 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Study of Data Modalities and Strategies for Co-training Large Behavior Models for Robot Manipulation
Feb 01, 2026Large behavior models have shown strong dexterous manipulation capabilities by extending imitation learning to large-scale training on multi-task robot data, yet their generalization remains limited by the insufficient robot data coverage. To expand this coverage without costly additional data collection, recent work relies on co-training: jointly learning from target robot data and heterogeneous data modalities. However, how different co-training data modalities and strategies affect policy performance remains poorly understood. We present a large-scale empirical study examining five co-training data modalities: standard vision-language data, dense language annotations for robot trajectories, cross-embodiment robot data, human videos, and discrete robot action tokens across single- and multi-phase training strategies. Our study leverages 4,000 hours of robot and human manipulation data and 50M vision-language samples to train vision-language-action policies. We evaluate 89 policies over 58,000 simulation rollouts and 2,835 real-world rollouts. Our results show that co-training with forms of vision-language and cross-embodiment robot data substantially improves generalization to distribution shifts, unseen tasks, and language following, while discrete action token variants yield no significant benefits. Combining effective modalities produces cumulative gains and enables rapid adaptation to unseen long-horizon dexterous tasks via fine-tuning. Training exclusively on robot data degrades the visiolinguistic understanding of the vision-language model backbone, while co-training with effective modalities restores these capabilities. Explicitly conditioning action generation on chain-of-thought traces learned from co-training data does not improve performance in our simulation benchmark. Together, these results provide practical guidance for building scalable generalist robot policies.
OneTwoVLA: A Unified Vision-Language-Action Model with Adaptive Reasoning
May 17, 2025General-purpose robots capable of performing diverse tasks require synergistic reasoning and acting capabilities. However, recent dual-system approaches, which separate high-level reasoning from low-level acting, often suffer from challenges such as limited mutual understanding of capabilities between systems and latency issues. This paper introduces OneTwoVLA, a single unified vision-language-action model that can perform both acting (System One) and reasoning (System Two). Crucially, OneTwoVLA adaptively switches between two modes: explicitly reasoning at critical moments during task execution, and generating actions based on the most recent reasoning at other times. To further unlock OneTwoVLA's reasoning and generalization capabilities, we design a scalable pipeline for synthesizing embodied reasoning-centric vision-language data, used for co-training with robot data. We validate OneTwoVLA's effectiveness through extensive experiments, highlighting its superior performance across four key capabilities: long-horizon task planning, error detection and recovery, natural human-robot interaction, and generalizable visual grounding, enabling the model to perform long-horizon, highly dexterous manipulation tasks such as making hotpot or mixing cocktails.
HuB: Learning Extreme Humanoid Balance
May 12, 2025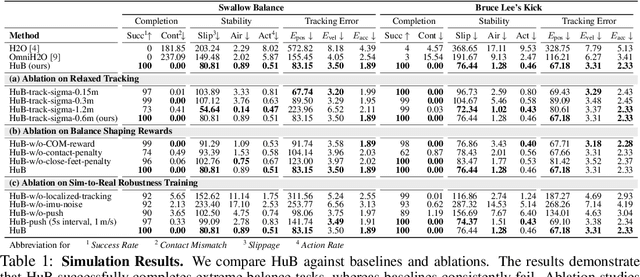
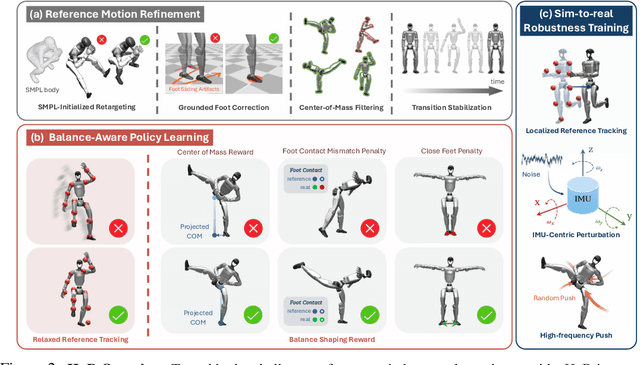
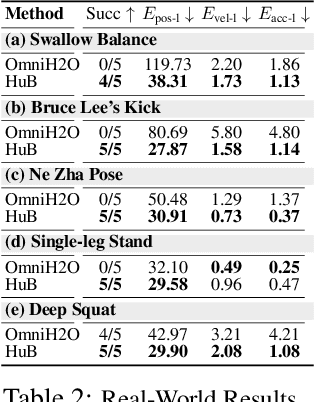
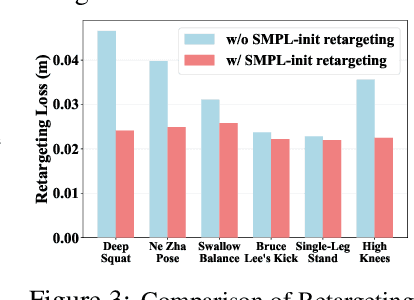
The human body demonstrates exceptional motor capabilities-such as standing steadily on one foot or performing a high kick with the leg raised over 1.5 meters-both requiring precise balance control. While recent research on humanoid control has leveraged reinforcement learning to track human motions for skill acquisition, applying this paradigm to balance-intensive tasks remains challenging. In this work, we identify three key obstacles: instability from reference motion errors, learning difficulties due to morphological mismatch, and the sim-to-real gap caused by sensor noise and unmodeled dynamics. To address these challenges, we propose HuB (Humanoid Balance), a unified framework that integrates reference motion refinement, balance-aware policy learning, and sim-to-real robustness training, with each component targeting a specific challenge. We validate our approach on the Unitree G1 humanoid robot across challenging quasi-static balance tasks, including extreme single-legged poses such as Swallow Balance and Bruce Lee's Kick. Our policy remains stable even under strong physical disturbances-such as a forceful soccer strike-while baseline methods consistently fail to complete these tasks. Project website: https://hub-robot.github.io
Data Scaling Laws in Imitation Learning for Robotic Manipulation
Oct 24, 2024Data scaling has revolutionized fields like natural language processing and computer vision, providing models with remarkable generalization capabilities. In this paper, we investigate whether similar data scaling laws exist in robotics, particularly in robotic manipulation, and whether appropriate data scaling can yield single-task robot policies that can be deployed zero-shot for any object within the same category in any environment. To this end, we conduct a comprehensive empirical study on data scaling in imitation learning. By collecting data across numerous environments and objects, we study how a policy's generalization performance changes with the number of training environments, objects, and demonstrations. Throughout our research, we collect over 40,000 demonstrations and execute more than 15,000 real-world robot rollouts under a rigorous evaluation protocol. Our findings reveal several intriguing results: the generalization performance of the policy follows a roughly power-law relationship with the number of environments and objects. The diversity of environments and objects is far more important than the absolute number of demonstrations; once the number of demonstrations per environment or object reaches a certain threshold, additional demonstrations have minimal effect. Based on these insights, we propose an efficient data collection strategy. With four data collectors working for one afternoon, we collect sufficient data to enable the policies for two tasks to achieve approximately 90% success rates in novel environments with unseen objects.
CoPa: General Robotic Manipulation through Spatial Constraints of Parts with Foundation Models
Mar 13, 2024



Foundation models pre-trained on web-scale data are shown to encapsulate extensive world knowledge beneficial for robotic manipulation in the form of task planning. However, the actual physical implementation of these plans often relies on task-specific learning methods, which require significant data collection and struggle with generalizability. In this work, we introduce Robotic Manipulation through Spatial Constraints of Parts (CoPa), a novel framework that leverages the common sense knowledge embedded within foundation models to generate a sequence of 6-DoF end-effector poses for open-world robotic manipulation. Specifically, we decompose the manipulation process into two phases: task-oriented grasping and task-aware motion planning. In the task-oriented grasping phase, we employ foundation vision-language models (VLMs) to select the object's grasping part through a novel coarse-to-fine grounding mechanism. During the task-aware motion planning phase, VLMs are utilized again to identify the spatial geometry constraints of task-relevant object parts, which are then used to derive post-grasp poses. We also demonstrate how CoPa can be seamlessly integrated with existing robotic planning algorithms to accomplish complex, long-horizon tasks. Our comprehensive real-world experiments show that CoPa possesses a fine-grained physical understanding of scenes, capable of handling open-set instructions and objects with minimal prompt engineering and without additional training. Project page: https://copa-2024.github.io/
Look Before You Leap: Unveiling the Power of GPT-4V in Robotic Vision-Language Planning
Nov 29, 2023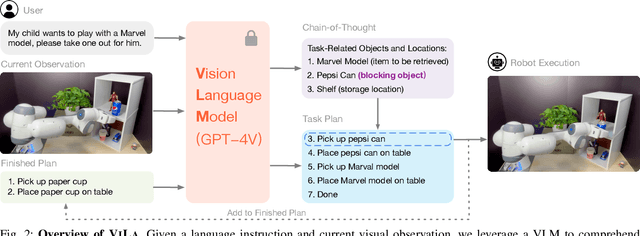

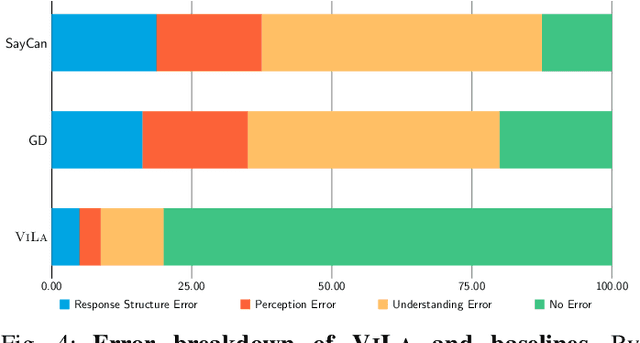

In this study, we are interested in imbuing robots with the capability of physically-grounded task planning. Recent advancements have shown that large language models (LLMs) possess extensive knowledge useful in robotic tasks, especially in reasoning and planning. However, LLMs are constrained by their lack of world grounding and dependence on external affordance models to perceive environmental information, which cannot jointly reason with LLMs. We argue that a task planner should be an inherently grounded, unified multimodal system. To this end, we introduce Robotic Vision-Language Planning (ViLa), a novel approach for long-horizon robotic planning that leverages vision-language models (VLMs) to generate a sequence of actionable steps. ViLa directly integrates perceptual data into its reasoning and planning process, enabling a profound understanding of commonsense knowledge in the visual world, including spatial layouts and object attributes. It also supports flexible multimodal goal specification and naturally incorporates visual feedback. Our extensive evaluation, conducted in both real-robot and simulated environments, demonstrates ViLa's superiority over existing LLM-based planners, highlighting its effectiveness in a wide array of open-world manipulation tasks.
Diverse Policies Converge in Reward-free Markov Decision Processe
Aug 23, 2023


Reinforcement learning has achieved great success in many decision-making tasks, and traditional reinforcement learning algorithms are mainly designed for obtaining a single optimal solution. However, recent works show the importance of developing diverse policies, which makes it an emerging research topic. Despite the variety of diversity reinforcement learning algorithms that have emerged, none of them theoretically answer the question of how the algorithm converges and how efficient the algorithm is. In this paper, we provide a unified diversity reinforcement learning framework and investigate the convergence of training diverse policies. Under such a framework, we also propose a provably efficient diversity reinforcement learning algorithm. Finally, we verify the effectiveness of our method through numerical experiments.
TiZero: Mastering Multi-Agent Football with Curriculum Learning and Self-Play
Feb 21, 2023

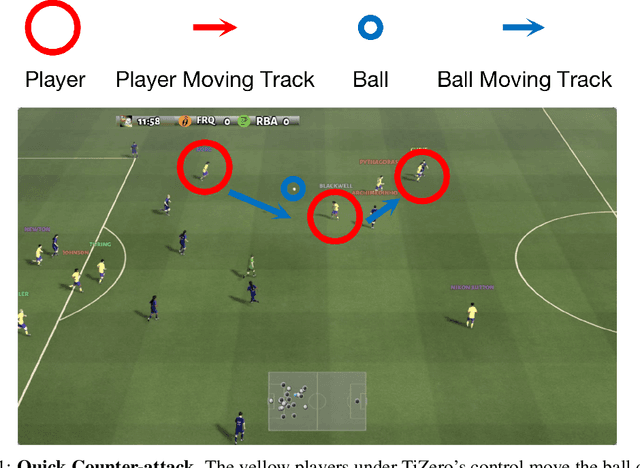

Multi-agent football poses an unsolved challenge in AI research. Existing work has focused on tackling simplified scenarios of the game, or else leveraging expert demonstrations. In this paper, we develop a multi-agent system to play the full 11 vs. 11 game mode, without demonstrations. This game mode contains aspects that present major challenges to modern reinforcement learning algorithms; multi-agent coordination, long-term planning, and non-transitivity. To address these challenges, we present TiZero; a self-evolving, multi-agent system that learns from scratch. TiZero introduces several innovations, including adaptive curriculum learning, a novel self-play strategy, and an objective that optimizes the policies of multiple agents jointly. Experimentally, it outperforms previous systems by a large margin on the Google Research Football environment, increasing win rates by over 30%. To demonstrate the generality of TiZero's innovations, they are assessed on several environments beyond football; Overcooked, Multi-agent Particle-Environment, Tic-Tac-Toe and Connect-Four.