 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
CRAG -- Comprehensive RAG Benchmark
Jun 07, 2024



Retrieval-Augmented Generation (RAG) has recently emerged as a promising solution to alleviate Large Language Model (LLM)'s deficiency in lack of knowledge. Existing RAG datasets, however, do not adequately represent the diverse and dynamic nature of real-world Question Answering (QA) tasks. To bridge this gap, we introduce the Comprehensive RAG Benchmark (CRAG), a factual question answering benchmark of 4,409 question-answer pairs and mock APIs to simulate web and Knowledge Graph (KG) search. CRAG is designed to encapsulate a diverse array of questions across five domains and eight question categories, reflecting varied entity popularity from popular to long-tail, and temporal dynamisms ranging from years to seconds. Our evaluation on this benchmark highlights the gap to fully trustworthy QA. Whereas most advanced LLMs achieve <=34% accuracy on CRAG, adding RAG in a straightforward manner improves the accuracy only to 44%. State-of-the-art industry RAG solutions only answer 63% questions without any hallucination. CRAG also reveals much lower accuracy in answering questions regarding facts with higher dynamism, lower popularity, or higher complexity, suggesting future research directions. The CRAG benchmark laid the groundwork for a KDD Cup 2024 challenge, attracting thousands of participants and submissions within the first 50 days of the competition. We commit to maintaining CRAG to serve research communities in advancing RAG solutions and general QA solutions.
Head-to-Tail: How Knowledgeable are Large Language Models ? A.K.A. Will LLMs Replace Knowledge Graphs?
Aug 20, 2023



Since the recent prosperity of Large Language Models (LLMs), there have been interleaved discussions regarding how to reduce hallucinations from LLM responses, how to increase the factuality of LLMs, and whether Knowledge Graphs (KGs), which store the world knowledge in a symbolic form, will be replaced with LLMs. In this paper, we try to answer these questions from a new angle: How knowledgeable are LLMs? To answer this question, we constructed Head-to-Tail, a benchmark that consists of 18K question-answer (QA) pairs regarding head, torso, and tail facts in terms of popularity. We designed an automated evaluation method and a set of metrics that closely approximate the knowledge an LLM confidently internalizes. Through a comprehensive evaluation of 14 publicly available LLMs, we show that existing LLMs are still far from being perfect in terms of their grasp of factual knowledge, especially for facts of torso-to-tail entities.
Improving Opinion-based Question Answering Systems Through Label Error Detection and Overwrite
Jun 13, 2023Label error is a ubiquitous problem in annotated data. Large amounts of label error substantially degrades the quality of deep learning models. Existing methods to tackle the label error problem largely focus on the classification task, and either rely on task specific architecture or require non-trivial additional computations, which is undesirable or even unattainable for industry usage. In this paper, we propose LEDO: a model-agnostic and computationally efficient framework for Label Error Detection and Overwrite. LEDO is based on Monte Carlo Dropout combined with uncertainty metrics, and can be easily generalized to multiple tasks and data sets. Applying LEDO to an industry opinion-based question answering system demonstrates it is effective at improving accuracy in all the core models. Specifically, LEDO brings 1.1% MRR gain for the retrieval model, 1.5% PR AUC improvement for the machine reading comprehension model, and 0.9% rise in the Average Precision for the ranker, on top of the strong baselines with a large-scale social media dataset. Importantly, LEDO is computationally efficient compared to methods that require loss function change, and cost-effective as the resulting data can be used in the same continuous training pipeline for production. Further analysis shows that these gains come from an improved decision boundary after cleaning the label errors existed in the training data.
Inductive Relation Prediction by BERT
Mar 12, 2021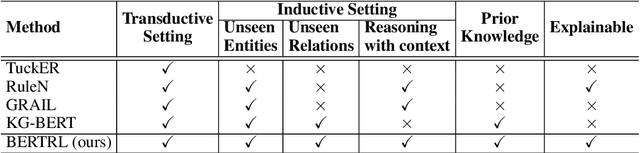
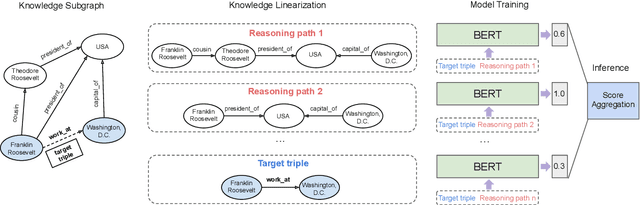

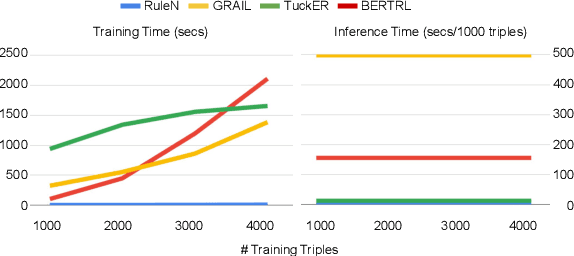
Relation prediction in knowledge graphs is dominated by embedding based methods which mainly focus on the transductive setting. Unfortunately, they are not able to handle inductive learning where unseen entities and relations are present and cannot take advantage of prior knowledge. Furthermore, their inference process is not easily explainable. In this work, we propose an all-in-one solution, called BERTRL (BERT-based Relational Learning), which leverages pre-trained language model and fine-tunes it by taking relation instances and their possible reasoning paths as training samples. BERTRL outperforms the SOTAs in 15 out of 18 cases in both inductive and transductive settings. Meanwhile, it demonstrates strong generalization capability in few-shot learning and is explainable.
Logic2Text: High-Fidelity Natural Language Generation from Logical Forms
Apr 30, 2020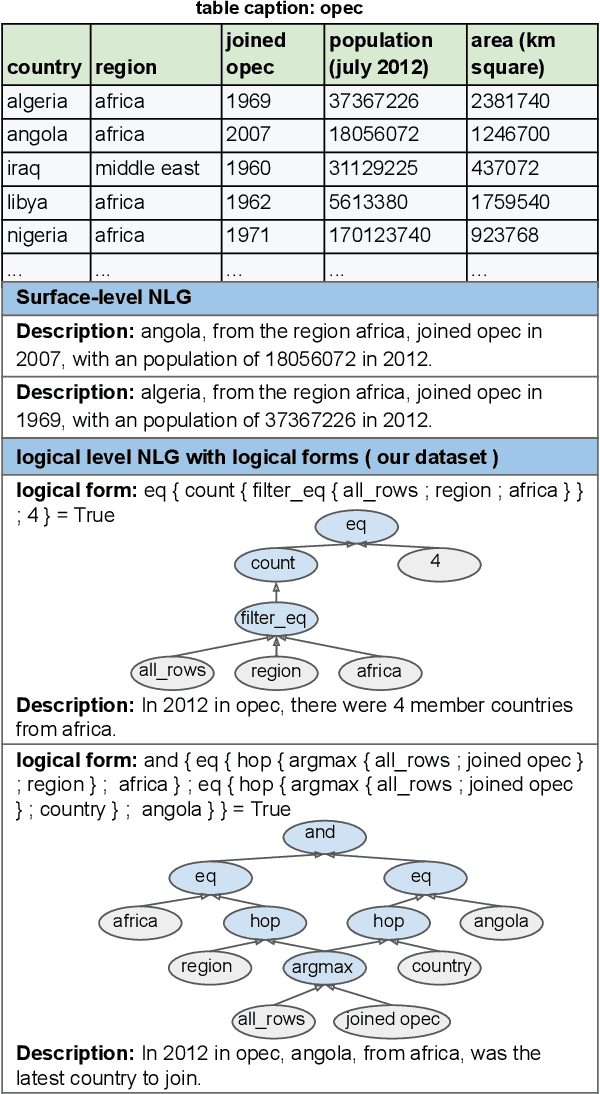

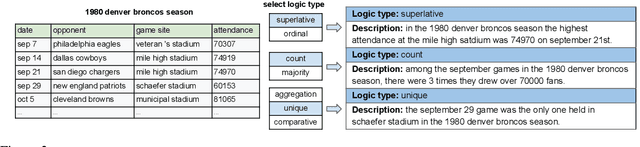

Previous works on Natural Language Generation (NLG) from structured data have primarily focused on surface-level descriptions of record sequences. However, for complex structured data, e.g., multi-row tables, it is often desirable for an NLG system to describe interesting facts from logical inferences across records. If only provided with the table, it is hard for existing models to produce controllable and high-fidelity logical generations. In this work, we formulate logical level NLG as generation from logical forms in order to obtain controllable, high-fidelity, and faithful generations. We present a new large-scale dataset, \textsc{Logic2Text}, with 10,753 descriptions involving common logic types paired with the underlying logical forms. The logical forms show diversified graph structure of free schema, which poses great challenges on the model's ability to understand the semantics. We experiment on (1) Fully-supervised training with the full datasets, and (2) Few-shot setting, provided with hundreds of paired examples; We compare several popular generation models and analyze their performances. We hope our dataset can encourage research towards building an advanced NLG system capable of natural, faithful, and human-like generation. The dataset and code are available at \url{https://github.com/czyssrs/Logic2Text}.
HybridQA: A Dataset of Multi-Hop Question Answering over Tabular and Textual Data
Apr 15, 2020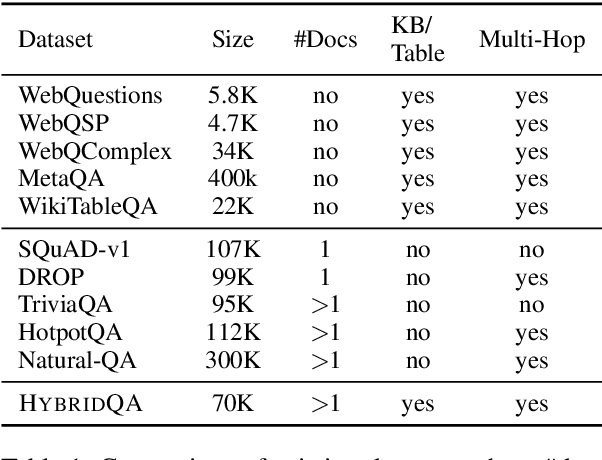

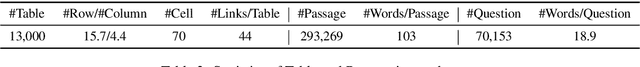
Existing question answering datasets focus on dealing with homogeneous information, based either only on text or KB/Table information alone. However, as human knowledge is distributed over heterogeneous forms, using homogeneous information might lead to severe coverage problems. To fill in the gap, we present \dataset, a new large-scale question-answering dataset that requires reasoning on heterogeneous information. Each question is aligned with a structured Wikipedia table and multiple free-form corpora linked with the entities in the table. The questions are designed to aggregate both tabular information and text information, i.e. lack of either form would render the question unanswerable. We test with three different models: 1) table-only model. 2) text-only model. 3) a hybrid model \model which combines both table and textual information to build a reasoning path towards the answer. The experimental results show that the first two baselines obtain compromised scores below 20\%, while \model significantly boosts EM score to over 50\%, which proves the necessity to aggregate both structure and unstructured information in \dataset. However, \model's score is still far behind human performance, hence we believe \dataset to an ideal and challenging benchmark to study question answering under heterogeneous information. The dataset and code are available at \url{https://github.com/wenhuchen/HybridQA}.
Global Textual Relation Embedding for Relational Understanding
Jun 03, 2019
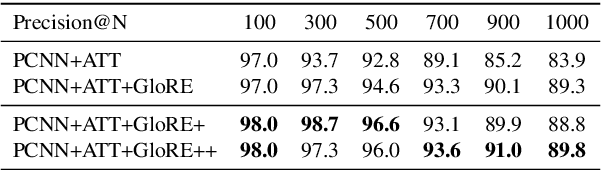
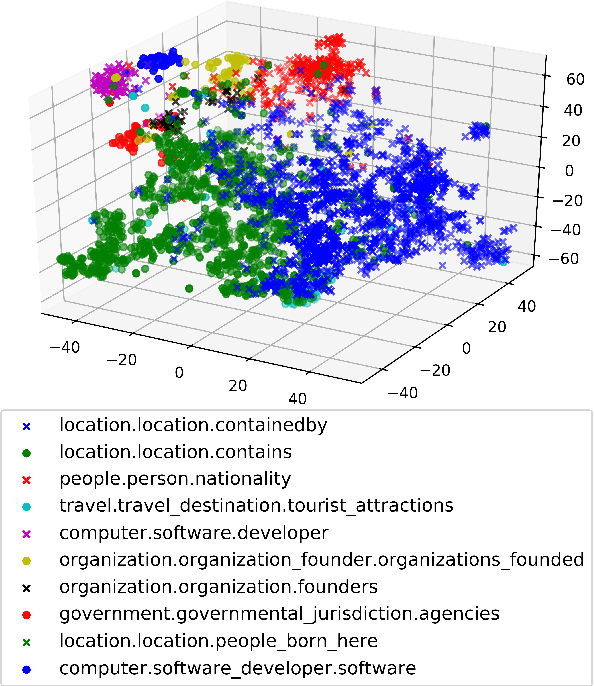
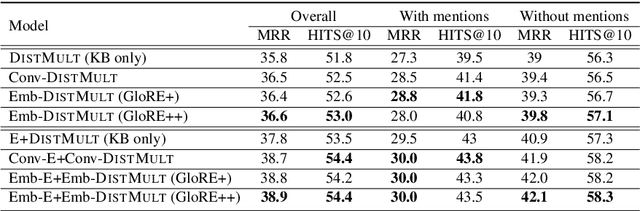
Pre-trained embeddings such as word embeddings and sentence embeddings are fundamental tools facilitating a wide range of downstream NLP tasks. In this work, we investigate how to learn a general-purpose embedding of textual relations, defined as the shortest dependency path between entities. Textual relation embedding provides a level of knowledge between word/phrase level and sentence level, and we show that it can facilitate downstream tasks requiring relational understanding of the text. To learn such an embedding, we create the largest distant supervision dataset by linking the entire English ClueWeb09 corpus to Freebase. We use global co-occurrence statistics between textual and knowledge base relations as the supervision signal to train the embedding. Evaluation on two relational understanding tasks demonstrates the usefulness of the learned textual relation embedding. The data and code can be found at https://github.com/czyssrs/GloREPlus