 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoKe: Customizable Fine-Grained Story Evaluation via Chain-of-Keyword Rationalization
Mar 21, 2025Evaluating creative text such as human-written stories using language models has always been a challenging task -- owing to the subjectivity of multi-annotator ratings. To mimic the thinking process of humans, chain of thought (CoT) generates free-text explanations that help guide a model's predictions and Self-Consistency (SC) marginalizes predictions over multiple generated explanations. In this study, we discover that the widely-used self-consistency reasoning methods cause suboptimal results due to an objective mismatch between generating 'fluent-looking' explanations vs. actually leading to a good rating prediction for an aspect of a story. To overcome this challenge, we propose $\textbf{C}$hain-$\textbf{o}$f-$\textbf{Ke}$ywords (CoKe), that generates a sequence of keywords $\textit{before}$ generating a free-text rationale, that guide the rating prediction of our evaluation language model. Then, we generate a diverse set of such keywords, and aggregate the scores corresponding to these generations. On the StoryER dataset, CoKe based on our small fine-tuned evaluation models not only reach human-level performance and significantly outperform GPT-4 with a 2x boost in correlation with human annotators, but also requires drastically less number of parameters.
Unsupervised Syntactically Controlled Paraphrase Generation with Abstract Meaning Representations
Nov 02, 2022



Syntactically controlled paraphrase generation has become an emerging research direction in recent years. Most existing approaches require annotated paraphrase pairs for training and are thus costly to extend to new domains. Unsupervised approaches, on the other hand, do not need paraphrase pairs but suffer from relatively poor performance in terms of syntactic control and quality of generated paraphrases. In this paper, we demonstrate that leveraging Abstract Meaning Representations (AMR) can greatly improve the performance of unsupervised syntactically controlled paraphrase generation. Our proposed model, AMR-enhanced Paraphrase Generator (AMRPG), separately encodes the AMR graph and the constituency parse of the input sentence into two disentangled semantic and syntactic embeddings. A decoder is then learned to reconstruct the input sentence from the semantic and syntactic embeddings. Our experiments show that AMRPG generates more accurate syntactically controlled paraphrases, both quantitatively and qualitatively, compared to the existing unsupervised approaches. We also demonstrate that the paraphrases generated by AMRPG can be used for data augmentation to improve the robustness of NLP models.
Evaluating the Effectiveness of Efficient Neural Architecture Search for Sentence-Pair Tasks
Oct 08, 2020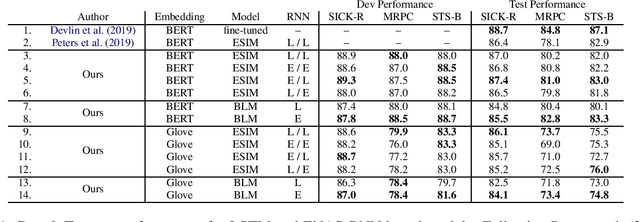
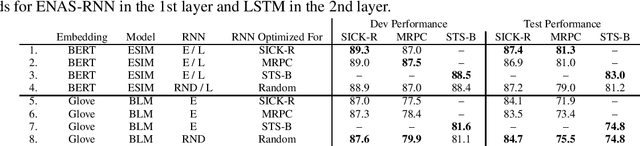

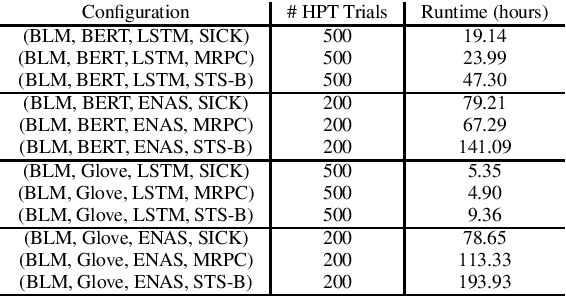
Neural Architecture Search (NAS) methods, which automatically learn entire neural model or individual neural cell architectures, have recently achieved competitive or state-of-the-art (SOTA) performance on variety of natural language processing and computer vision tasks, including language modeling, natural language inference, and image classification. In this work, we explore the applicability of a SOTA NAS algorithm, Efficient Neural Architecture Search (ENAS) (Pham et al., 2018) to two sentence pair tasks, paraphrase detection and semantic textual similarity. We use ENAS to perform a micro-level search and learn a task-optimized RNN cell architecture as a drop-in replacement for an LSTM. We explore the effectiveness of ENAS through experiments on three datasets (MRPC, SICK, STS-B), with two different models (ESIM, BiLSTM-Max), and two sets of embeddings (Glove, BERT). In contrast to prior work applying ENAS to NLP tasks, our results are mixed -- we find that ENAS architectures sometimes, but not always, outperform LSTMs and perform similarly to random architecture search.
Assisting Composition of Email Responses: a Topic Prediction Approach
Oct 07, 2015
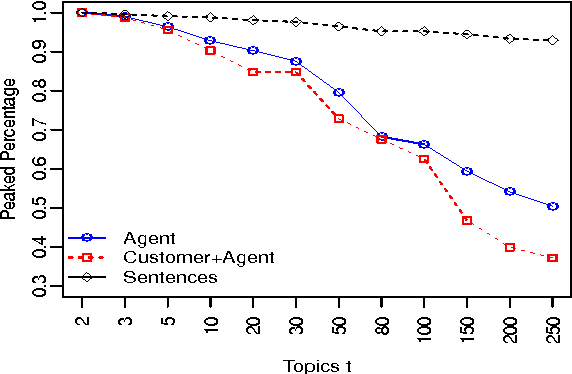


We propose an approach for helping agents compose email replies to customer requests. To enable that, we use LDA to extract latent topics from a collection of email exchanges. We then use these latent topics to label our data, obtaining a so-called "silver standard" topic labelling. We exploit this labelled set to train a classifier to: (i) predict the topic distribution of the entire agent's email response, based on features of the customer's email; and (ii) predict the topic distribution of the next sentence in the agent's reply, based on the customer's email features and on features of the agent's current sentence. The experimental results on a large email collection from a contact center in the tele- com domain show that the proposed ap- proach is effective in predicting the best topic of the agent's next sentence. In 80% of the cases, the correct topic is present among the top five recommended topics (out of fifty possible ones). This shows the potential of this method to be applied in an interactive setting, where the agent is presented a small list of likely topics to choose from for the next sentence.