 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShould LLMs, $\textit{like}$, Generate How Users Talk? Building Dialect-Accurate Dialog[ue]s Beyond the American Default with MDial
Jan 30, 2026More than 80% of the 1.6 billion English speakers do not use Standard American English (SAE) and experience higher failure rates and stereotyped responses when interacting with LLMs as a result. Yet multi-dialectal performance remains underexplored. We introduce $\textbf{MDial}$, the first large-scale framework for generating multi-dialectal conversational data encompassing the three pillars of written dialect -- lexical (vocabulary), orthographic (spelling), and morphosyntactic (grammar) features -- for nine English dialects. Partnering with native linguists, we design an annotated and scalable rule-based LLM transformation to ensure precision. Our approach challenges the assumption that models should mirror users' morphosyntactic features, showing that up to 90% of the grammatical features of a dialect should not be reproduced by models. Independent evaluations confirm data quality, with annotators preferring MDial outputs over prior methods in 98% of pairwise comparisons for dialect naturalness. Using this pipeline, we construct the dialect-parallel $\textbf{MDialBench}$mark with 50k+ dialogs, resulting in 97k+ QA pairs, and evaluate 17 LLMs on dialect identification and response generation tasks. Even frontier models achieve under 70% accuracy, fail to reach 50% for Canadian English, and systematically misclassify non-SAE dialects as American or British. As dialect identification underpins natural language understanding, these errors risk cascading failures into downstream tasks.
Multi-lingual Multi-turn Automated Red Teaming for LLMs
Apr 04, 2025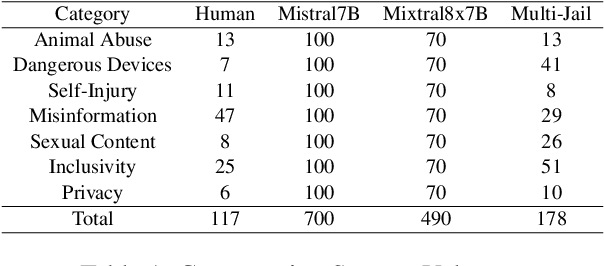
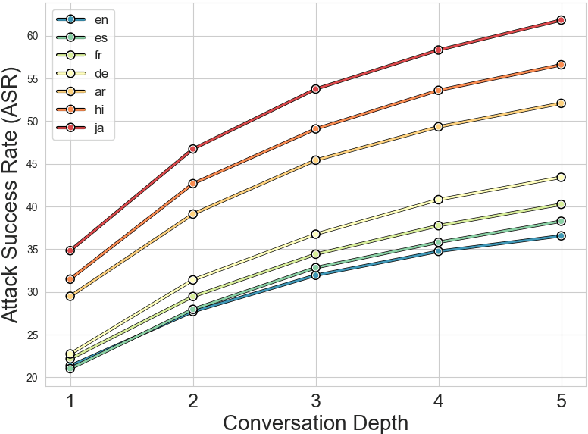
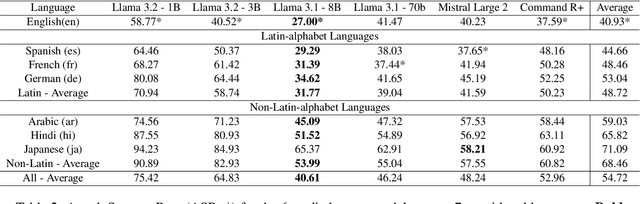
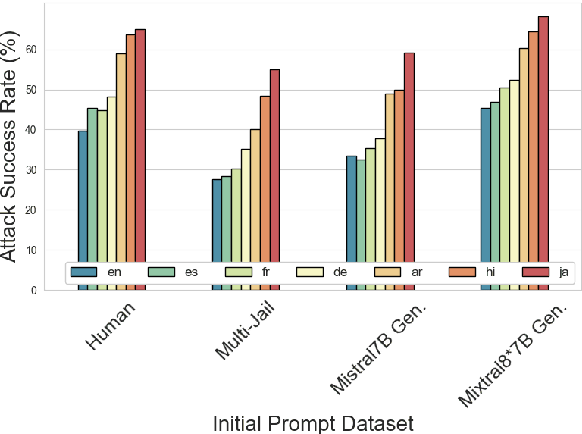
Language Model Models (LLMs) have improved dramatically in the past few years, increasing their adoption and the scope of their capabilities over time. A significant amount of work is dedicated to ``model alignment'', i.e., preventing LLMs to generate unsafe responses when deployed into customer-facing applications. One popular method to evaluate safety risks is \textit{red-teaming}, where agents attempt to bypass alignment by crafting elaborate prompts that trigger unsafe responses from a model. Standard human-driven red-teaming is costly, time-consuming and rarely covers all the recent features (e.g., multi-lingual, multi-modal aspects), while proposed automation methods only cover a small subset of LLMs capabilities (i.e., English or single-turn). We present Multi-lingual Multi-turn Automated Red Teaming (\textbf{MM-ART}), a method to fully automate conversational, multi-lingual red-teaming operations and quickly identify prompts leading to unsafe responses. Through extensive experiments on different languages, we show the studied LLMs are on average 71\% more vulnerable after a 5-turn conversation in English than after the initial turn. For conversations in non-English languages, models display up to 195\% more safety vulnerabilities than the standard single-turn English approach, confirming the need for automated red-teaming methods matching LLMs capabilities.
GeMQuAD : Generating Multilingual Question Answering Datasets from Large Language Models using Few Shot Learning
Apr 14, 2024The emergence of Large Language Models (LLMs) with capabilities like In-Context Learning (ICL) has ushered in new possibilities for data generation across various domains while minimizing the need for extensive data collection and modeling techniques. Researchers have explored ways to use this generated synthetic data to optimize smaller student models for reduced deployment costs and lower latency in downstream tasks. However, ICL-generated data often suffers from low quality as the task specificity is limited with few examples used in ICL. In this paper, we propose GeMQuAD - a semi-supervised learning approach, extending the WeakDAP framework, applied to a dataset generated through ICL with just one example in the target language using AlexaTM 20B Seq2Seq LLM. Through our approach, we iteratively identify high-quality data to enhance model performance, especially for low-resource multilingual setting in the context of Extractive Question Answering task. Our framework outperforms the machine translation-augmented model by 0.22/1.68 F1/EM (Exact Match) points for Hindi and 0.82/1.37 F1/EM points for Spanish on the MLQA dataset, and it surpasses the performance of model trained on an English-only dataset by 5.05/6.50 F1/EM points for Hindi and 3.81/3.69 points F1/EM for Spanish on the same dataset. Notably, our approach uses a pre-trained LLM for generation with no fine-tuning (FT), utilizing just a single annotated example in ICL to generate data, providing a cost-effective development process.