 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing Best Practices for Building Rigorous Agentic Benchmarks
Jul 03, 2025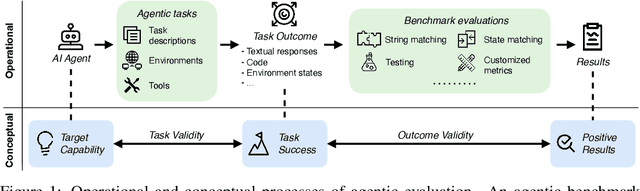
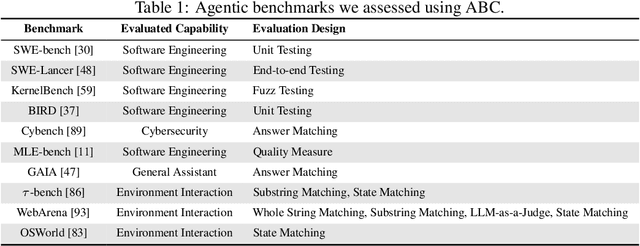
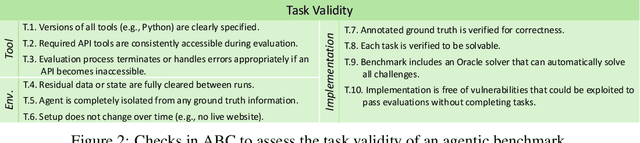
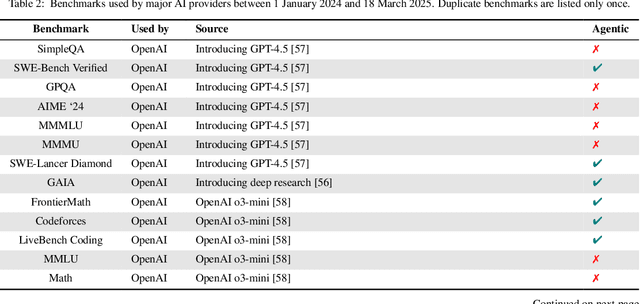
Benchmarks are essential for quantitatively tracking progress in AI. As AI agents become increasingly capable, researchers and practitioners have introduced agentic benchmarks to evaluate agents on complex, real-world tasks. These benchmarks typically measure agent capabilities by evaluating task outcomes via specific reward designs. However, we show that many agentic benchmarks have issues task setup or reward design. For example, SWE-bench Verified uses insufficient test cases, while TAU-bench counts empty responses as successful. Such issues can lead to under- or overestimation agents' performance by up to 100% in relative terms. To make agentic evaluation rigorous, we introduce the Agentic Benchmark Checklist (ABC), a set of guidelines that we synthesized from our benchmark-building experience, a survey of best practices, and previously reported issues. When applied to CVE-Bench, a benchmark with a particularly complex evaluation design, ABC reduces the performance overestimation by 33%.
Tree-of-Traversals: A Zero-Shot Reasoning Algorithm for Augmenting Black-box Language Models with Knowledge Graphs
Jul 31, 2024



Knowledge graphs (KGs) complement Large Language Models (LLMs) by providing reliable, structured, domain-specific, and up-to-date external knowledge. However, KGs and LLMs are often developed separately and must be integrated after training. We introduce Tree-of-Traversals, a novel zero-shot reasoning algorithm that enables augmentation of black-box LLMs with one or more KGs. The algorithm equips a LLM with actions for interfacing a KG and enables the LLM to perform tree search over possible thoughts and actions to find high confidence reasoning paths. We evaluate on two popular benchmark datasets. Our results show that Tree-of-Traversals significantly improves performance on question answering and KG question answering tasks. Code is available at \url{https://github.com/amazon-science/tree-of-traversals}
Are you talking to or ? On Tokenization and Addressing Misgendering in LLMs with Pronoun Tokenization Parity
Dec 21, 2023A large body of NLP research has documented the ways gender biases manifest and amplify within large language models (LLMs), though this research has predominantly operated within a gender binary-centric context. A growing body of work has identified the harmful limitations of this gender-exclusive framing; many LLMs cannot correctly and consistently refer to persons outside the gender binary, especially if they use neopronouns. While data scarcity has been identified as a possible culprit, the precise mechanisms through which it influences LLM misgendering remain underexplored. Our work addresses this gap by studying data scarcity's role in subword tokenization and, consequently, the formation of LLM word representations. We uncover how the Byte-Pair Encoding (BPE) tokenizer, a backbone for many popular LLMs, contributes to neopronoun misgendering through out-of-vocabulary behavior. We introduce pronoun tokenization parity (PTP), a novel approach to reduce LLM neopronoun misgendering by preserving a token's functional structure. We evaluate PTP's efficacy using pronoun consistency-based metrics and a novel syntax-based metric. Through several controlled experiments, finetuning LLMs with PTP improves neopronoun consistency from 14.5% to 58.4%, highlighting the significant role tokenization plays in LLM pronoun consistency.
JAB: Joint Adversarial Prompting and Belief Augmentation
Nov 16, 2023



With the recent surge of language models in different applications, attention to safety and robustness of these models has gained significant importance. Here we introduce a joint framework in which we simultaneously probe and improve the robustness of a black-box target model via adversarial prompting and belief augmentation using iterative feedback loops. This framework utilizes an automated red teaming approach to probe the target model, along with a belief augmenter to generate instructions for the target model to improve its robustness to those adversarial probes. Importantly, the adversarial model and the belief generator leverage the feedback from past interactions to improve the effectiveness of the adversarial prompts and beliefs, respectively. In our experiments, we demonstrate that such a framework can reduce toxic content generation both in dynamic cases where an adversary directly interacts with a target model and static cases where we use a static benchmark dataset to evaluate our model.
"I'm fully who I am": Towards Centering Transgender and Non-Binary Voices to Measure Biases in Open Language Generation
May 18, 2023

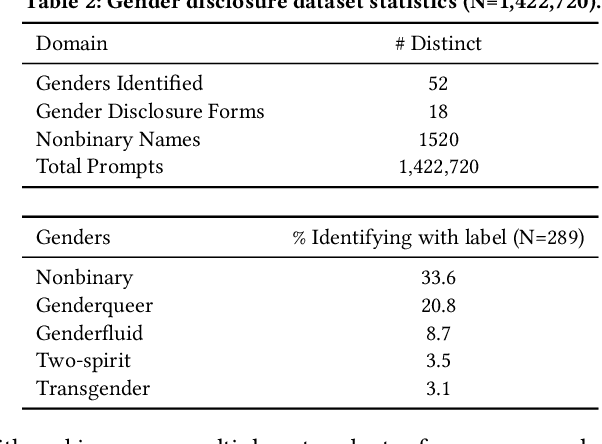

Transgender and non-binary (TGNB) individuals disproportionately experience discrimination and exclusion from daily life. Given the recent popularity and adoption of language generation technologies, the potential to further marginalize this population only grows. Although a multitude of NLP fairness literature focuses on illuminating and addressing gender biases, assessing gender harms for TGNB identities requires understanding how such identities uniquely interact with societal gender norms and how they differ from gender binary-centric perspectives. Such measurement frameworks inherently require centering TGNB voices to help guide the alignment between gender-inclusive NLP and whom they are intended to serve. Towards this goal, we ground our work in the TGNB community and existing interdisciplinary literature to assess how the social reality surrounding experienced marginalization by TGNB persons contributes to and persists within Open Language Generation (OLG). By first understanding their marginalization stressors, we evaluate (1) misgendering and (2) harmful responses to gender disclosure. To do this, we introduce the TANGO dataset, comprising of template-based text curated from real-world text within a TGNB-oriented community. We discover a dominance of binary gender norms within the models; LLMs least misgendered subjects in generated text when triggered by prompts whose subjects used binary pronouns. Meanwhile, misgendering was most prevalent when triggering generation with singular they and neopronouns. When prompted with gender disclosures, LLM text contained stigmatizing language and scored most toxic when triggered by TGNB gender disclosure. Our findings warrant further research on how TGNB harms manifest in LLMs and serve as a broader case study toward concretely grounding the design of gender-inclusive AI in community voices and interdisciplinary literature.
Is the Elephant Flying? Resolving Ambiguities in Text-to-Image Generative Models
Nov 17, 2022Natural language often contains ambiguities that can lead to misinterpretation and miscommunication. While humans can handle ambiguities effectively by asking clarifying questions and/or relying on contextual cues and common-sense knowledge, resolving ambiguities can be notoriously hard for machines. In this work, we study ambiguities that arise in text-to-image generative models. We curate a benchmark dataset covering different types of ambiguities that occur in these systems. We then propose a framework to mitigate ambiguities in the prompts given to the systems by soliciting clarifications from the user. Through automatic and human evaluations, we show the effectiveness of our framework in generating more faithful images aligned with human intention in the presence of ambiguities.
An Analysis of the Effects of Decoding Algorithms on Fairness in Open-Ended Language Generation
Oct 07, 2022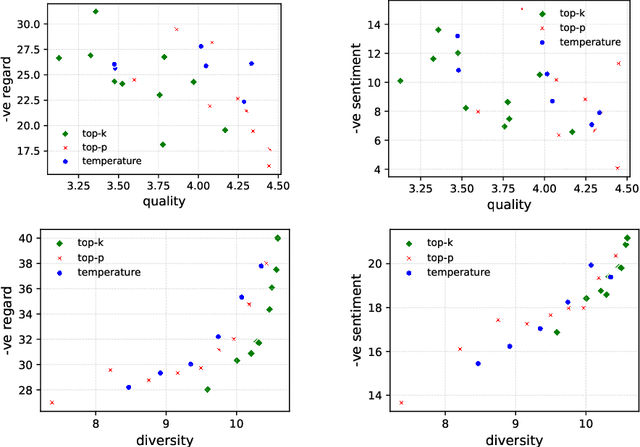



Several prior works have shown that language models (LMs) can generate text containing harmful social biases and stereotypes. While decoding algorithms play a central role in determining properties of LM generated text, their impact on the fairness of the generations has not been studied. We present a systematic analysis of the impact of decoding algorithms on LM fairness, and analyze the trade-off between fairness, diversity and quality. Our experiments with top-$p$, top-$k$ and temperature decoding algorithms, in open-ended language generation, show that fairness across demographic groups changes significantly with change in decoding algorithm's hyper-parameters. Notably, decoding algorithms that output more diverse text also output more texts with negative sentiment and regard. We present several findings and provide recommendations on standardized reporting of decoding details in fairness evaluations and optimization of decoding algorithms for fairness alongside quality and diversity.
On the Intrinsic and Extrinsic Fairness Evaluation Metrics for Contextualized Language Representations
Mar 25, 2022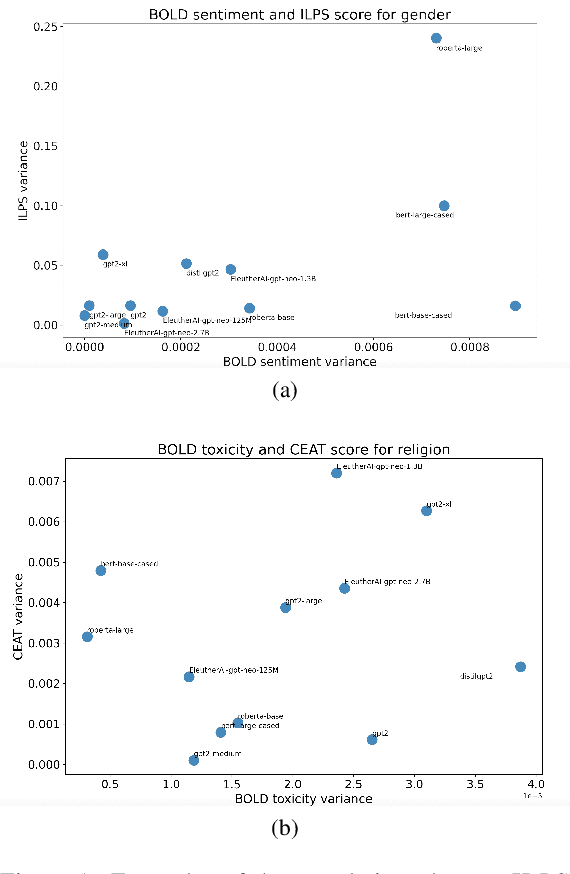
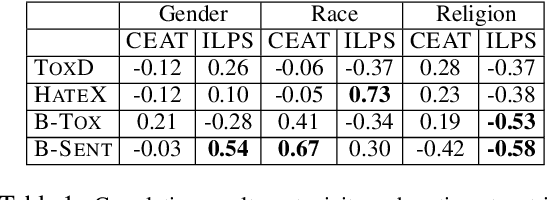
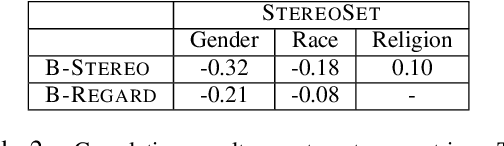
Multiple metrics have been introduced to measure fairness in various natural language processing tasks. These metrics can be roughly categorized into two categories: 1) \emph{extrinsic metrics} for evaluating fairness in downstream applications and 2) \emph{intrinsic metrics} for estimating fairness in upstream contextualized language representation models. In this paper, we conduct an extensive correlation study between intrinsic and extrinsic metrics across bias notions using 19 contextualized language models. We find that intrinsic and extrinsic metrics do not necessarily correlate in their original setting, even when correcting for metric misalignments, noise in evaluation datasets, and confounding factors such as experiment configuration for extrinsic metrics. %al
Mitigating Gender Bias in Distilled Language Models via Counterfactual Role Reversal
Mar 23, 2022

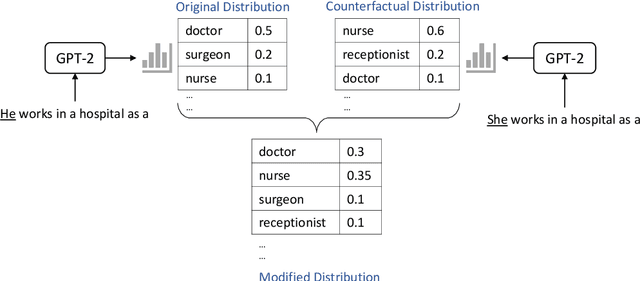
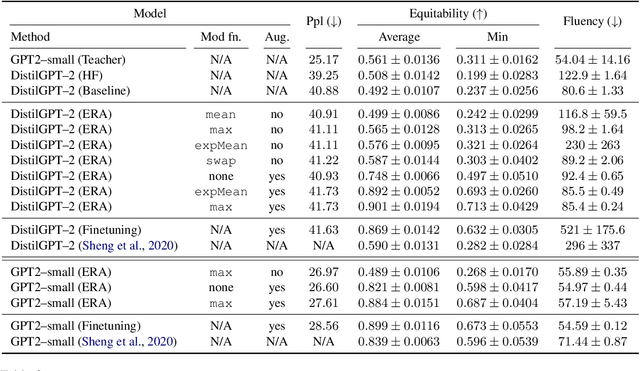
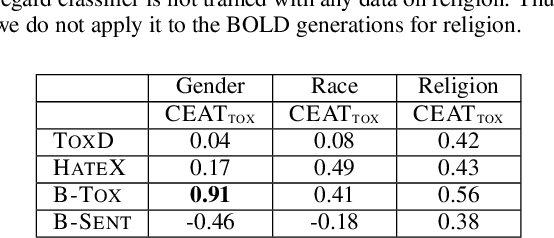
Language models excel at generating coherent text, and model compression techniques such as knowledge distillation have enabled their use in resource-constrained settings. However, these models can be biased in multiple ways, including the unfounded association of male and female genders with gender-neutral professions. Therefore, knowledge distillation without any fairness constraints may preserve or exaggerate the teacher model's biases onto the distilled model. To this end, we present a novel approach to mitigate gender disparity in text generation by learning a fair model during knowledge distillation. We propose two modifications to the base knowledge distillation based on counterfactual role reversal$\unicode{x2014}$modifying teacher probabilities and augmenting the training set. We evaluate gender polarity across professions in open-ended text generated from the resulting distilled and finetuned GPT$\unicode{x2012}$2 models and demonstrate a substantial reduction in gender disparity with only a minor compromise in utility. Finally, we observe that language models that reduce gender polarity in language generation do not improve embedding fairness or downstream classification fairness.
Measuring Fairness of Text Classifiers via Prediction Sensitivity
Mar 16, 2022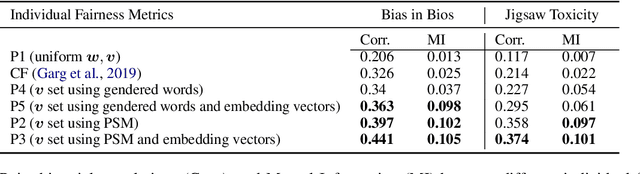

With the rapid growth in language processing applications, fairness has emerged as an important consideration in data-driven solutions. Although various fairness definitions have been explored in the recent literature, there is lack of consensus on which metrics most accurately reflect the fairness of a system. In this work, we propose a new formulation : ACCUMULATED PREDICTION SENSITIVITY, which measures fairness in machine learning models based on the model's prediction sensitivity to perturbations in input features. The metric attempts to quantify the extent to which a single prediction depends on a protected attribute, where the protected attribute encodes the membership status of an individual in a protected group. We show that the metric can be theoretically linked with a specific notion of group fairness (statistical parity) and individual fairness. It also correlates well with humans' perception of fairness. We conduct experiments on two text classification datasets : JIGSAW TOXICITY, and BIAS IN BIOS, and evaluate the correlations between metrics and manual annotations on whether the model produced a fair outcome. We observe that the proposed fairness metric based on prediction sensitivity is statistically significantly more correlated with human annotation than the existing counterfactual fairness metric.