Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning for New Domains in Natural Language Understanding
Paper and Code
Oct 03, 2018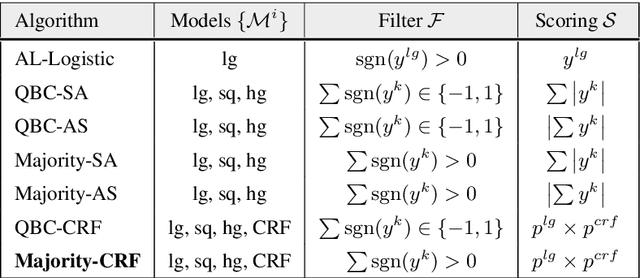
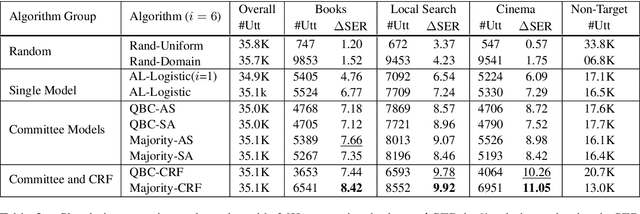
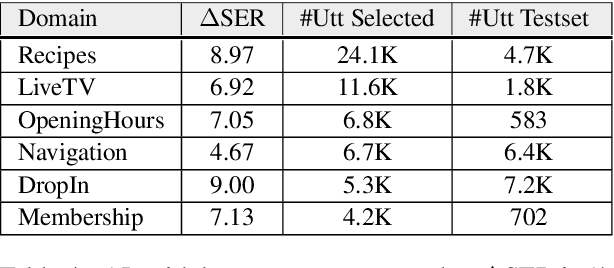
We explore active learning (AL) utterance selection for improving the accuracy of new underrepresented domains in a natural language understanding (NLU) system. Moreover, we propose an AL algorithm called Majority-CRF that uses an ensemble of classification and sequence labeling models to guide utterance selection for annotation. Experiments with three domains show that Majority-CRF achieves 6.6%-9% relative error rate reduction compared to random sampling with the same annotation budget, and statistically significant improvements compared to other AL approaches. Additionally, case studies with human-in-the-loop AL on six new domains show 4.6%-9% improvement on an existing NLU system.
* Amazon Research Days 2018
View paper on