 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust On-Policy Data Collection for Data-Efficient Policy Evaluation
Nov 29, 2021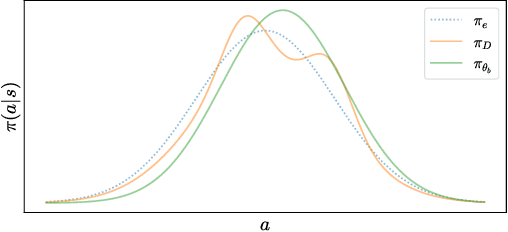

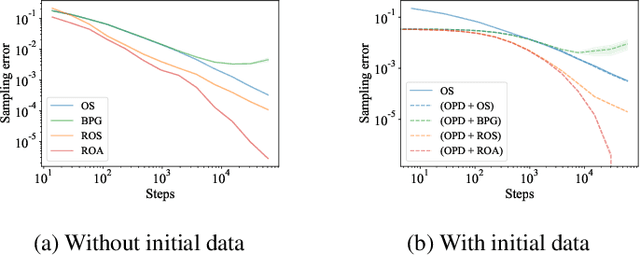
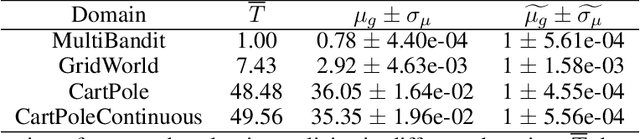
This paper considers how to complement offline reinforcement learning (RL) data with additional data collection for the task of policy evaluation. In policy evaluation, the task is to estimate the expected return of an evaluation policy on an environment of interest. Prior work on offline policy evaluation typically only considers a static dataset. We consider a setting where we can collect a small amount of additional data to combine with a potentially larger offline RL dataset. We show that simply running the evaluation policy -- on-policy data collection -- is sub-optimal for this setting. We then introduce two new data collection strategies for policy evaluation, both of which consider previously collected data when collecting future data so as to reduce distribution shift (or sampling error) in the entire dataset collected. Our empirical results show that compared to on-policy sampling, our strategies produce data with lower sampling error and generally lead to lower mean-squared error in policy evaluation for any total dataset size. We also show that these strategies can start from initial off-policy data, collect additional data, and then use both the initial and new data to produce low mean-squared error policy evaluation without using off-policy corrections.