 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiving deeper into mentee networks
Paper and Code
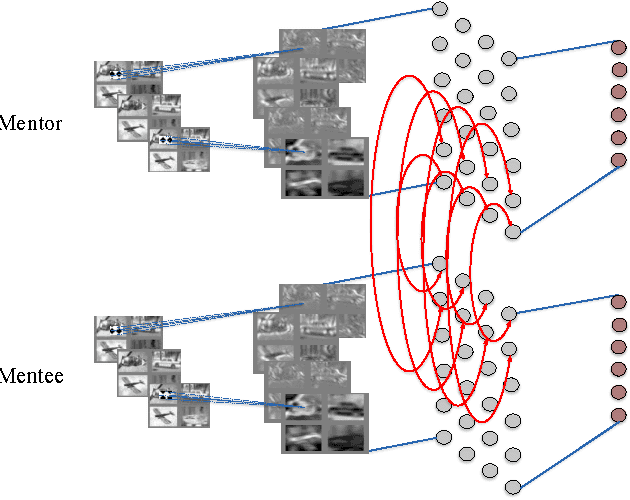


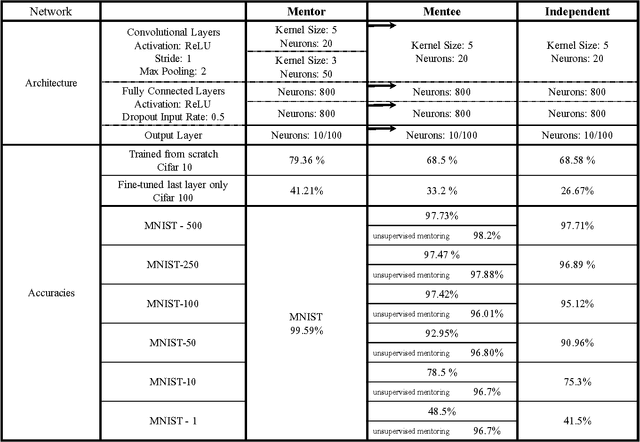
Modern computer vision is all about the possession of powerful image representations. Deeper and deeper convolutional neural networks have been built using larger and larger datasets and are made publicly available. A large swath of computer vision scientists use these pre-trained networks with varying degrees of successes in various tasks. Even though there is tremendous success in copying these networks, the representational space is not learnt from the target dataset in a traditional manner. One of the reasons for opting to use a pre-trained network over a network learnt from scratch is that small datasets provide less supervision and require meticulous regularization, smaller and careful tweaking of learning rates to even achieve stable learning without weight explosion. It is often the case that large deep networks are not portable, which necessitates the ability to learn mid-sized networks from scratch. In this article, we dive deeper into training these mid-sized networks on small datasets from scratch by drawing additional supervision from a large pre-trained network. Such learning also provides better generalization accuracies than networks trained with common regularization techniques such as l2, l1 and dropouts. We show that features learnt thus, are more general than those learnt independently. We studied various characteristics of such networks and found some interesting behaviors.