 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlleviating Video-Length Effect for Micro-video Recommendation
Aug 31, 2023

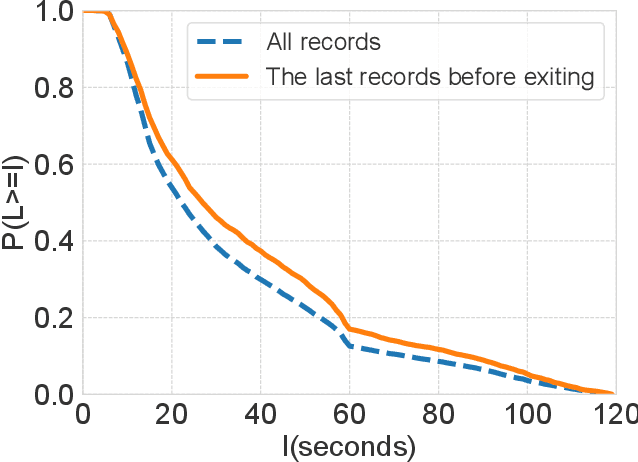
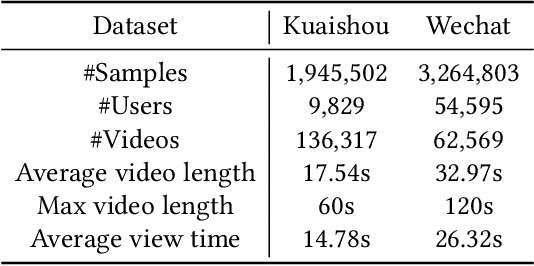
Micro-videos platforms such as TikTok are extremely popular nowadays. One important feature is that users no longer select interested videos from a set, instead they either watch the recommended video or skip to the next one. As a result, the time length of users' watching behavior becomes the most important signal for identifying preferences. However, our empirical data analysis has shown a video-length effect that long videos are easier to receive a higher value of average view time, thus adopting such view-time labels for measuring user preferences can easily induce a biased model that favors the longer videos. In this paper, we propose a Video Length Debiasing Recommendation (VLDRec) method to alleviate such an effect for micro-video recommendation. VLDRec designs the data labeling approach and the sample generation module that better capture user preferences in a view-time oriented manner. It further leverages the multi-task learning technique to jointly optimize the above samples with original biased ones. Extensive experiments show that VLDRec can improve the users' view time by 1.81% and 11.32% on two real-world datasets, given a recommendation list of a fixed overall video length, compared with the best baseline method. Moreover, VLDRec is also more effective in matching users' interests in terms of the video content.
Robust Preference-Guided Denoising for Graph based Social Recommendation
Mar 15, 2023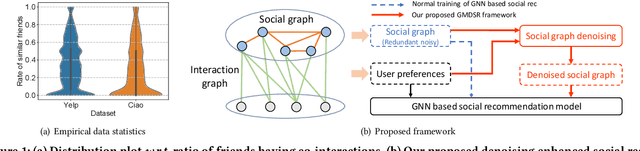

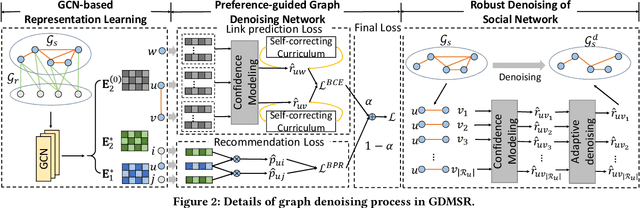
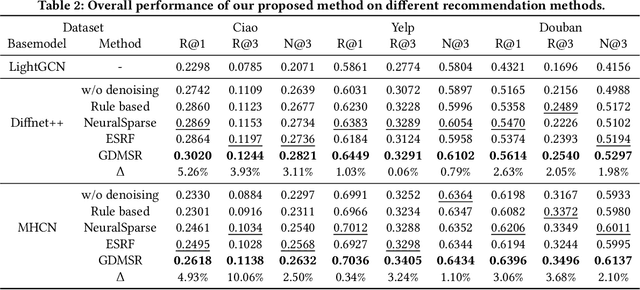
Graph Neural Network(GNN) based social recommendation models improve the prediction accuracy of user preference by leveraging GNN in exploiting preference similarity contained in social relations. However, in terms of both effectiveness and efficiency of recommendation, a large portion of social relations can be redundant or even noisy, e.g., it is quite normal that friends share no preference in a certain domain. Existing models do not fully solve this problem of relation redundancy and noise, as they directly characterize social influence over the full social network. In this paper, we instead propose to improve graph based social recommendation by only retaining the informative social relations to ensure an efficient and effective influence diffusion, i.e., graph denoising. Our designed denoising method is preference-guided to model social relation confidence and benefits user preference learning in return by providing a denoised but more informative social graph for recommendation models. Moreover, to avoid interference of noisy social relations, it designs a self-correcting curriculum learning module and an adaptive denoising strategy, both favoring highly-confident samples. Experimental results on three public datasets demonstrate its consistent capability of improving two state-of-the-art social recommendation models by robustly removing 10-40% of original relations. We release the source code at https://github.com/tsinghua-fib-lab/Graph-Denoising-SocialRec.
Graph Neural Networks for Recommender Systems: Challenges, Methods, and Directions
Sep 27, 2021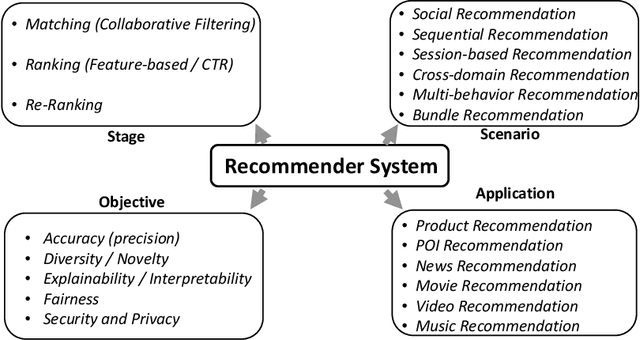

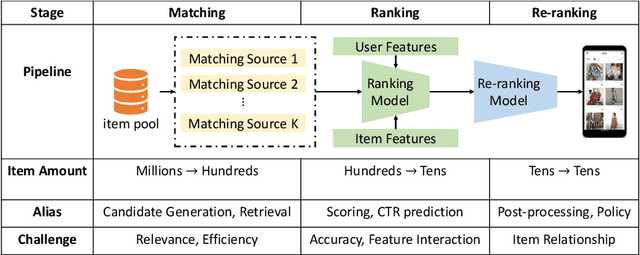
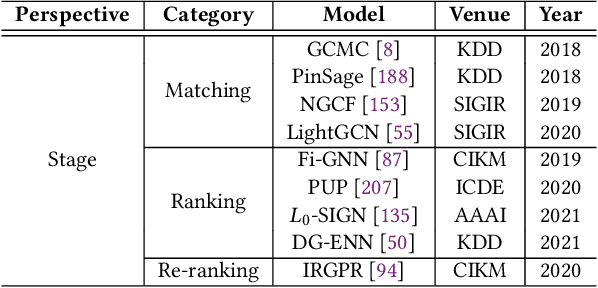
Recommender system is one of the most important information services on today's Internet. Recently, graph neural networks have become the new state-of-the-art approach of recommender systems. In this survey, we conduct a comprehensive review of the literature in graph neural network-based recommender systems. We first introduce the background and the history of the development of both recommender systems and graph neural networks. For recommender systems, in general, there are four aspects for categorizing existing works: stage, scenario, objective, and application. For graph neural networks, the existing methods consist of two categories, spectral models and spatial ones. We then discuss the motivation of applying graph neural networks into recommender systems, mainly consisting of the high-order connectivity, the structural property of data, and the enhanced supervision signal. We then systematically analyze the challenges in graph construction, embedding propagation/aggregation, model optimization, and computation efficiency. Afterward and primarily, we provide a comprehensive overview of a multitude of existing works of graph neural network-based recommender systems, following the taxonomy above. Finally, we raise discussions on the open problems and promising future directions of this area. We summarize the representative papers along with their codes repositories in https://github.com/tsinghua-fib-lab/GNN-Recommender-Systems.
TabGNN: Multiplex Graph Neural Network for Tabular Data Prediction
Aug 20, 2021

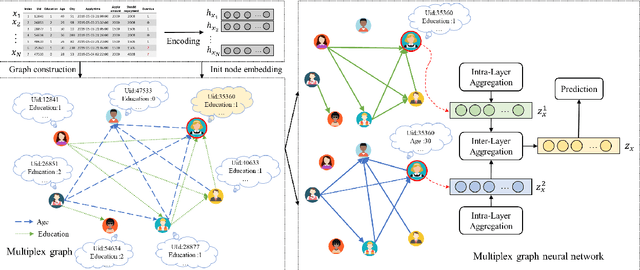
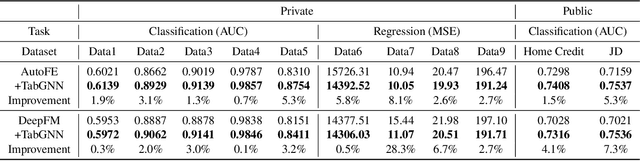
Tabular data prediction (TDP) is one of the most popular industrial applications, and various methods have been designed to improve the prediction performance. However, existing works mainly focus on feature interactions and ignore sample relations, e.g., users with the same education level might have a similar ability to repay the debt. In this work, by explicitly and systematically modeling sample relations, we propose a novel framework TabGNN based on recently popular graph neural networks (GNN). Specifically, we firstly construct a multiplex graph to model the multifaceted sample relations, and then design a multiplex graph neural network to learn enhanced representation for each sample. To integrate TabGNN with the tabular solution in our company, we concatenate the learned embeddings and the original ones, which are then fed to prediction models inside the solution. Experiments on eleven TDP datasets from various domains, including classification and regression ones, show that TabGNN can consistently improve the performance compared to the tabular solution AutoFE in 4Paradigm.
Simplify and Robustify Negative Sampling for Implicit Collaborative Filtering
Sep 07, 2020

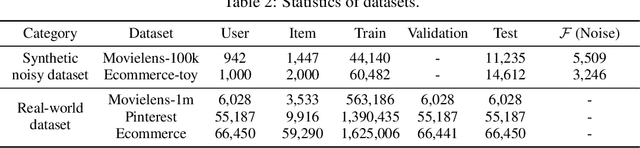

Negative sampling approaches are prevalent in implicit collaborative filtering for obtaining negative labels from massive unlabeled data. As two major concerns in negative sampling, efficiency and effectiveness are still not fully achieved by recent works that use complicate structures and overlook risk of false negative instances. In this paper, we first provide a novel understanding of negative instances by empirically observing that only a few instances are potentially important for model learning, and false negatives tend to have stable predictions over many training iterations. Above findings motivate us to simplify the model by sampling from designed memory that only stores a few important candidates and, more importantly, tackle the untouched false negative problem by favouring high-variance samples stored in memory, which achieves efficient sampling of true negatives with high-quality. Empirical results on two synthetic datasets and three real-world datasets demonstrate both robustness and superiorities of our negative sampling method.