 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Model Averaging under Predictor Redundancy via Density-Ratio Posterior Compression
Jun 19, 2026Bayesian model averaging in support-indexed regression induces a posterior distribution over active predictor supports. Under predictor redundancy, posterior mass can spread across many nearly interchangeable supports, making exact-support summaries unstable or hard to interpret even when prediction is stable. We study how to report an already fitted Bayesian model averaging posterior without changing the Bayesian target. A report uses hard or soft regions of support space, and its compressed reporting law is compared with the reference posterior through an explicit density ratio. This ratio gives computable total-variation and Kullback--Leibler distortion, bounds for bounded predictive summaries, retained-mass diagnostics, and fallback-weight diagnostics. The framework covers fixed hard regions, metric-ball regions, posterior-cluster regions, and pooled-pruned region dictionaries. We prove exact error formulas and validation bounds for these region reports, and give conditions under which a few regions can replace a long list of individual supports. In simulations, our region reports often give shorter and clearer summaries while preserving the main posterior information, and the density-ratio diagnostics show when too much information has been lost.
Zero-shot Graph Reasoning via Retrieval Augmented Framework with LLMs
Sep 16, 2025We propose a new, training-free method, Graph Reasoning via Retrieval Augmented Framework (GRRAF), that harnesses retrieval-augmented generation (RAG) alongside the code-generation capabilities of large language models (LLMs) to address a wide range of graph reasoning tasks. In GRRAF, the target graph is stored in a graph database, and the LLM is prompted to generate executable code queries that retrieve the necessary information. This approach circumvents the limitations of existing methods that require extensive finetuning or depend on predefined algorithms, and it incorporates an error feedback loop with a time-out mechanism to ensure both correctness and efficiency. Experimental evaluations on the GraphInstruct dataset reveal that GRRAF achieves 100% accuracy on most graph reasoning tasks, including cycle detection, bipartite graph checks, shortest path computation, and maximum flow, while maintaining consistent token costs regardless of graph sizes. Imperfect but still very high performance is observed on subgraph matching. Notably, GRRAF scales effectively to large graphs with up to 10,000 nodes.
BEAR: BGP Event Analysis and Reporting
Jun 04, 2025

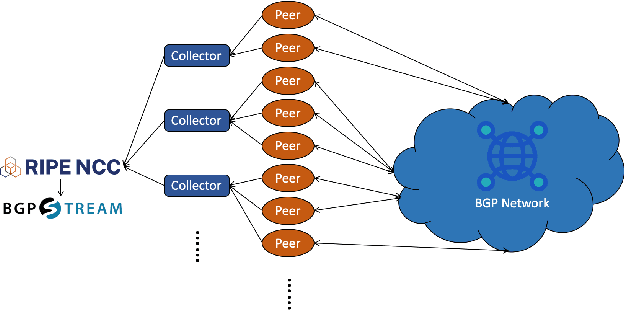

The Internet comprises of interconnected, independently managed Autonomous Systems (AS) that rely on the Border Gateway Protocol (BGP) for inter-domain routing. BGP anomalies--such as route leaks and hijacks--can divert traffic through unauthorized or inefficient paths, jeopardizing network reliability and security. Although existing rule-based and machine learning methods can detect these anomalies using structured metrics, they still require experts with in-depth BGP knowledge of, for example, AS relationships and historical incidents, to interpret events and propose remediation. In this paper, we introduce BEAR (BGP Event Analysis and Reporting), a novel framework that leverages large language models (LLMs) to automatically generate comprehensive reports explaining detected BGP anomaly events. BEAR employs a multi-step reasoning process that translates tabular BGP data into detailed textual narratives, enhancing interpretability and analytical precision. To address the limited availability of publicly documented BGP anomalies, we also present a synthetic data generation framework powered by LLMs. Evaluations on both real and synthetic datasets demonstrate that BEAR achieves 100% accuracy, outperforming Chain-of-Thought and in-context learning baselines. This work pioneers an automated approach for explaining BGP anomaly events, offering valuable operational insights for network management.
Reverse Prompt Engineering
Nov 25, 2024This paper explores a new black-box, zero-shot language model inversion problem and proposes an innovative framework for prompt reconstruction using only text outputs from a language model. Leveraging a large language model alongside an optimization algorithm, the proposed method effectively recovers prompts with minimal resources. Experimental results on several datasets derived from public sources indicate that the proposed approach achieves high-quality prompt recovery and generates prompts more similar to the originals than current state-of-the-art methods. Additionally, the use-case study demonstrates the method's strong potential for generating high-quality text data.
Unsupervised Video Summarization
Nov 07, 2023This paper introduces a new, unsupervised method for automatic video summarization using ideas from generative adversarial networks but eliminating the discriminator, having a simple loss function, and separating training of different parts of the model. An iterative training strategy is also applied by alternately training the reconstructor and the frame selector for multiple iterations. Furthermore, a trainable mask vector is added to the model in summary generation during training and evaluation. The method also includes an unsupervised model selection algorithm. Results from experiments on two public datasets (SumMe and TVSum) and four datasets we created (Soccer, LoL, MLB, and ShortMLB) demonstrate the effectiveness of each component on the model performance, particularly the iterative training strategy. Evaluations and comparisons with the state-of-the-art methods highlight the advantages of the proposed method in performance, stability, and training efficiency.
Learning Unified Representations for Multi-Resolution Face Recognition
Oct 14, 2023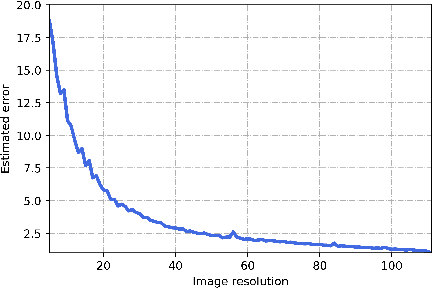
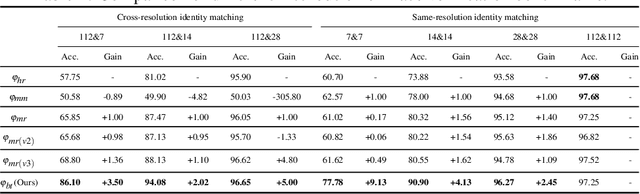
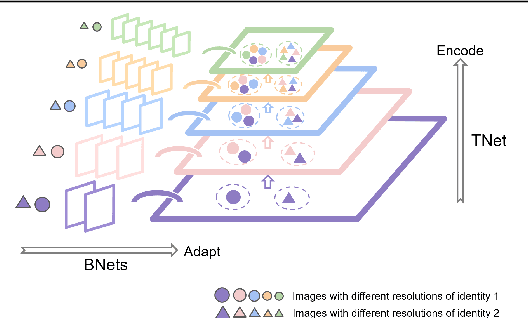
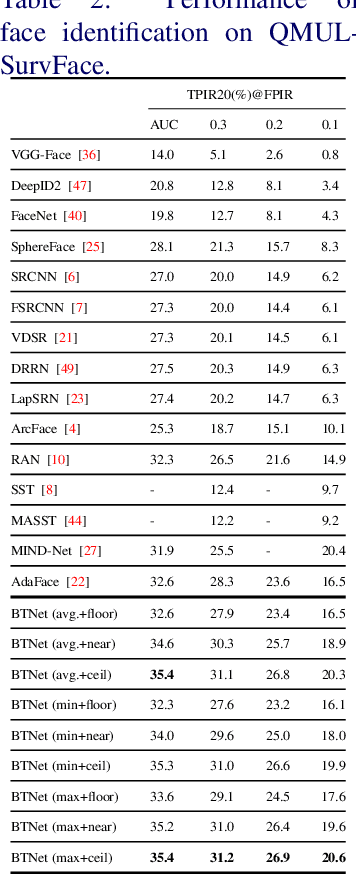
In this work, we propose Branch-to-Trunk network (BTNet), a representation learning method for multi-resolution face recognition. It consists of a trunk network (TNet), namely a unified encoder, and multiple branch networks (BNets), namely resolution adapters. As per the input, a resolution-specific BNet is used and the output are implanted as feature maps in the feature pyramid of TNet, at a layer with the same resolution. The discriminability of tiny faces is significantly improved, as the interpolation error introduced by rescaling, especially up-sampling, is mitigated on the inputs. With branch distillation and backward-compatible training, BTNet transfers discriminative high-resolution information to multiple branches while guaranteeing representation compatibility. Our experiments demonstrate strong performance on face recognition benchmarks, both for multi-resolution identity matching and feature aggregation, with much less computation amount and parameter storage. We establish new state-of-the-art on the challenging QMUL-SurvFace 1: N face identification task. Our code is available at https://github.com/StevenSmith2000/BTNet.
Cross Domain Object Detection by Target-Perceived Dual Branch Distillation
May 03, 2022
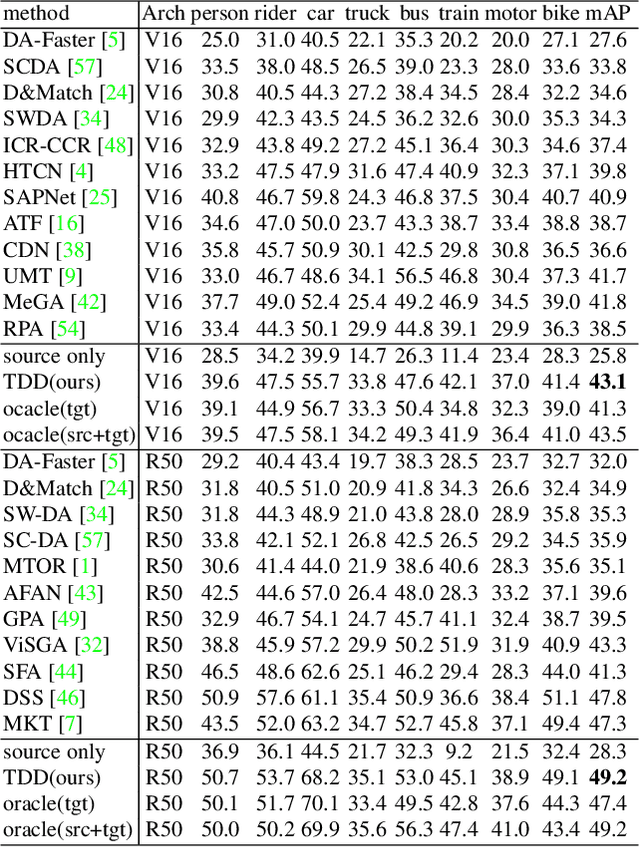
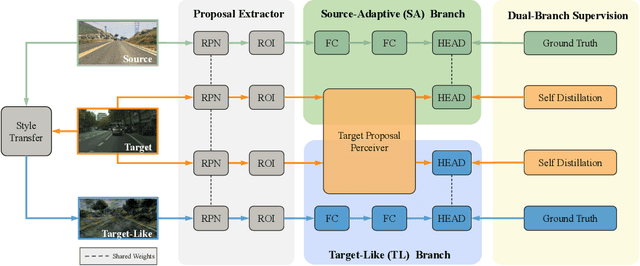
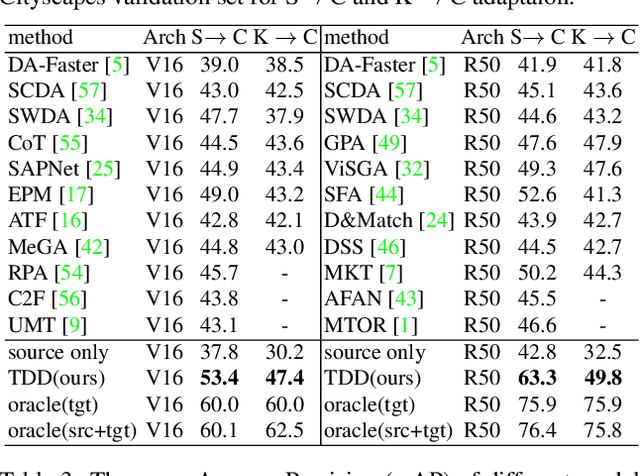
Cross domain object detection is a realistic and challenging task in the wild. It suffers from performance degradation due to large shift of data distributions and lack of instance-level annotations in the target domain. Existing approaches mainly focus on either of these two difficulties, even though they are closely coupled in cross domain object detection. To solve this problem, we propose a novel Target-perceived Dual-branch Distillation (TDD) framework. By integrating detection branches of both source and target domains in a unified teacher-student learning scheme, it can reduce domain shift and generate reliable supervision effectively. In particular, we first introduce a distinct Target Proposal Perceiver between two domains. It can adaptively enhance source detector to perceive objects in a target image, by leveraging target proposal contexts from iterative cross-attention. Afterwards, we design a concise Dual Branch Self Distillation strategy for model training, which can progressively integrate complementary object knowledge from different domains via self-distillation in two branches. Finally, we conduct extensive experiments on a number of widely-used scenarios in cross domain object detection. The results show that our TDD significantly outperforms the state-of-the-art methods on all the benchmarks. Our code and model will be available at https://github.com/Feobi1999/TDD.