 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Fairness of Text Classifiers via Prediction Sensitivity
Paper and Code
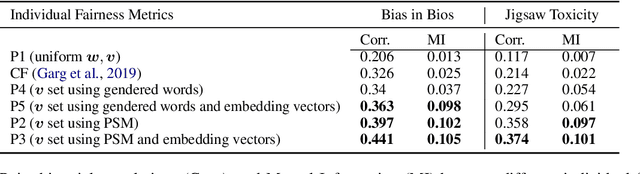

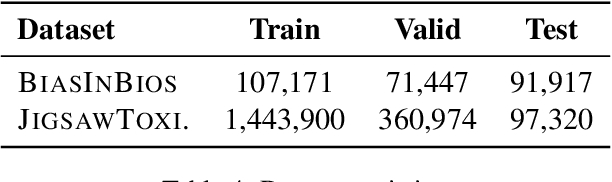
With the rapid growth in language processing applications, fairness has emerged as an important consideration in data-driven solutions. Although various fairness definitions have been explored in the recent literature, there is lack of consensus on which metrics most accurately reflect the fairness of a system. In this work, we propose a new formulation : ACCUMULATED PREDICTION SENSITIVITY, which measures fairness in machine learning models based on the model's prediction sensitivity to perturbations in input features. The metric attempts to quantify the extent to which a single prediction depends on a protected attribute, where the protected attribute encodes the membership status of an individual in a protected group. We show that the metric can be theoretically linked with a specific notion of group fairness (statistical parity) and individual fairness. It also correlates well with humans' perception of fairness. We conduct experiments on two text classification datasets : JIGSAW TOXICITY, and BIAS IN BIOS, and evaluate the correlations between metrics and manual annotations on whether the model produced a fair outcome. We observe that the proposed fairness metric based on prediction sensitivity is statistically significantly more correlated with human annotation than the existing counterfactual fairness metric.