 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLooP: Zero-Shot Abstractive Summarization using Large Language Models with Bigram Lookahead Promotion
Mar 12, 2026Abstractive summarization requires models to generate summaries that convey information in the source document. While large language models can generate summaries without fine-tuning, they often miss key details and include extraneous information. We propose BLooP (Bigram Lookahead Promotion), a simple training-free decoding intervention that encourages large language models (LLMs) to generate tokens that form bigrams from the source document. BLooP operates through a hash table lookup at each decoding step, requiring no training, fine-tuning, or model modification. We demonstrate improvements in ROUGE and BARTScore for Llama-3.1-8B-Instruct, Mistral-Nemo-Instruct-2407, and Gemma-2-9b-it on CNN/DM, CCSum, Multi-News, and SciTLDR. Human evaluation shows that BLooP significantly improves faithfulness without reducing readability. We make the code available at https://github.com/varuniyer/BLooP
LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models
Aug 20, 2023
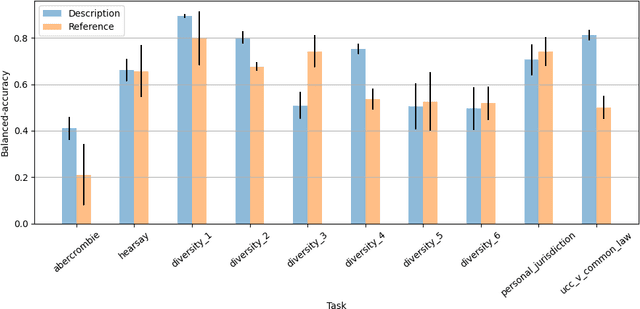
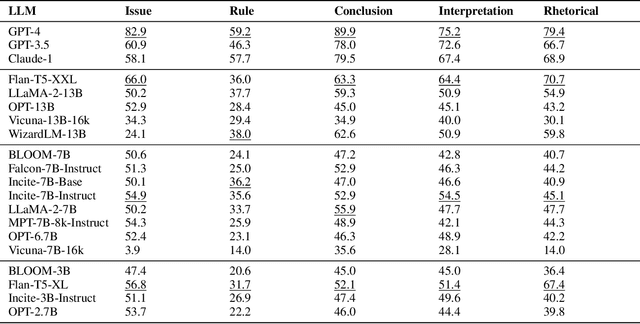
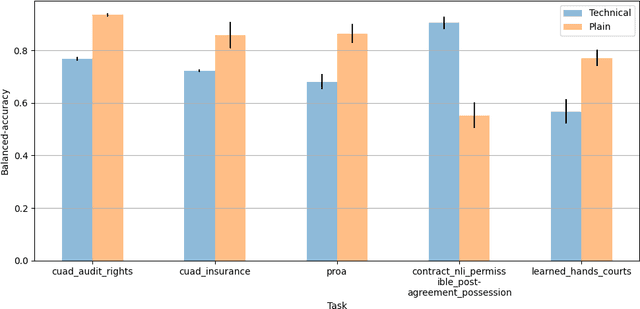
The advent of large language models (LLMs) and their adoption by the legal community has given rise to the question: what types of legal reasoning can LLMs perform? To enable greater study of this question, we present LegalBench: a collaboratively constructed legal reasoning benchmark consisting of 162 tasks covering six different types of legal reasoning. LegalBench was built through an interdisciplinary process, in which we collected tasks designed and hand-crafted by legal professionals. Because these subject matter experts took a leading role in construction, tasks either measure legal reasoning capabilities that are practically useful, or measure reasoning skills that lawyers find interesting. To enable cross-disciplinary conversations about LLMs in the law, we additionally show how popular legal frameworks for describing legal reasoning -- which distinguish between its many forms -- correspond to LegalBench tasks, thus giving lawyers and LLM developers a common vocabulary. This paper describes LegalBench, presents an empirical evaluation of 20 open-source and commercial LLMs, and illustrates the types of research explorations LegalBench enables.
ParaAMR: A Large-Scale Syntactically Diverse Paraphrase Dataset by AMR Back-Translation
May 26, 2023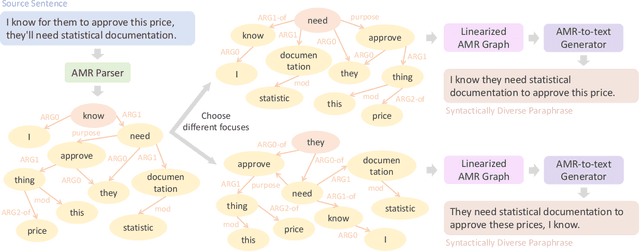
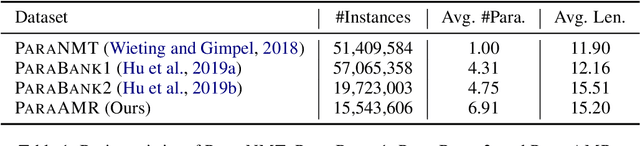
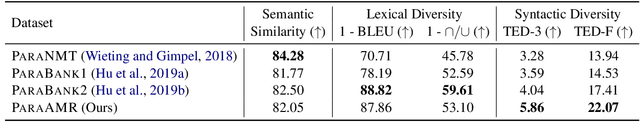

Paraphrase generation is a long-standing task in natural language processing (NLP). Supervised paraphrase generation models, which rely on human-annotated paraphrase pairs, are cost-inefficient and hard to scale up. On the other hand, automatically annotated paraphrase pairs (e.g., by machine back-translation), usually suffer from the lack of syntactic diversity -- the generated paraphrase sentences are very similar to the source sentences in terms of syntax. In this work, we present ParaAMR, a large-scale syntactically diverse paraphrase dataset created by abstract meaning representation back-translation. Our quantitative analysis, qualitative examples, and human evaluation demonstrate that the paraphrases of ParaAMR are syntactically more diverse compared to existing large-scale paraphrase datasets while preserving good semantic similarity. In addition, we show that ParaAMR can be used to improve on three NLP tasks: learning sentence embeddings, syntactically controlled paraphrase generation, and data augmentation for few-shot learning. Our results thus showcase the potential of ParaAMR for improving various NLP applications.
Unsupervised Syntactically Controlled Paraphrase Generation with Abstract Meaning Representations
Nov 02, 2022



Syntactically controlled paraphrase generation has become an emerging research direction in recent years. Most existing approaches require annotated paraphrase pairs for training and are thus costly to extend to new domains. Unsupervised approaches, on the other hand, do not need paraphrase pairs but suffer from relatively poor performance in terms of syntactic control and quality of generated paraphrases. In this paper, we demonstrate that leveraging Abstract Meaning Representations (AMR) can greatly improve the performance of unsupervised syntactically controlled paraphrase generation. Our proposed model, AMR-enhanced Paraphrase Generator (AMRPG), separately encodes the AMR graph and the constituency parse of the input sentence into two disentangled semantic and syntactic embeddings. A decoder is then learned to reconstruct the input sentence from the semantic and syntactic embeddings. Our experiments show that AMRPG generates more accurate syntactically controlled paraphrases, both quantitatively and qualitatively, compared to the existing unsupervised approaches. We also demonstrate that the paraphrases generated by AMRPG can be used for data augmentation to improve the robustness of NLP models.