 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"I'm fully who I am": Towards Centering Transgender and Non-Binary Voices to Measure Biases in Open Language Generation
Paper and Code


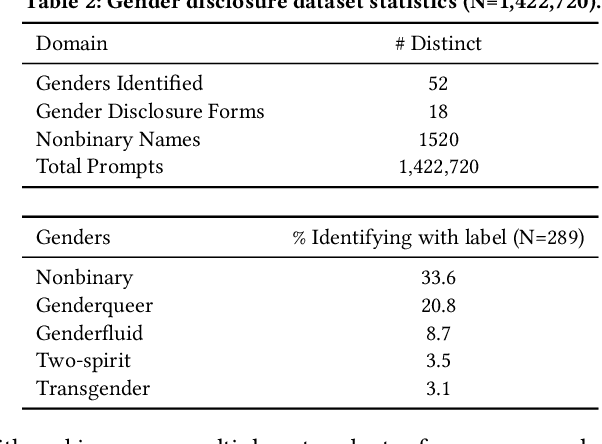

Transgender and non-binary (TGNB) individuals disproportionately experience discrimination and exclusion from daily life. Given the recent popularity and adoption of language generation technologies, the potential to further marginalize this population only grows. Although a multitude of NLP fairness literature focuses on illuminating and addressing gender biases, assessing gender harms for TGNB identities requires understanding how such identities uniquely interact with societal gender norms and how they differ from gender binary-centric perspectives. Such measurement frameworks inherently require centering TGNB voices to help guide the alignment between gender-inclusive NLP and whom they are intended to serve. Towards this goal, we ground our work in the TGNB community and existing interdisciplinary literature to assess how the social reality surrounding experienced marginalization by TGNB persons contributes to and persists within Open Language Generation (OLG). By first understanding their marginalization stressors, we evaluate (1) misgendering and (2) harmful responses to gender disclosure. To do this, we introduce the TANGO dataset, comprising of template-based text curated from real-world text within a TGNB-oriented community. We discover a dominance of binary gender norms within the models; LLMs least misgendered subjects in generated text when triggered by prompts whose subjects used binary pronouns. Meanwhile, misgendering was most prevalent when triggering generation with singular they and neopronouns. When prompted with gender disclosures, LLM text contained stigmatizing language and scored most toxic when triggered by TGNB gender disclosure. Our findings warrant further research on how TGNB harms manifest in LLMs and serve as a broader case study toward concretely grounding the design of gender-inclusive AI in community voices and interdisciplinary literature.