 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Autoregressive Video Generation with Diagonal Decoding
Paper and Code
Mar 18, 2025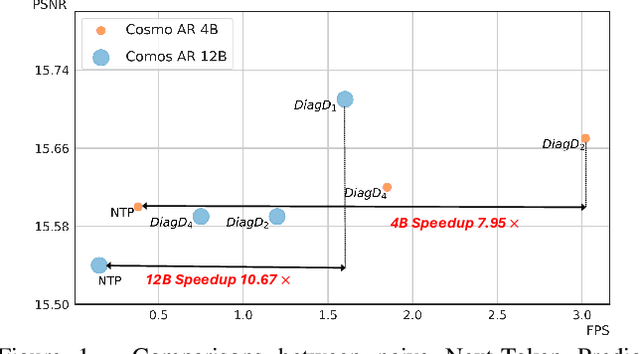
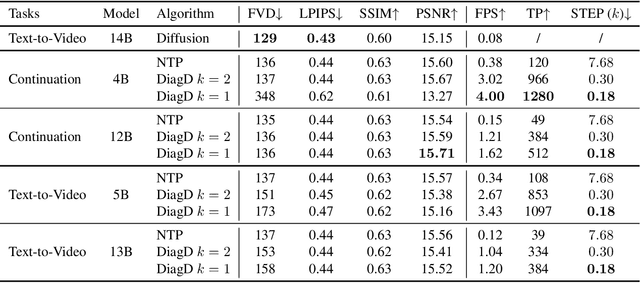
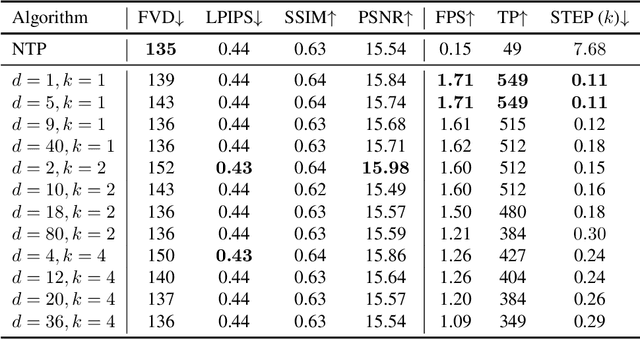
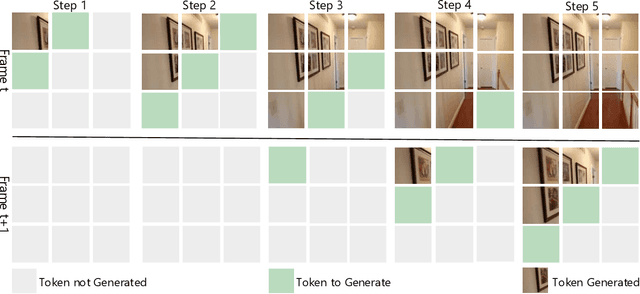
Autoregressive Transformer models have demonstrated impressive performance in video generation, but their sequential token-by-token decoding process poses a major bottleneck, particularly for long videos represented by tens of thousands of tokens. In this paper, we propose Diagonal Decoding (DiagD), a training-free inference acceleration algorithm for autoregressively pre-trained models that exploits spatial and temporal correlations in videos. Our method generates tokens along diagonal paths in the spatial-temporal token grid, enabling parallel decoding within each frame as well as partially overlapping across consecutive frames. The proposed algorithm is versatile and adaptive to various generative models and tasks, while providing flexible control over the trade-off between inference speed and visual quality. Furthermore, we propose a cost-effective finetuning strategy that aligns the attention patterns of the model with our decoding order, further mitigating the training-inference gap on small-scale models. Experiments on multiple autoregressive video generation models and datasets demonstrate that DiagD achieves up to $10\times$ speedup compared to naive sequential decoding, while maintaining comparable visual fidelity.