 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaAct: Simulating Short-Video Users with Personalized Agents for Counterfactual Filter Bubble Auditing
Jan 30, 2026Short-video platforms rely on personalized recommendation, raising concerns about filter bubbles that narrow content exposure. Auditing such phenomena at scale is challenging because real user studies are costly and privacy-sensitive, and existing simulators fail to reproduce realistic behaviors due to their reliance on textual signals and weak personalization. We propose PersonaAct, a framework for simulating short-video users with persona-conditioned multimodal agents trained on real behavioral traces for auditing filter bubbles in breadth and depth. PersonaAct synthesizes interpretable personas through automated interviews combining behavioral analysis with structured questioning, then trains agents on multimodal observations using supervised fine-tuning and reinforcement learning. We deploy trained agents for filter bubble auditing and evaluate bubble breadth via content diversity and bubble depth via escape potential. The evaluation demonstrates substantial improvements in fidelity over generic LLM baselines, enabling realistic behavior reproduction. Results reveal significant content narrowing over interaction. However, we find that Bilibili demonstrates the strongest escape potential. We release the first open multimodal short-video dataset and code to support reproducible auditing of recommender systems.
LLM4MEA: Data-free Model Extraction Attacks on Sequential Recommenders via Large Language Models
Jul 22, 2025Recent studies have demonstrated the vulnerability of sequential recommender systems to Model Extraction Attacks (MEAs). MEAs collect responses from recommender systems to replicate their functionality, enabling unauthorized deployments and posing critical privacy and security risks. Black-box attacks in prior MEAs are ineffective at exposing recommender system vulnerabilities due to random sampling in data selection, which leads to misaligned synthetic and real-world distributions. To overcome this limitation, we propose LLM4MEA, a novel model extraction method that leverages Large Language Models (LLMs) as human-like rankers to generate data. It generates data through interactions between the LLM ranker and target recommender system. In each interaction, the LLM ranker analyzes historical interactions to understand user behavior, and selects items from recommendations with consistent preferences to extend the interaction history, which serves as training data for MEA. Extensive experiments demonstrate that LLM4MEA significantly outperforms existing approaches in data quality and attack performance, reducing the divergence between synthetic and real-world data by up to 64.98% and improving MEA performance by 44.82% on average. From a defensive perspective, we propose a simple yet effective defense strategy and identify key hyperparameters of recommender systems that can mitigate the risk of MEAs.
Learning Unified Representations for Multi-Resolution Face Recognition
Oct 14, 2023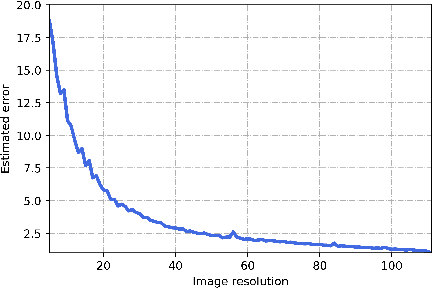
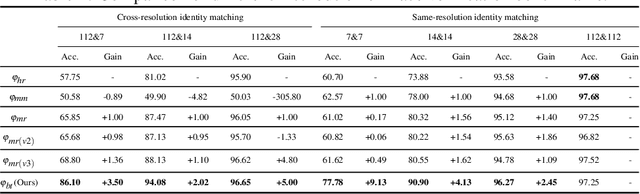
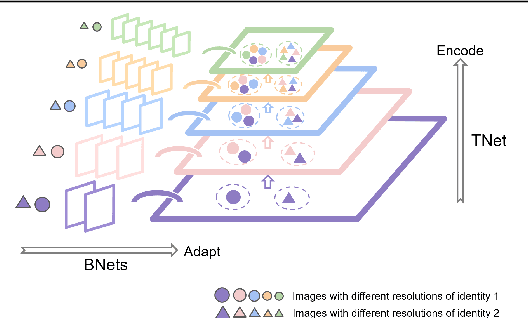
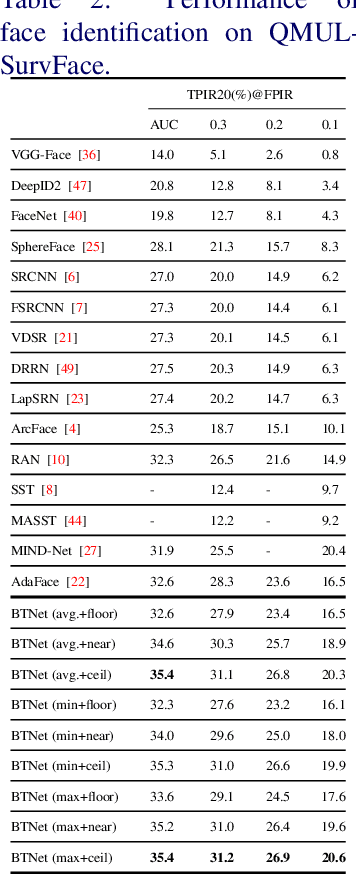
In this work, we propose Branch-to-Trunk network (BTNet), a representation learning method for multi-resolution face recognition. It consists of a trunk network (TNet), namely a unified encoder, and multiple branch networks (BNets), namely resolution adapters. As per the input, a resolution-specific BNet is used and the output are implanted as feature maps in the feature pyramid of TNet, at a layer with the same resolution. The discriminability of tiny faces is significantly improved, as the interpolation error introduced by rescaling, especially up-sampling, is mitigated on the inputs. With branch distillation and backward-compatible training, BTNet transfers discriminative high-resolution information to multiple branches while guaranteeing representation compatibility. Our experiments demonstrate strong performance on face recognition benchmarks, both for multi-resolution identity matching and feature aggregation, with much less computation amount and parameter storage. We establish new state-of-the-art on the challenging QMUL-SurvFace 1: N face identification task. Our code is available at https://github.com/StevenSmith2000/BTNet.