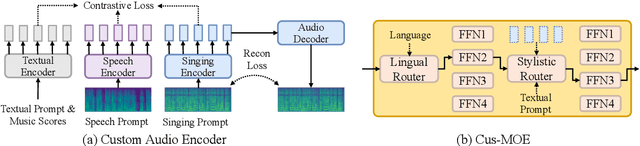
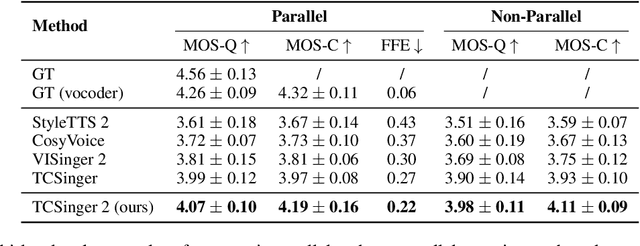
Customizable multilingual zero-shot singing voice synthesis (SVS) has various potential applications in music composition and short video dubbing. However, existing SVS models overly depend on phoneme and note boundary annotations, limiting their robustness in zero-shot scenarios and producing poor transitions between phonemes and notes. Moreover, they also lack effective multi-level style control via diverse prompts. To overcome these challenges, we introduce TCSinger 2, a multi-task multilingual zero-shot SVS model with style transfer and style control based on various prompts. TCSinger 2 mainly includes three key modules: 1) Blurred Boundary Content (BBC) Encoder, predicts duration, extends content embedding, and applies masking to the boundaries to enable smooth transitions. 2) Custom Audio Encoder, uses contrastive learning to extract aligned representations from singing, speech, and textual prompts. 3) Flow-based Custom Transformer, leverages Cus-MOE, with F0 supervision, enhancing both the synthesis quality and style modeling of the generated singing voice. Experimental results show that TCSinger 2 outperforms baseline models in both subjective and objective metrics across multiple related tasks.
VLM$^2$-Bench: A Closer Look at How Well VLMs Implicitly Link Explicit Matching Visual Cues
Feb 17, 2025



Visually linking matching cues is a crucial ability in daily life, such as identifying the same person in multiple photos based on their cues, even without knowing who they are. Despite the extensive knowledge that vision-language models (VLMs) possess, it remains largely unexplored whether they are capable of performing this fundamental task. To address this, we introduce VLM$^2$-Bench, a benchmark designed to assess whether VLMs can Visually Link Matching cues, with 9 subtasks and over 3,000 test cases. Comprehensive evaluation across eight open-source VLMs and GPT-4o, along with further analysis of various language-side and vision-side prompting methods, leads to a total of eight key findings. We identify critical challenges in models' ability to link visual cues, highlighting a significant performance gap where even GPT-4o lags 34.80% behind humans. Based on these insights, we advocate for (i) enhancing core visual capabilities to improve adaptability and reduce reliance on prior knowledge, (ii) establishing clearer principles for integrating language-based reasoning in vision-centric tasks to prevent unnecessary biases, and (iii) shifting vision-text training paradigms toward fostering models' ability to independently structure and infer relationships among visual cues.
CaLoRAify: Calorie Estimation with Visual-Text Pairing and LoRA-Driven Visual Language Models
Dec 13, 2024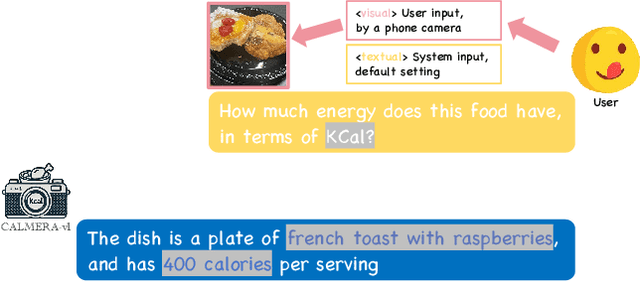
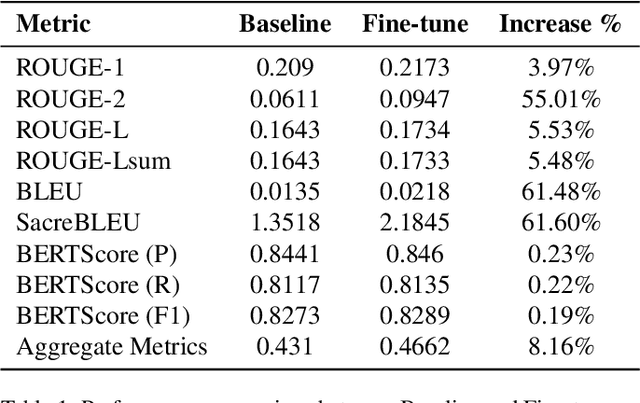
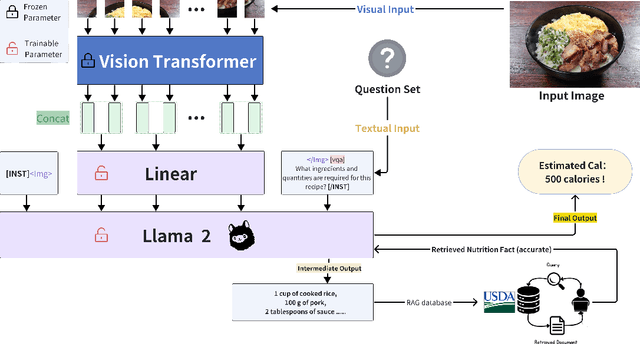

The obesity phenomenon, known as the heavy issue, is a leading cause of preventable chronic diseases worldwide. Traditional calorie estimation tools often rely on specific data formats or complex pipelines, limiting their practicality in real-world scenarios. Recently, vision-language models (VLMs) have excelled in understanding real-world contexts and enabling conversational interactions, making them ideal for downstream tasks such as ingredient analysis. However, applying VLMs to calorie estimation requires domain-specific data and alignment strategies. To this end, we curated CalData, a 330K image-text pair dataset tailored for ingredient recognition and calorie estimation, combining a large-scale recipe dataset with detailed nutritional instructions for robust vision-language training. Built upon this dataset, we present CaLoRAify, a novel VLM framework aligning ingredient recognition and calorie estimation via training with visual-text pairs. During inference, users only need a single monocular food image to estimate calories while retaining the flexibility of agent-based conversational interaction. With Low-rank Adaptation (LoRA) and Retrieve-augmented Generation (RAG) techniques, our system enhances the performance of foundational VLMs in the vertical domain of calorie estimation. Our code and data are fully open-sourced at https://github.com/KennyYao2001/16824-CaLORAify.
CORE: Mitigating Catastrophic Forgetting in Continual Learning through Cognitive Replay
Feb 02, 2024This paper introduces a novel perspective to significantly mitigate catastrophic forgetting in continuous learning (CL), which emphasizes models' capacity to preserve existing knowledge and assimilate new information. Current replay-based methods treat every task and data sample equally and thus can not fully exploit the potential of the replay buffer. In response, we propose COgnitive REplay (CORE), which draws inspiration from human cognitive review processes. CORE includes two key strategies: Adaptive Quantity Allocation and Quality-Focused Data Selection. The former adaptively modulates the replay buffer allocation for each task based on its forgetting rate, while the latter guarantees the inclusion of representative data that best encapsulates the characteristics of each task within the buffer. Our approach achieves an average accuracy of 37.95% on split-CIFAR10, surpassing the best baseline method by 6.52%. Additionally, it significantly enhances the accuracy of the poorest-performing task by 6.30% compared to the top baseline.
Lips Are Lying: Spotting the Temporal Inconsistency between Audio and Visual in Lip-Syncing DeepFakes
Jan 28, 2024



In recent years, DeepFake technology has achieved unprecedented success in high-quality video synthesis, whereas these methods also pose potential and severe security threats to humanity. DeepFake can be bifurcated into entertainment applications like face swapping and illicit uses such as lip-syncing fraud. However, lip-forgery videos, which neither change identity nor have discernible visual artifacts, present a formidable challenge to existing DeepFake detection methods. Our preliminary experiments have shown that the effectiveness of the existing methods often drastically decreases or even fails when tackling lip-syncing videos. In this paper, for the first time, we propose a novel approach dedicated to lip-forgery identification that exploits the inconsistency between lip movements and audio signals. We also mimic human natural cognition by capturing subtle biological links between lips and head regions to boost accuracy. To better illustrate the effectiveness and advances of our proposed method, we curate a high-quality LipSync dataset by employing the SOTA lip generator. We hope this high-quality and diverse dataset could be well served the further research on this challenging and interesting field. Experimental results show that our approach gives an average accuracy of more than 95.3% in spotting lip-syncing videos, significantly outperforming the baselines. Extensive experiments demonstrate the capability to tackle deepfakes and the robustness in surviving diverse input transformations. Our method achieves an accuracy of up to 90.2% in real-world scenarios (e.g., WeChat video call) and shows its powerful capabilities in real scenario deployment. To facilitate the progress of this research community, we release all resources at https://github.com/AaronComo/LipFD.
Dual-level Interaction for Domain Adaptive Semantic Segmentation
Jul 16, 2023



To circumvent the costly pixel-wise annotations of real-world images in the semantic segmentation task, the Unsupervised Domain Adaptation (UDA) is explored to firstly train a model with the labeled source data (synthetic images) and then adapt it to the unlabeled target data (real images). Among all the techniques being studied, the self-training approach recently secures its position in domain adaptive semantic segmentation, where a model is trained with target domain pseudo-labels. Current advances have mitigated noisy pseudo-labels resulting from the domain gap. However, they still struggle with erroneous pseudo-labels near the decision boundaries of the semantic classifier. In this paper, we tackle this issue by proposing a dual-level interaction for domain adaptation (DIDA) in semantic segmentation. Explicitly, we encourage the different augmented views of the same pixel to have not only similar class prediction (semantic-level) but also akin similarity relationship respected to other pixels (instance-level). As it is impossible to keep features of all pixel instances for a dataset, we novelly design and maintain a labeled instance bank with dynamic updating strategies to selectively store the informative features of instances. Further, DIDA performs cross-level interaction with scattering and gathering techniques to regenerate more reliable pseudolabels. Our method outperforms the state-of-the-art by a notable margin, especially on confusing and long-tailed classes. Code is available at https://github.com/RainJamesY/DIDA.