 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Off-Policy Imitation Learning with Deep Actor Critic Stabilization
Nov 10, 2025Learning complex policies with Reinforcement Learning (RL) is often hindered by instability and slow convergence, a problem exacerbated by the difficulty of reward engineering. Imitation Learning (IL) from expert demonstrations bypasses this reliance on rewards. However, state-of-the-art IL methods, exemplified by Generative Adversarial Imitation Learning (GAIL)Ho et. al, suffer from severe sample inefficiency. This is a direct consequence of their foundational on-policy algorithms, such as TRPO Schulman et.al. In this work, we introduce an adversarial imitation learning algorithm that incorporates off-policy learning to improve sample efficiency. By combining an off-policy framework with auxiliary techniques specifically, double Q network based stabilization and value learning without reward function inference we demonstrate a reduction in the samples required to robustly match expert behavior.
Convergence of Multiagent Learning Systems for Traffic control
Nov 10, 2025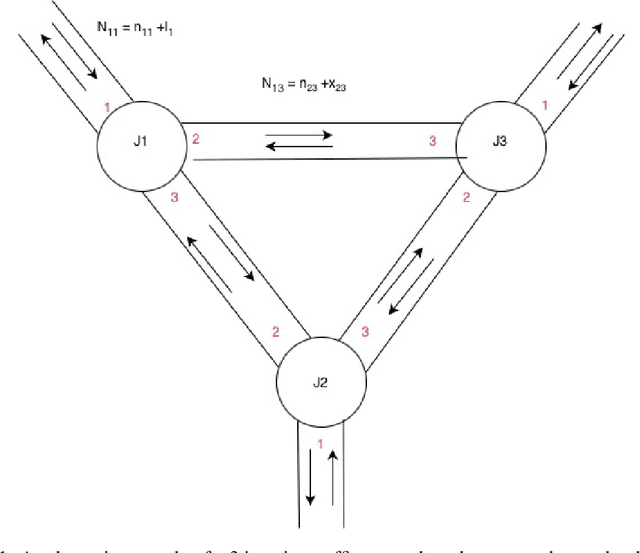

Rapid urbanization in cities like Bangalore has led to severe traffic congestion, making efficient Traffic Signal Control (TSC) essential. Multi-Agent Reinforcement Learning (MARL), often modeling each traffic signal as an independent agent using Q-learning, has emerged as a promising strategy to reduce average commuter delays. While prior work Prashant L A et. al has empirically demonstrated the effectiveness of this approach, a rigorous theoretical analysis of its stability and convergence properties in the context of traffic control has not been explored. This paper bridges that gap by focusing squarely on the theoretical basis of this multi-agent algorithm. We investigate the convergence problem inherent in using independent learners for the cooperative TSC task. Utilizing stochastic approximation methods, we formally analyze the learning dynamics. The primary contribution of this work is the proof that the specific multi-agent reinforcement learning algorithm for traffic control is proven to converge under the given conditions extending it from single agent convergence proofs for asynchronous value iteration.
LoFTI: Localization and Factuality Transfer to Indian Locales
Jul 16, 2024



Large language models (LLMs) encode vast amounts of world knowledge acquired via training on large web-scale datasets crawled from the internet. However, these datasets typically exhibit a geographical bias towards English-speaking Western countries. This results in LLMs producing biased or hallucinated responses to queries that require answers localized to other geographical regions. In this work, we introduce a new benchmark named LoFTI (Localization and Factuality Transfer to Indian Locales) that can be used to evaluate an LLM's localization and factual text transfer capabilities. LoFTI consists of factual statements about entities in source and target locations; the source locations are spread across the globe and the target locations are all within India with varying degrees of hyperlocality (country, states, cities). The entities span a wide variety of categories. We use LoFTI to evaluate Mixtral, GPT-4 and two other Mixtral-based approaches well-suited to the task of localized factual transfer. We demonstrate that LoFTI is a high-quality evaluation benchmark and all the models, including GPT-4, produce skewed results across varying levels of hyperlocality.
Zero-Shot Generalization using Intrinsically Motivated Compositional Emergent Protocols
May 11, 2021
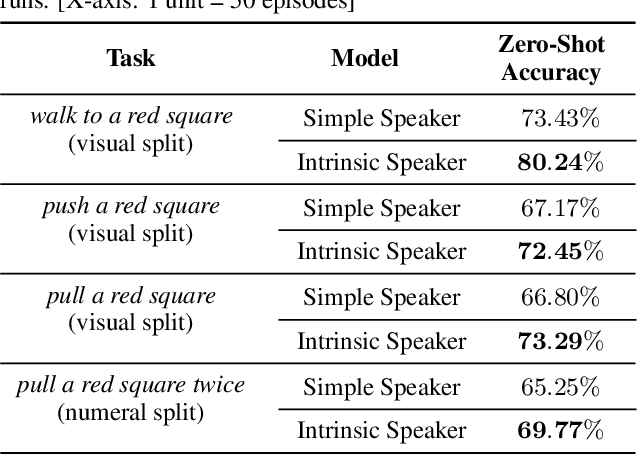
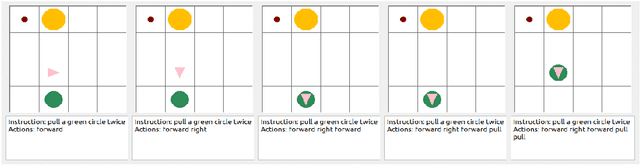
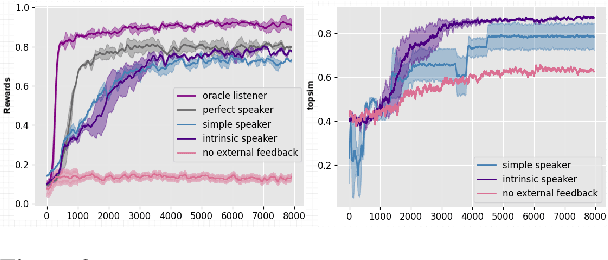
Human language has been described as a system that makes \textit{use of finite means to express an unlimited array of thoughts}. Of particular interest is the aspect of compositionality, whereby, the meaning of a compound language expression can be deduced from the meaning of its constituent parts. If artificial agents can develop compositional communication protocols akin to human language, they can be made to seamlessly generalize to unseen combinations. Studies have recognized the role of curiosity in enabling linguistic development in children. In this paper, we seek to use this intrinsic feedback in inducing a systematic and unambiguous protolanguage. We demonstrate how compositionality can enable agents to not only interact with unseen objects but also transfer skills from one task to another in a zero-shot setting: \textit{Can an agent, trained to `pull' and `push twice', `pull twice'?}.
Infinite use of finite means: Zero-Shot Generalization using Compositional Emergent Protocols
Dec 13, 2020



Human language has been described as a system that makes use of finite means to express an unlimited array of thoughts. Of particular interest is the aspect of compositionality, whereby, the meaning of a complex, compound language expression can be deduced from the meaning of its constituent parts. If artificial agents can develop compositional communication protocols akin to human language, they can be made to seamlessly generalize to unseen combinations. However, the real question is, how do we induce compositionality in emergent communication? Studies have recognized the role of curiosity in enabling linguistic development in children. It is this same intrinsic urge that drives us to master complex tasks with decreasing amounts of explicit reward. In this paper, we seek to use this intrinsic feedback in inducing a systematic and unambiguous protolanguage in artificial agents. We show in our experiments, how these rewards can be leveraged in training agents to induce compositionality in absence of any external feedback. Additionally, we introduce Comm-gSCAN, a platform for investigating grounded language acquisition in 2D-grid environments. Using this, we demonstrate how compositionality can enable agents to not only interact with unseen objects, but also transfer skills from one task to other in zero-shot (Can an agent, trained to pull and push twice, pull twice?)