 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicSim: A Unified Infrastructure for Executable Embodied Interaction
Jun 16, 2026Robot learning and embodied agents now require simulation to serve as a shared execution substrate linking control, skills, and planning, not only as a renderer, controller testbed, or fixed task environment. Existing pipelines split these layers with "magic" actions, disconnected training environments, or forward-only renders that cannot reproduce, evaluate, and annotate the same episode. We present MagicSim, an embodied interaction infrastructure built around one deterministic batched runtime and a shared Markov decision process (MDP). From YAML-first specifications that decouple contents, placement, behavior, and agent exposure, MagicSim constructs diverse executable worlds spanning task families, interaction regimes, physics, layouts, sensors, avatars, and robot embodiments in one reset-and-step loop. A common execution interface grounds high-level commands through controllers, atomicskills, planner primitives, and asynchronous planning, realizing them as robot actions rather than simulator-side state edits. One task definition supports three capabilities: benchmark and RL evaluation, an autocollect interface that automatically turns commands into grounded trajectories, and agent/VLM-facing interaction. For automatic execution, commands flow through a Command->Skill->Planner->Robot->Record pipeline, while per-environment command, skill, planning, retry, annotation, and episode states advance independently above the shared physics tick. Successful rollouts are saved as structured multimodal trajectories aligning language supervision, action representations, visual/geometric representations, and task-level status with the executed episode. MagicSim thus unifies diverse world construction, embodied execution, task evaluation, automatic rollout generation, and interactive agent interfaces in one planner-in-the-loop runtime.
HuB: Learning Extreme Humanoid Balance
May 12, 2025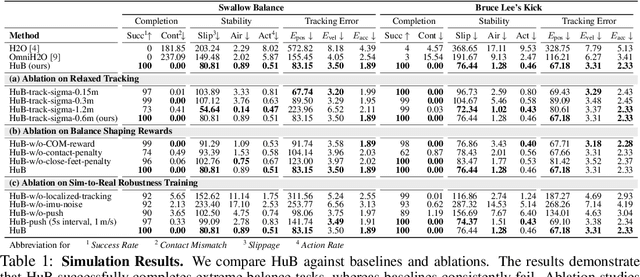
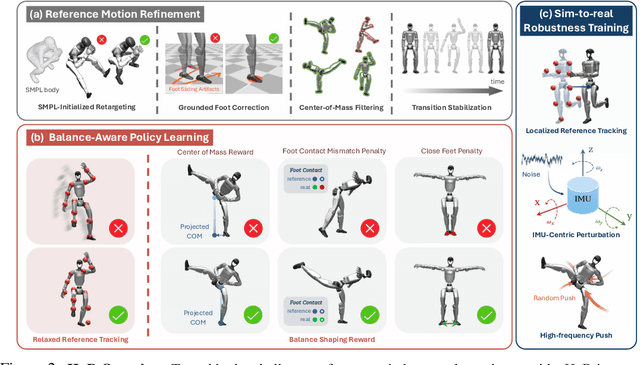
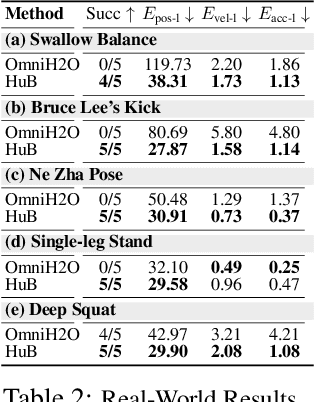
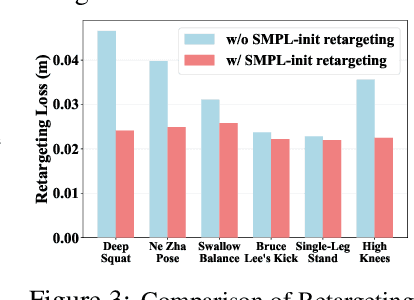
The human body demonstrates exceptional motor capabilities-such as standing steadily on one foot or performing a high kick with the leg raised over 1.5 meters-both requiring precise balance control. While recent research on humanoid control has leveraged reinforcement learning to track human motions for skill acquisition, applying this paradigm to balance-intensive tasks remains challenging. In this work, we identify three key obstacles: instability from reference motion errors, learning difficulties due to morphological mismatch, and the sim-to-real gap caused by sensor noise and unmodeled dynamics. To address these challenges, we propose HuB (Humanoid Balance), a unified framework that integrates reference motion refinement, balance-aware policy learning, and sim-to-real robustness training, with each component targeting a specific challenge. We validate our approach on the Unitree G1 humanoid robot across challenging quasi-static balance tasks, including extreme single-legged poses such as Swallow Balance and Bruce Lee's Kick. Our policy remains stable even under strong physical disturbances-such as a forceful soccer strike-while baseline methods consistently fail to complete these tasks. Project website: https://hub-robot.github.io
Learning Multi-Agent Loco-Manipulation for Long-Horizon Quadrupedal Pushing
Nov 14, 2024Recently, quadrupedal locomotion has achieved significant success, but their manipulation capabilities, particularly in handling large objects, remain limited, restricting their usefulness in demanding real-world applications such as search and rescue, construction, industrial automation, and room organization. This paper tackles the task of obstacle-aware, long-horizon pushing by multiple quadrupedal robots. We propose a hierarchical multi-agent reinforcement learning framework with three levels of control. The high-level controller integrates an RRT planner and a centralized adaptive policy to generate subgoals, while the mid-level controller uses a decentralized goal-conditioned policy to guide the robots toward these sub-goals. A pre-trained low-level locomotion policy executes the movement commands. We evaluate our method against several baselines in simulation, demonstrating significant improvements over baseline approaches, with 36.0% higher success rates and 24.5% reduction in completion time than the best baseline. Our framework successfully enables long-horizon, obstacle-aware manipulation tasks like Push-Cuboid and Push-T on Go1 robots in the real world.
Learning a Distributed Hierarchical Locomotion Controller for Embodied Cooperation
Jul 09, 2024

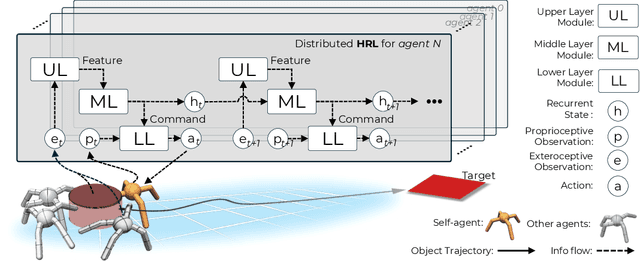

In this work, we propose a distributed hierarchical locomotion control strategy for whole-body cooperation and demonstrate the potential for migration into large numbers of agents. Our method utilizes a hierarchical structure to break down complex tasks into smaller, manageable sub-tasks. By incorporating spatiotemporal continuity features, we establish the sequential logic necessary for causal inference and cooperative behaviour in sequential tasks, thereby facilitating efficient and coordinated control strategies. Through training within this framework, we demonstrate enhanced adaptability and cooperation, leading to superior performance in task completion compared to the original methods. Moreover, we construct a set of environments as the benchmark for embodied cooperation.