 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Policies Converge in Reward-free Markov Decision Processe
Aug 23, 2023


Reinforcement learning has achieved great success in many decision-making tasks, and traditional reinforcement learning algorithms are mainly designed for obtaining a single optimal solution. However, recent works show the importance of developing diverse policies, which makes it an emerging research topic. Despite the variety of diversity reinforcement learning algorithms that have emerged, none of them theoretically answer the question of how the algorithm converges and how efficient the algorithm is. In this paper, we provide a unified diversity reinforcement learning framework and investigate the convergence of training diverse policies. Under such a framework, we also propose a provably efficient diversity reinforcement learning algorithm. Finally, we verify the effectiveness of our method through numerical experiments.
Automated 3D Pre-Training for Molecular Property Prediction
Jul 02, 2023Molecular property prediction is an important problem in drug discovery and materials science. As geometric structures have been demonstrated necessary for molecular property prediction, 3D information has been combined with various graph learning methods to boost prediction performance. However, obtaining the geometric structure of molecules is not feasible in many real-world applications due to the high computational cost. In this work, we propose a novel 3D pre-training framework (dubbed 3D PGT), which pre-trains a model on 3D molecular graphs, and then fine-tunes it on molecular graphs without 3D structures. Based on fact that bond length, bond angle, and dihedral angle are three basic geometric descriptors corresponding to a complete molecular 3D conformer, we first develop a multi-task generative pre-train framework based on these three attributes. Next, to automatically fuse these three generative tasks, we design a surrogate metric using the \textit{total energy} to search for weight distribution of the three pretext task since total energy corresponding to the quality of 3D conformer.Extensive experiments on 2D molecular graphs are conducted to demonstrate the accuracy, efficiency and generalization ability of the proposed 3D PGT compared to various pre-training baselines.
TabGNN: Multiplex Graph Neural Network for Tabular Data Prediction
Aug 20, 2021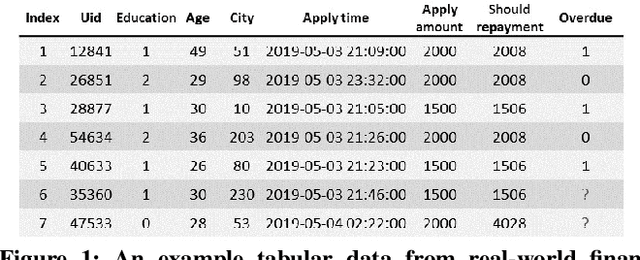

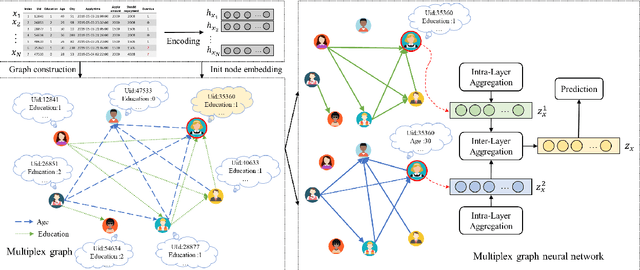
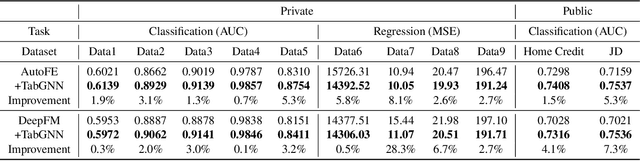
Tabular data prediction (TDP) is one of the most popular industrial applications, and various methods have been designed to improve the prediction performance. However, existing works mainly focus on feature interactions and ignore sample relations, e.g., users with the same education level might have a similar ability to repay the debt. In this work, by explicitly and systematically modeling sample relations, we propose a novel framework TabGNN based on recently popular graph neural networks (GNN). Specifically, we firstly construct a multiplex graph to model the multifaceted sample relations, and then design a multiplex graph neural network to learn enhanced representation for each sample. To integrate TabGNN with the tabular solution in our company, we concatenate the learned embeddings and the original ones, which are then fed to prediction models inside the solution. Experiments on eleven TDP datasets from various domains, including classification and regression ones, show that TabGNN can consistently improve the performance compared to the tabular solution AutoFE in 4Paradigm.
Search to aggregate neighborhood for graph neural network
Apr 20, 2021


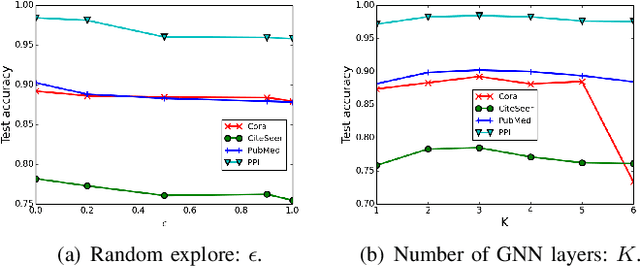
Recent years have witnessed the popularity and success of graph neural networks (GNN) in various scenarios. To obtain data-specific GNN architectures, researchers turn to neural architecture search (NAS), which has made impressive success in discovering effective architectures in convolutional neural networks. However, it is non-trivial to apply NAS approaches to GNN due to challenges in search space design and the expensive searching cost of existing NAS methods. In this work, to obtain the data-specific GNN architectures and address the computational challenges facing by NAS approaches, we propose a framework, which tries to Search to Aggregate NEighborhood (SANE), to automatically design data-specific GNN architectures. By designing a novel and expressive search space, we propose a differentiable search algorithm, which is more efficient than previous reinforcement learning based methods. Experimental results on four tasks and seven real-world datasets demonstrate the superiority of SANE compared to existing GNN models and NAS approaches in terms of effectiveness and efficiency. (Code is available at: https://github.com/AutoML-4Paradigm/SANE).
Network On Network for Tabular Data Classification in Real-world Applications
May 29, 2020
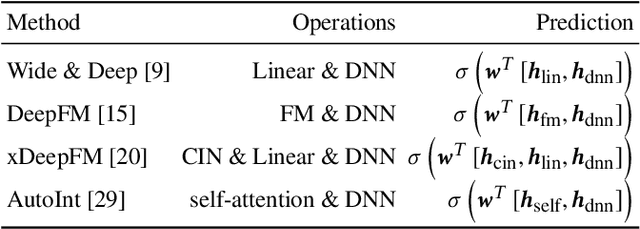
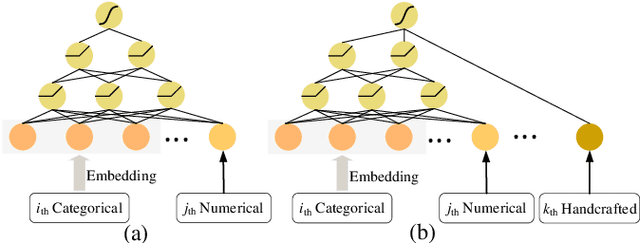
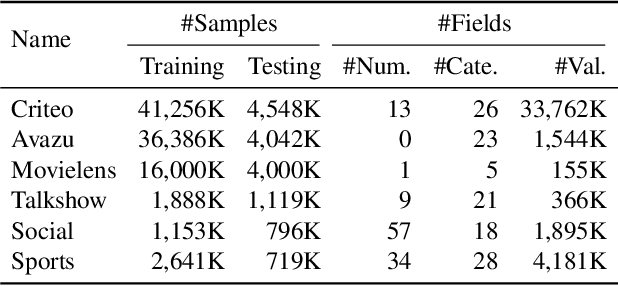
Tabular data is the most common data format adopted by our customers ranging from retail, finance to E-commerce, and tabular data classification plays an essential role to their businesses. In this paper, we present Network On Network (NON), a practical tabular data classification model based on deep neural network to provide accurate predictions. Various deep methods have been proposed and promising progress has been made. However, most of them use operations like neural network and factorization machines to fuse the embeddings of different features directly, and linearly combine the outputs of those operations to get the final prediction. As a result, the intra-field information and the non-linear interactions between those operations (e.g. neural network and factorization machines) are ignored. Intra-field information is the information that features inside each field belong to the same field. NON is proposed to take full advantage of intra-field information and non-linear interactions. It consists of three components: field-wise network at the bottom to capture the intra-field information, across field network in the middle to choose suitable operations data-drivenly, and operation fusion network on the top to fuse outputs of the chosen operations deeply. Extensive experiments on six real-world datasets demonstrate NON can outperform the state-of-the-art models significantly. Furthermore, both qualitative and quantitative study of the features in the embedding space show NON can capture intra-field information effectively.
SAdam: A Variant of Adam for Strongly Convex Functions
May 08, 2019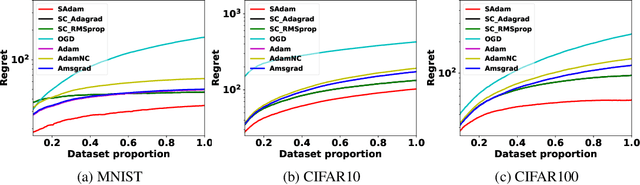
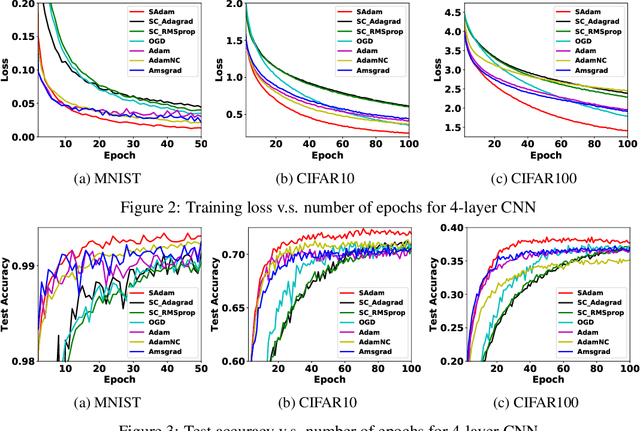
The Adam algorithm has become extremely popular for large-scale machine learning. Under convexity condition, it has been proved to enjoy a data-dependant $O(\sqrt{T})$ regret bound where $T$ is the time horizon. However, whether strong convexity can be utilized to further improve the performance remains an open problem. In this paper, we give an affirmative answer by developing a variant of Adam (referred to as SAdam) which achieves a data-dependant $O(\log T)$ regret bound for strongly convex functions. The essential idea is to maintain a faster decaying yet under controlled step size for exploiting strong convexity. In addition, under a special configuration of hyperparameters, our SAdam reduces to SC-RMSprop, a recently proposed variant of RMSprop for strongly convex functions, for which we provide the first data-dependent logarithmic regret bound. Empirical results on optimizing strongly convex functions and training deep networks demonstrate the effectiveness of our method.
Scalable Tensor Completion with Nonconvex Regularization
Sep 05, 2018
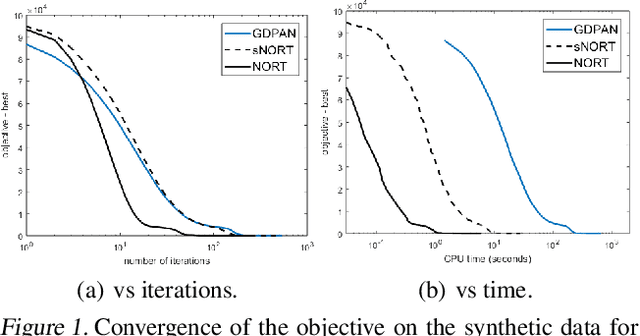
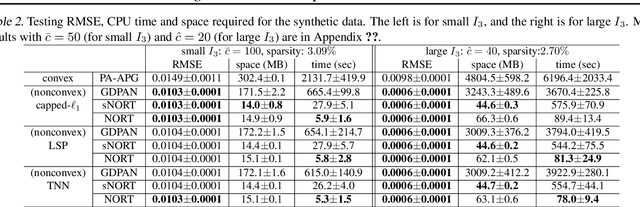
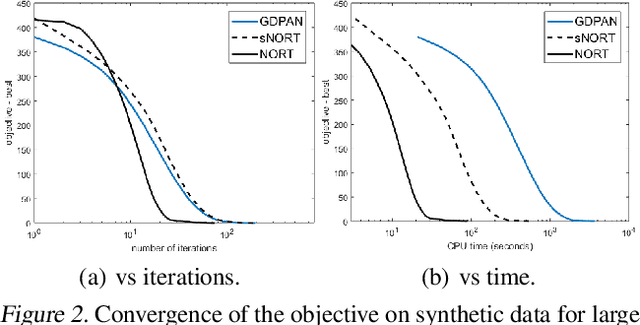
Low-rank tensor completion problem aims to recover a tensor from limited observations, which has many real-world applications. Due to the easy optimization, the convex overlapping nuclear norm has been popularly used for tensor completion. However, it over-penalizes top singular values and lead to biased estimations. In this paper, we propose to use the nonconvex regularizer, which can less penalize large singular values, instead of the convex one for tensor completion. However, as the new regularizer is nonconvex and overlapped with each other, existing algorithms are either too slow or suffer from the huge memory cost. To address these issues, we develop an efficient and scalable algorithm, which is based on the proximal average (PA) algorithm, for real-world problems. Compared with the direct usage of PA algorithm, the proposed algorithm runs orders faster and needs orders less space. We further speed up the proposed algorithm with the acceleration technique, and show the convergence to critical points is still guaranteed. Experimental comparisons of the proposed approach are made with various other tensor completion approaches. Empirical results show that the proposed algorithm is very fast and can produce much better recovery performance.