 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Large Language Models to Support High Volume Application Review for an Undergraduate Research Program
Jun 04, 2026Undergraduate research programs such as the Summer Undergraduate Research Fellowship (SURF) at Purdue University receive thousands of applications every year, requiring significant time and effort for program staff to evaluate each submission consistently and within tight timelines. This work-in-progress paper describes the development and initial deployment of a large language model (LLM)-based tool to assist in the evaluation of approximately 1,200 student Statements of Purpose (SoPs) for the SURF 2026 cycle at Purdue University. The workflow utilizes OpenAI GPT models (GPT-4o, GPT-5-mini, and GPT-5.2) and uses a structured rubric across six subcategories, each scored on a 0-3 scale. A few SoPs, graded by program staff, were used to tune the model responses. The model prompt was designed to generate both numerical scores, rationales (including positive and negative aspects) and short excerpts from each submission. Using GPT-5.2, the full batch of 1,200 SoPs was processed in approximately 4.6 hours of compute time, averaging roughly 14 seconds per SoP (with per-SoP timing varying with SoP length, which ranged from 500 to 2,000 words). Notable differences in rubric adherence were observed across model versions, with GPT-5.2 adhering most closely. Disagreement in model scores was more pronounced for lower-scoring submissions. The LLM outputs replicated the role previously played by distributed human graders, providing the program coordinator with scored and rationale-annotated outputs for the entire applicant pool. The program coordinator then reviewed these outputs alongside each applicant's SoP, applying the same downstream office criteria used in prior SURF cycles, to produce a shortlist of strong candidates. This coordinator review was completed in approximately 4 hours, compared to the multi-week coordination effort required in prior program cycles.
4Weed Dataset: Annotated Imagery Weeds Dataset
Mar 29, 2022

Weeds are a major threat to crops and are responsible for reducing crop yield worldwide. To mitigate their negative effect, it is advantageous to accurately identify them early in the season to prevent their spread throughout the field. Traditionally, farmers rely on manually scouting fields and applying herbicides for different weeds. However, it is easy to confuse between crops with weeds during the early growth stages. Recently, deep learning-based weed identification has become popular as deep learning relies on convolutional neural networks that are capable of learning important distinguishable features between weeds and crops. However, training robust deep learning models requires access to large imagery datasets. Therefore, an early-season weeds dataset was acquired under field conditions. The dataset consists of 159 Cocklebur images, 139 Foxtail images, 170 Redroot Pigweed images and 150 Giant Ragweed images corresponding to four common weed species found in corn and soybean production systems.. Bounding box annotations were created for each image to prepare the dataset for training both image classification and object detection deep learning networks capable of accurately locating and identifying weeds within corn and soybean fields. (https://osf.io/w9v3j/)
Grading video interviews with fairness considerations
Jul 02, 2020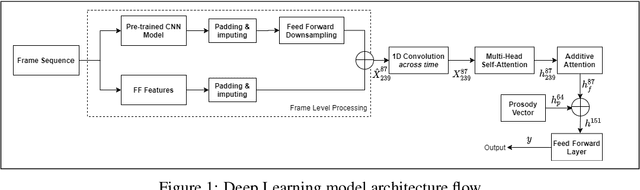
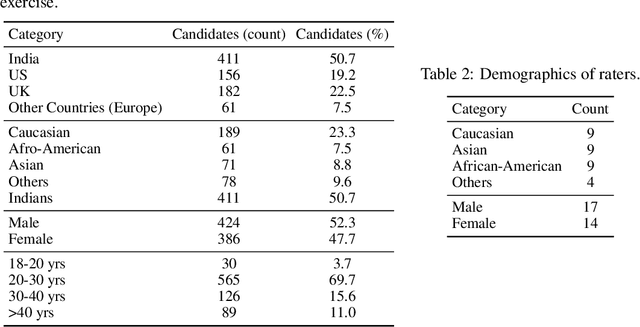


There has been considerable interest in predicting human emotions and traits using facial images and videos. Lately, such work has come under criticism for poor labeling practices, inconclusive prediction results and fairness considerations. We present a careful methodology to automatically derive social skills of candidates based on their video response to interview questions. We, for the first time, include video data from multiple countries encompassing multiple ethnicities. Also, the videos were rated by individuals from multiple racial backgrounds, following several best practices, to achieve a consensus and unbiased measure of social skills. We develop two machine-learning models to predict social skills. The first model employs expert-guidance to use plausibly causal features. The second uses deep learning and depends solely on the empirical correlations present in the data. We compare errors of both these models, study the specificity of the models and make recommendations. We further analyze fairness by studying the errors of models by race and gender. We verify the usefulness of our models by determining how well they predict interview outcomes for candidates. Overall, the study provides strong support for using artificial intelligence for video interview scoring, while taking care of fairness and ethical considerations.
A Doubly Distributed Genetic Algorithm for Network Coding
Apr 10, 2007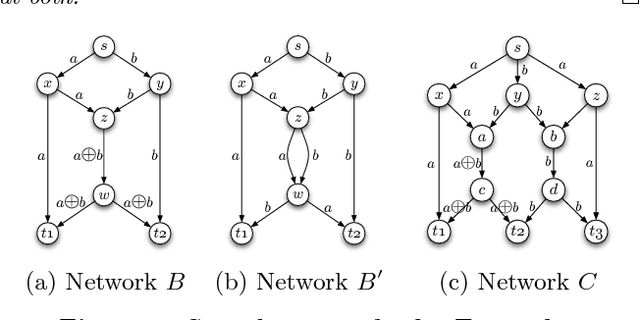
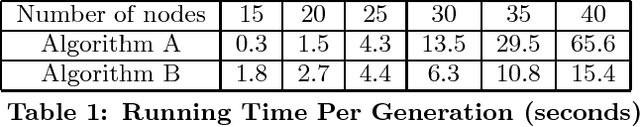
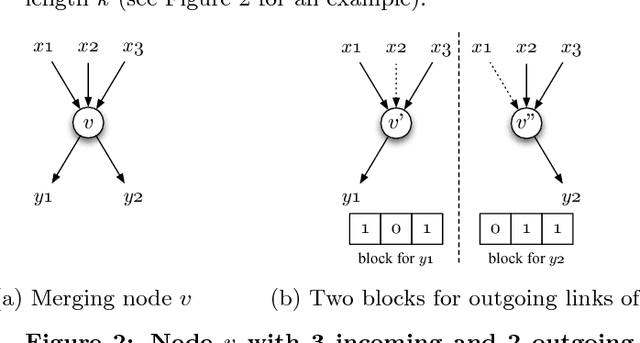
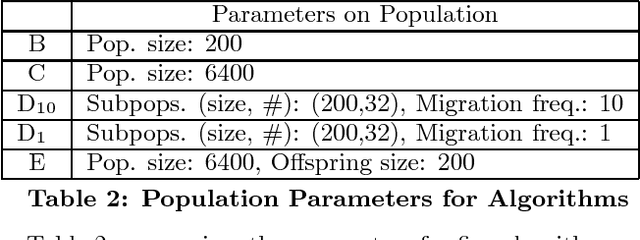
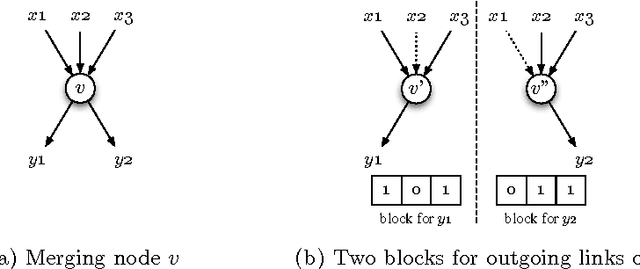
We present a genetic algorithm which is distributed in two novel ways: along genotype and temporal axes. Our algorithm first distributes, for every member of the population, a subset of the genotype to each network node, rather than a subset of the population to each. This genotype distribution is shown to offer a significant gain in running time. Then, for efficient use of the computational resources in the network, our algorithm divides the candidate solutions into pipelined sets and thus the distribution is in the temporal domain, rather that in the spatial domain. This temporal distribution may lead to temporal inconsistency in selection and replacement, however our experiments yield better efficiency in terms of the time to convergence without incurring significant penalties.
Genetic Representations for Evolutionary Minimization of Network Coding Resources
Feb 07, 2007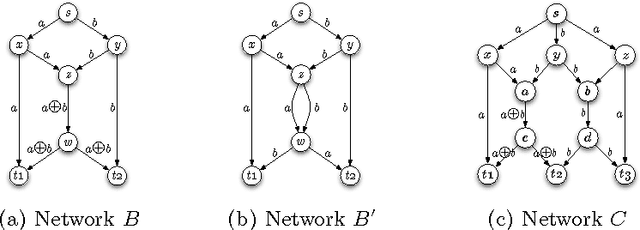


We demonstrate how a genetic algorithm solves the problem of minimizing the resources used for network coding, subject to a throughput constraint, in a multicast scenario. A genetic algorithm avoids the computational complexity that makes the problem NP-hard and, for our experiments, greatly improves on sub-optimal solutions of established methods. We compare two different genotype encodings, which tradeoff search space size with fitness landscape, as well as the associated genetic operators. Our finding favors a smaller encoding despite its fewer intermediate solutions and demonstrates the impact of the modularity enforced by genetic operators on the performance of the algorithm.