 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphTransformers for Geospatial Forecasting
Oct 31, 2023


In this paper we introduce a novel framework for trajectory prediction of geospatial sequences using GraphTransformers. When viewed across several sequences, we observed that a graph structure automatically emerges between different geospatial points that is often not taken into account for such sequence modeling tasks. We show that by leveraging this graph structure explicitly, geospatial trajectory prediction can be significantly improved. Our GraphTransformer approach improves upon state-of-the-art Transformer based baseline significantly on HURDAT, a dataset where we are interested in predicting the trajectory of a hurricane on a 6 hourly basis.
Rethinking Few-Shot Object Detection on a Multi-Domain Benchmark
Jul 22, 2022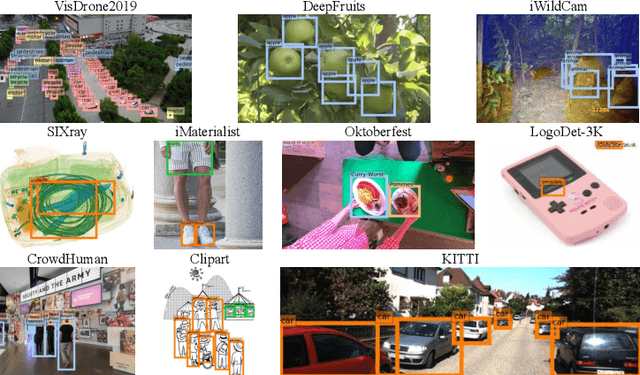
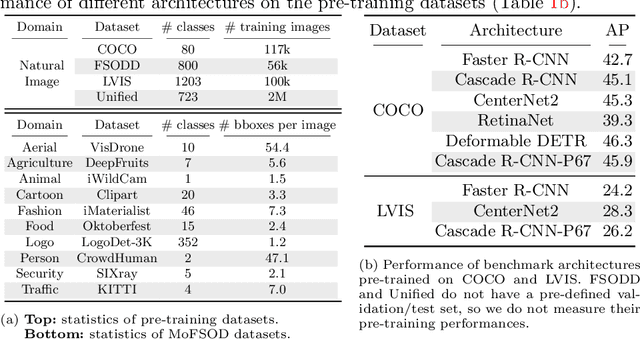
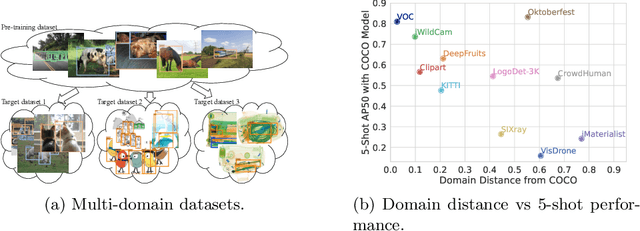
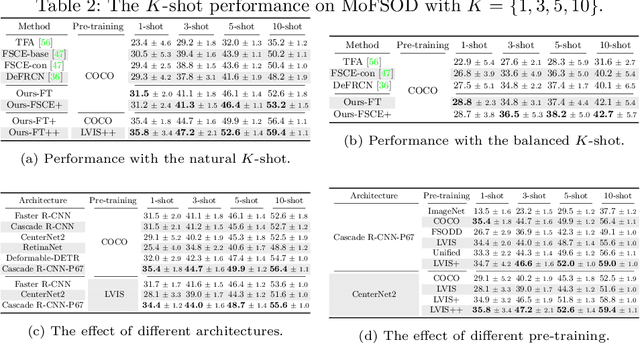
Most existing works on few-shot object detection (FSOD) focus on a setting where both pre-training and few-shot learning datasets are from a similar domain. However, few-shot algorithms are important in multiple domains; hence evaluation needs to reflect the broad applications. We propose a Multi-dOmain Few-Shot Object Detection (MoFSOD) benchmark consisting of 10 datasets from a wide range of domains to evaluate FSOD algorithms. We comprehensively analyze the impacts of freezing layers, different architectures, and different pre-training datasets on FSOD performance. Our empirical results show several key factors that have not been explored in previous works: 1) contrary to previous belief, on a multi-domain benchmark, fine-tuning (FT) is a strong baseline for FSOD, performing on par or better than the state-of-the-art (SOTA) algorithms; 2) utilizing FT as the baseline allows us to explore multiple architectures, and we found them to have a significant impact on down-stream few-shot tasks, even with similar pre-training performances; 3) by decoupling pre-training and few-shot learning, MoFSOD allows us to explore the impact of different pre-training datasets, and the right choice can boost the performance of the down-stream tasks significantly. Based on these findings, we list possible avenues of investigation for improving FSOD performance and propose two simple modifications to existing algorithms that lead to SOTA performance on the MoFSOD benchmark. The code is available at https://github.com/amazon-research/few-shot-object-detection-benchmark.
Learning to Track Object Position through Occlusion
Jun 20, 2021



Occlusion is one of the most significant challenges encountered by object detectors and trackers. While both object detection and tracking has received a lot of attention in the past, most existing methods in this domain do not target detecting or tracking objects when they are occluded. However, being able to detect or track an object of interest through occlusion has been a long standing challenge for different autonomous tasks. Traditional methods that employ visual object trackers with explicit occlusion modeling experience drift and make several fundamental assumptions about the data. We propose to address this with a `tracking-by-detection` approach that builds upon the success of region based video object detectors. Our video level object detector uses a novel recurrent computational unit at its core that enables long term propagation of object features even under occlusion. Finally, we compare our approach with existing state-of-the-art video object detectors and show that our approach achieves superior results on a dataset of furniture assembly videos collected from the internet, where small objects like screws, nuts, and bolts often get occluded from the camera viewpoint.
A more abstractive summarization model
Feb 25, 2020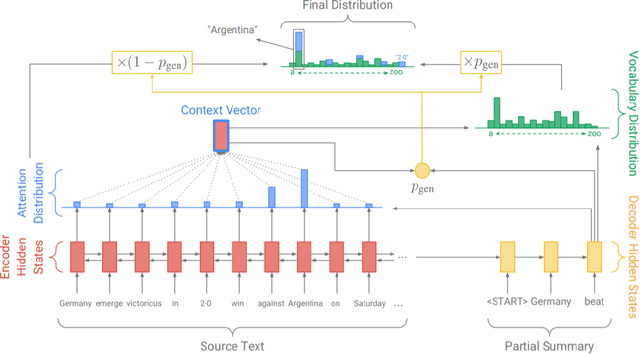
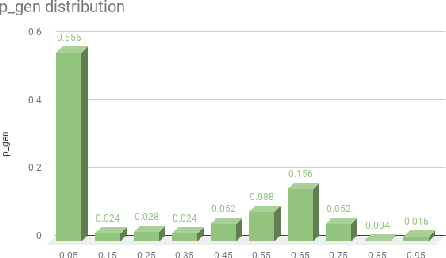
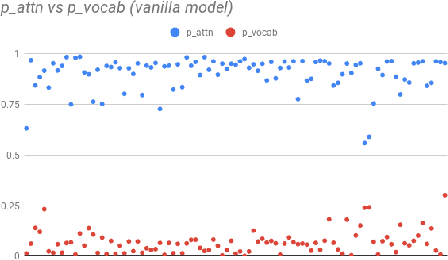
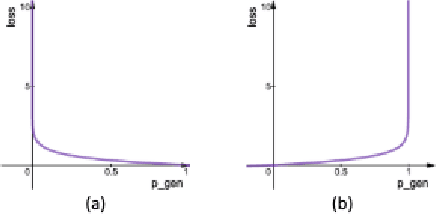
Pointer-generator network is an extremely popular method of text summarization. More recent works in this domain still build on top of the baseline pointer generator by augmenting a content selection phase, or by decomposing the decoder into a contextual network and a language model. However, all such models that are based on the pointer-generator base architecture cannot generate novel words in the summary and mostly copy words from the source text. In our work, we first thoroughly investigate why the pointer-generator network is unable to generate novel words, and then address that by adding an Out-of-vocabulary (OOV) penalty. This enables us to improve the amount of novelty/abstraction significantly. We use normalized n-gram novelty scores as a metric for determining the level of abstraction. Moreover, we also report rouge scores of our model since most summarization models are evaluated with R-1, R-2, R-L scores.