 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Representations for Control with Hierarchical Forward Models
Paper and Code
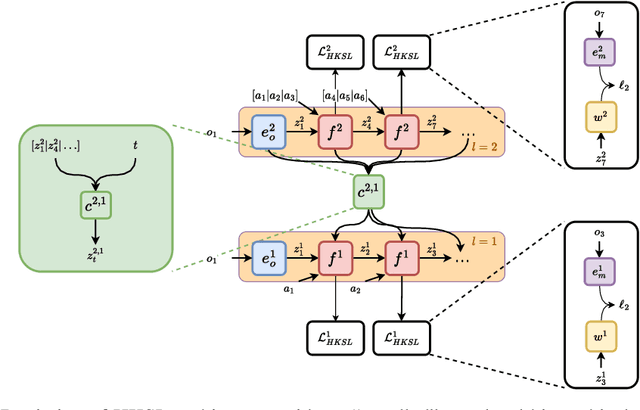
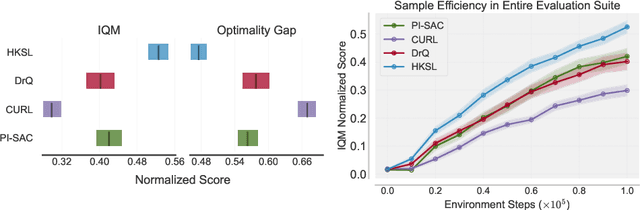

Learning control from pixels is difficult for reinforcement learning (RL) agents because representation learning and policy learning are intertwined. Previous approaches remedy this issue with auxiliary representation learning tasks, but they either do not consider the temporal aspect of the problem or only consider single-step transitions. Instead, we propose Hierarchical $k$-Step Latent (HKSL), an auxiliary task that learns representations via a hierarchy of forward models that operate at varying magnitudes of step skipping while also learning to communicate between levels in the hierarchy. We evaluate HKSL in a suite of 30 robotic control tasks and find that HKSL either reaches higher episodic returns or converges to maximum performance more quickly than several current baselines. Also, we find that levels in HKSL's hierarchy can learn to specialize in long- or short-term consequences of agent actions, thereby providing the downstream control policy with more informative representations. Finally, we determine that communication channels between hierarchy levels organize information based on both sides of the communication process, which improves sample efficiency.