 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-lingual Multi-turn Automated Red Teaming for LLMs
Apr 04, 2025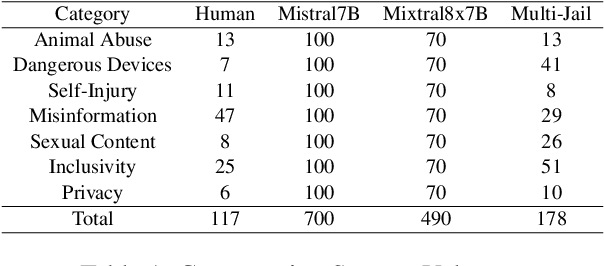
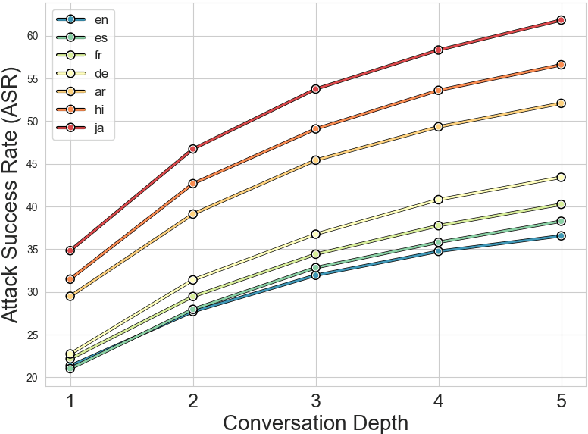
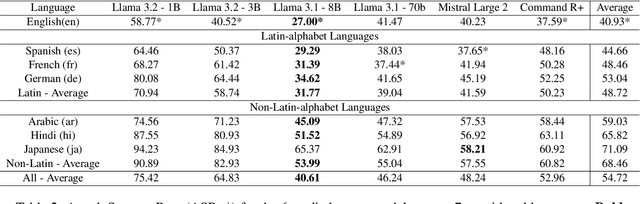
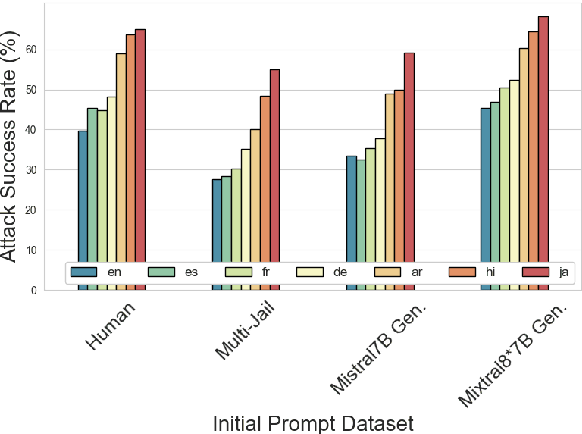
Language Model Models (LLMs) have improved dramatically in the past few years, increasing their adoption and the scope of their capabilities over time. A significant amount of work is dedicated to ``model alignment'', i.e., preventing LLMs to generate unsafe responses when deployed into customer-facing applications. One popular method to evaluate safety risks is \textit{red-teaming}, where agents attempt to bypass alignment by crafting elaborate prompts that trigger unsafe responses from a model. Standard human-driven red-teaming is costly, time-consuming and rarely covers all the recent features (e.g., multi-lingual, multi-modal aspects), while proposed automation methods only cover a small subset of LLMs capabilities (i.e., English or single-turn). We present Multi-lingual Multi-turn Automated Red Teaming (\textbf{MM-ART}), a method to fully automate conversational, multi-lingual red-teaming operations and quickly identify prompts leading to unsafe responses. Through extensive experiments on different languages, we show the studied LLMs are on average 71\% more vulnerable after a 5-turn conversation in English than after the initial turn. For conversations in non-English languages, models display up to 195\% more safety vulnerabilities than the standard single-turn English approach, confirming the need for automated red-teaming methods matching LLMs capabilities.
LoFTI: Localization and Factuality Transfer to Indian Locales
Jul 16, 2024



Large language models (LLMs) encode vast amounts of world knowledge acquired via training on large web-scale datasets crawled from the internet. However, these datasets typically exhibit a geographical bias towards English-speaking Western countries. This results in LLMs producing biased or hallucinated responses to queries that require answers localized to other geographical regions. In this work, we introduce a new benchmark named LoFTI (Localization and Factuality Transfer to Indian Locales) that can be used to evaluate an LLM's localization and factual text transfer capabilities. LoFTI consists of factual statements about entities in source and target locations; the source locations are spread across the globe and the target locations are all within India with varying degrees of hyperlocality (country, states, cities). The entities span a wide variety of categories. We use LoFTI to evaluate Mixtral, GPT-4 and two other Mixtral-based approaches well-suited to the task of localized factual transfer. We demonstrate that LoFTI is a high-quality evaluation benchmark and all the models, including GPT-4, produce skewed results across varying levels of hyperlocality.
Grading video interviews with fairness considerations
Jul 02, 2020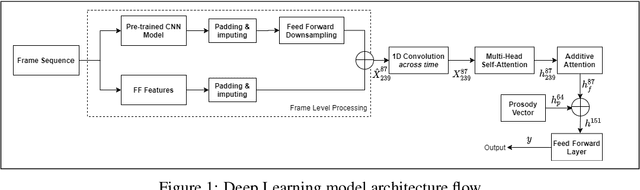
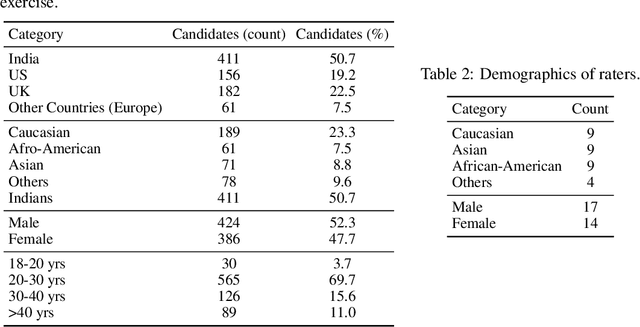


There has been considerable interest in predicting human emotions and traits using facial images and videos. Lately, such work has come under criticism for poor labeling practices, inconclusive prediction results and fairness considerations. We present a careful methodology to automatically derive social skills of candidates based on their video response to interview questions. We, for the first time, include video data from multiple countries encompassing multiple ethnicities. Also, the videos were rated by individuals from multiple racial backgrounds, following several best practices, to achieve a consensus and unbiased measure of social skills. We develop two machine-learning models to predict social skills. The first model employs expert-guidance to use plausibly causal features. The second uses deep learning and depends solely on the empirical correlations present in the data. We compare errors of both these models, study the specificity of the models and make recommendations. We further analyze fairness by studying the errors of models by race and gender. We verify the usefulness of our models by determining how well they predict interview outcomes for candidates. Overall, the study provides strong support for using artificial intelligence for video interview scoring, while taking care of fairness and ethical considerations.