 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-informed Evolutionary Strategy based Control for Mitigating Delayed Voltage Recovery
Nov 29, 2021



In this work we propose a novel data-driven, real-time power system voltage control method based on the physics-informed guided meta evolutionary strategy (ES). The main objective is to quickly provide an adaptive control strategy to mitigate the fault-induced delayed voltage recovery (FIDVR) problem. Reinforcement learning methods have been developed for the same or similar challenging control problems, but they suffer from training inefficiency and lack of robustness for "corner or unseen" scenarios. On the other hand, extensive physical knowledge has been developed in power systems but little has been leveraged in learning-based approaches. To address these challenges, we introduce the trainable action mask technique for flexibly embedding physical knowledge into RL models to rule out unnecessary or unfavorable actions, and achieve notable improvements in sample efficiency, control performance and robustness. Furthermore, our method leverages past learning experience to derive surrogate gradient to guide and accelerate the exploration process in training. Case studies on the IEEE 300-bus system and comparisons with other state-of-the-art benchmark methods demonstrate effectiveness and advantages of our method.
Learning and Fast Adaptation for Grid Emergency Control via Deep Meta Reinforcement Learning
Jan 13, 2021
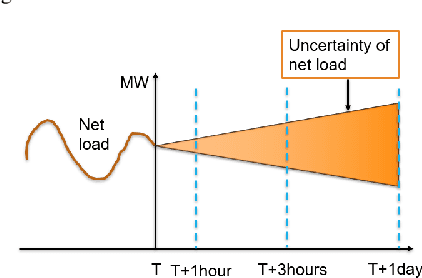
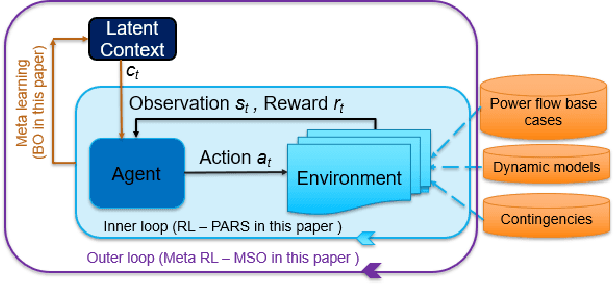
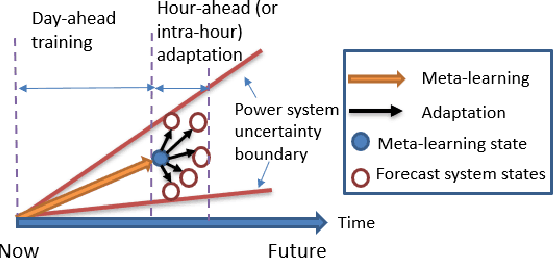
As power systems are undergoing a significant transformation with more uncertainties, less inertia and closer to operation limits, there is increasing risk of large outages. Thus, there is an imperative need to enhance grid emergency control to maintain system reliability and security. Towards this end, great progress has been made in developing deep reinforcement learning (DRL) based grid control solutions in recent years. However, existing DRL-based solutions have two main limitations: 1) they cannot handle well with a wide range of grid operation conditions, system parameters, and contingencies; 2) they generally lack the ability to fast adapt to new grid operation conditions, system parameters, and contingencies, limiting their applicability for real-world applications. In this paper, we mitigate these limitations by developing a novel deep meta reinforcement learning (DMRL) algorithm. The DMRL combines the meta strategy optimization together with DRL, and trains policies modulated by a latent space that can quickly adapt to new scenarios. We test the developed DMRL algorithm on the IEEE 300-bus system. We demonstrate fast adaptation of the meta-trained DRL polices with latent variables to new operating conditions and scenarios using the proposed method and achieve superior performance compared to the state-of-the-art DRL and model predictive control (MPC) methods.
A more abstractive summarization model
Feb 25, 2020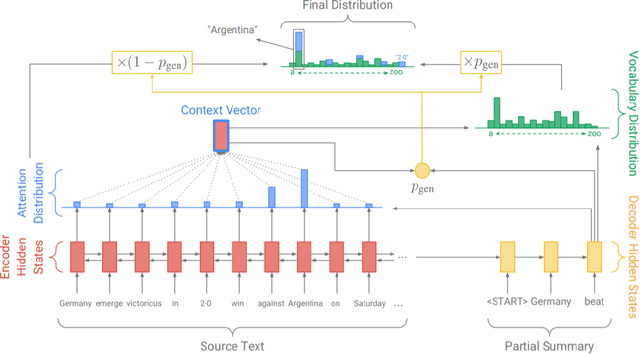
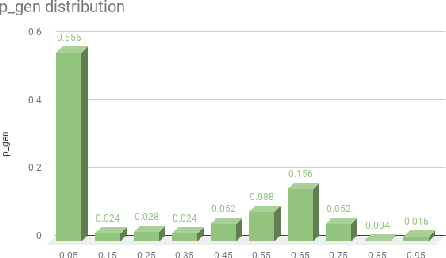
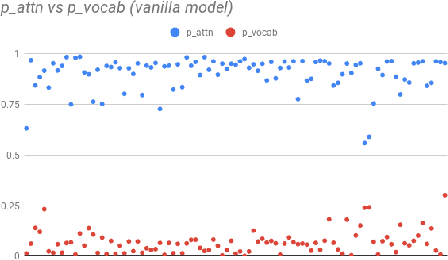
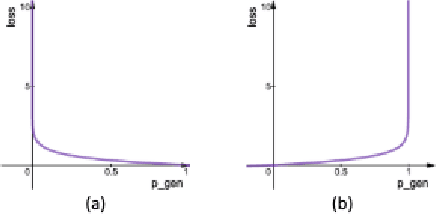
Pointer-generator network is an extremely popular method of text summarization. More recent works in this domain still build on top of the baseline pointer generator by augmenting a content selection phase, or by decomposing the decoder into a contextual network and a language model. However, all such models that are based on the pointer-generator base architecture cannot generate novel words in the summary and mostly copy words from the source text. In our work, we first thoroughly investigate why the pointer-generator network is unable to generate novel words, and then address that by adding an Out-of-vocabulary (OOV) penalty. This enables us to improve the amount of novelty/abstraction significantly. We use normalized n-gram novelty scores as a metric for determining the level of abstraction. Moreover, we also report rouge scores of our model since most summarization models are evaluated with R-1, R-2, R-L scores.