 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust Between AI Agents: Measuring Formation, Breakage, and Recovery, with Implications for Governing Multi-Agent Systems
Jun 12, 2026As language-model agents increasingly work in teams, each agent must decide how much to trust its teammates. Yet we lack a standard way to measure trust between AI agents. We propose a behavioral measure based on costly verification. In a cooperative survival game, checking a teammate's work consumes resources, while trusting a wrong answer can be fatal. Relative to a memoryless version of the same model, reduced verification provides an observable measure of trust. Using this framework, we study trust formation, breakage, and recovery across six frontier model snapshots. When paired with a consistently reliable teammate, four snapshots (Claude Opus 4.6, Claude Sonnet 4.6, GPT-5.1, and Gemini 3.1 Pro) reduce verification by roughly 60-85%, whereas two smaller snapshots show little or no such adjustment. Failures reverse this discount, but models differ in how they respond. Some concentrate renewed scrutiny on the culprit, while others become more cautious toward the entire team. Recovery is slower than formation, and clustered failures sustain suspicion far longer than the same number of failures spread apart. These differences have practical consequences. Models that form trust verify less, decide more quickly, and achieve higher payoffs in our environment. By contrast, persistent over-verification is associated with indecision rather than safety. Our results show that trust dispositions can be measured before deployment and suggest that calibration, rather than maximal suspicion, should be the central concern in the governance of multi-agent AI systems.
Prospect-Theory Behavior from Bellman Optimality in MDPs with Catastrophic States
May 31, 2026We study risk-neutral control in Markov decision processes with an absorbing catastrophic state. Even though rewards are linear and the agent has no utility curvature, probability weighting, or framing dependence, standard Bellman optimality produces three prospect-theory-like signatures: an S-shaped value-function profile (convex near catastrophe, concave in the far field), an endogenous loss-sensitivity coefficient $λ^*(S) > 1$, and a reflection-effect policy reversal. Across 495 configurations, the optimal policy plays safe near catastrophe in positive-drift (growth) regimes despite the risky action's higher immediate expected value, and plays risky near catastrophe in negative-drift (decline) regimes despite the safe action's lower immediate expected loss. We derive a closed-form expression for the asymptotic loss-aversion plateau $\barλ$ that depends only on win probability $p$, payoff asymmetry $r = |Δ_\ell/Δ_w|$, and discount factor $β$, and matches numerical solutions to $R^2 = 0.999$. The mechanism does not require asymmetric payoffs. Across a sweep of $(p,β)$ at three asymmetry levels, the asymmetry share of $\barλ$ above unity has median 4.6% at $r = 1.25$ and rises to 13.9% at $r = 2$, with the boundary contribution exceeding the asymmetry contribution in every cell tested. The phenomena persist under tabular Q-learning (a model-free agent reproduces $V^*$ at correlation 0.98 in growth and 1.00 in decline) and under stochastic transitions with Gaussian, heavy-tailed Student-$t_3$, and asymmetric skew-normal noise up to 50% of the step size, where the asymptotic plateau tracks the closed-form prediction within 0.41% for safe-channel noise and within 9.6% for risky-channel or both-channel noise. These results identify absorbing failure states as a sufficient structural mechanism for prospect-theory-like behavior under optimal control.
Estimating electricity saving-potential in small offices using adaptive thermal comfort
May 12, 2022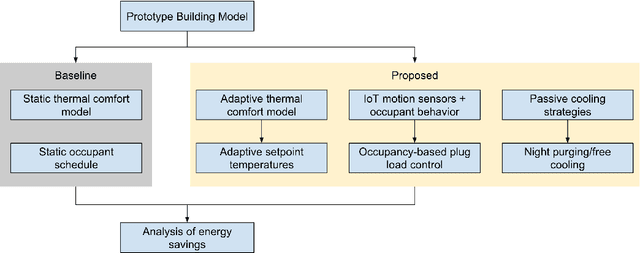
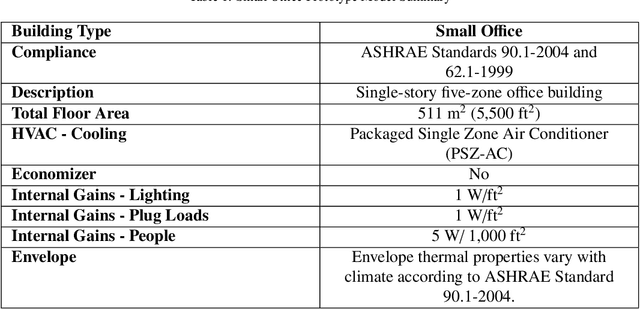
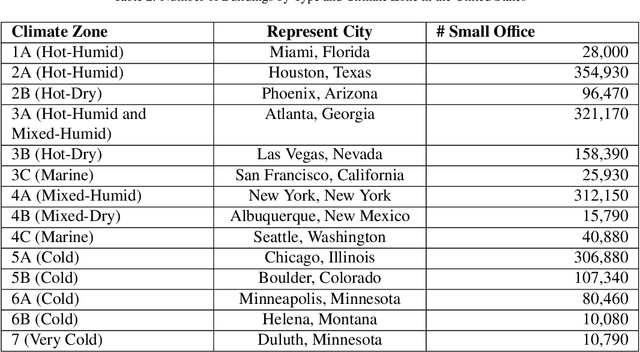
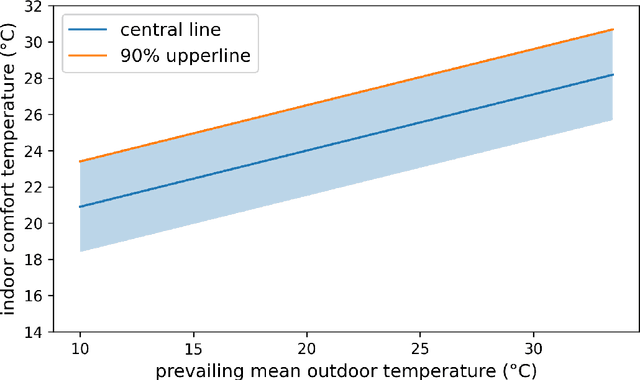
The smart control informed by IoT sensors and enabled by remotely controlled devices can optimize the building operation to minimize unnecessary energy consumption and improve indoor thermal comfort. This paper quantifies the potential for electricity savings in small office buildings from smart thermostat control and occupancy-informed smart plug control. This is done by simulating the effect of adaptive setpoint temperature, occupancy-based HVAC control, and night-purge free cooling on small office buildings across all major climate zones in the United States. Adopting these smart control measures can achieve 8.9% to 20.4% of savings in total electricity consumption of small office buildings, or equivalent to annual reductions between 12.2 kWh/m2 and 30.4 kWh/m2 in electricity usage intensity. Among all climate zones, the hot and dry climates benefit the most from proposed smart controls and achieve the highest percentages of electricity savings
Learning and Fast Adaptation for Grid Emergency Control via Deep Meta Reinforcement Learning
Jan 13, 2021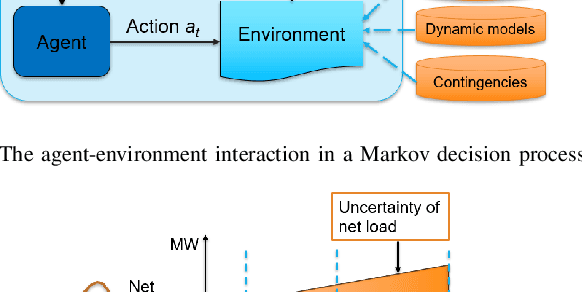
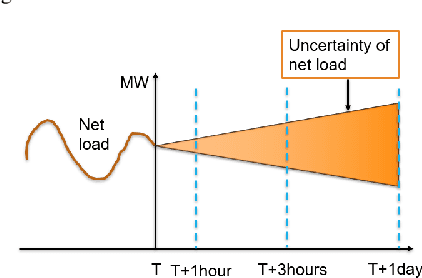
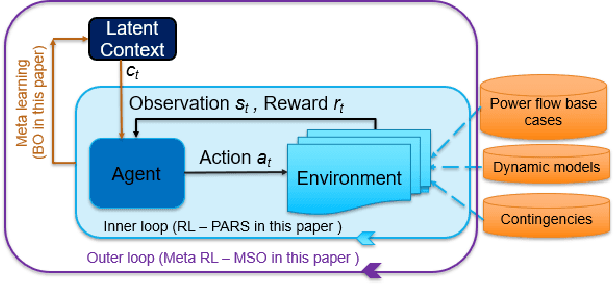
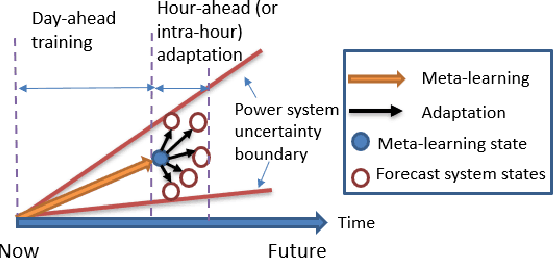
As power systems are undergoing a significant transformation with more uncertainties, less inertia and closer to operation limits, there is increasing risk of large outages. Thus, there is an imperative need to enhance grid emergency control to maintain system reliability and security. Towards this end, great progress has been made in developing deep reinforcement learning (DRL) based grid control solutions in recent years. However, existing DRL-based solutions have two main limitations: 1) they cannot handle well with a wide range of grid operation conditions, system parameters, and contingencies; 2) they generally lack the ability to fast adapt to new grid operation conditions, system parameters, and contingencies, limiting their applicability for real-world applications. In this paper, we mitigate these limitations by developing a novel deep meta reinforcement learning (DMRL) algorithm. The DMRL combines the meta strategy optimization together with DRL, and trains policies modulated by a latent space that can quickly adapt to new scenarios. We test the developed DMRL algorithm on the IEEE 300-bus system. We demonstrate fast adaptation of the meta-trained DRL polices with latent variables to new operating conditions and scenarios using the proposed method and achieve superior performance compared to the state-of-the-art DRL and model predictive control (MPC) methods.