 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEGTR: Extracting Graph from Transformer for Scene Graph Generation
Apr 05, 2024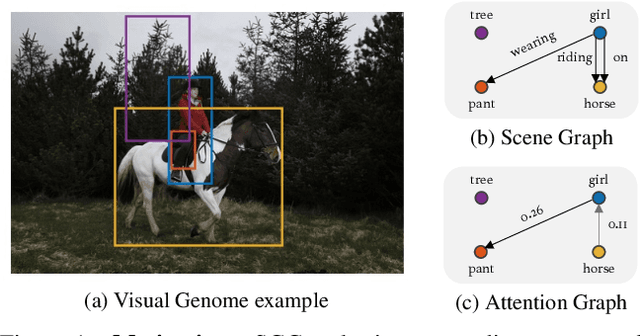



Scene Graph Generation (SGG) is a challenging task of detecting objects and predicting relationships between objects. After DETR was developed, one-stage SGG models based on a one-stage object detector have been actively studied. However, complex modeling is used to predict the relationship between objects, and the inherent relationship between object queries learned in the multi-head self-attention of the object detector has been neglected. We propose a lightweight one-stage SGG model that extracts the relation graph from the various relationships learned in the multi-head self-attention layers of the DETR decoder. By fully utilizing the self-attention by-products, the relation graph can be extracted effectively with a shallow relation extraction head. Considering the dependency of the relation extraction task on the object detection task, we propose a novel relation smoothing technique that adjusts the relation label adaptively according to the quality of the detected objects. By the relation smoothing, the model is trained according to the continuous curriculum that focuses on object detection task at the beginning of training and performs multi-task learning as the object detection performance gradually improves. Furthermore, we propose a connectivity prediction task that predicts whether a relation exists between object pairs as an auxiliary task of the relation extraction. We demonstrate the effectiveness and efficiency of our method for the Visual Genome and Open Image V6 datasets. Our code is publicly available at https://github.com/naver-ai/egtr.
InstructBooth: Instruction-following Personalized Text-to-Image Generation
Dec 04, 2023


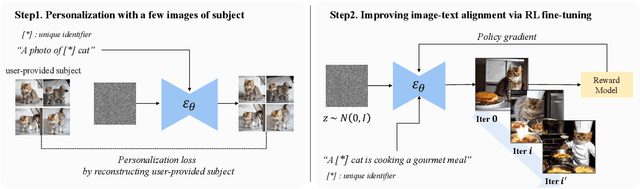
Personalizing text-to-image models using a limited set of images for a specific object has been explored in subject-specific image generation. However, existing methods often encounter challenges in aligning with text prompts due to overfitting to the limited training images. In this work, we introduce InstructBooth, a novel method designed to enhance image-text alignment in personalized text-to-image models. Our approach first personalizes text-to-image models with a small number of subject-specific images using a unique identifier. After personalization, we fine-tune personalized text-to-image models using reinforcement learning to maximize a reward that quantifies image-text alignment. Additionally, we propose complementary techniques to increase the synergy between these two processes. Our method demonstrates superior image-text alignment compared to baselines while maintaining personalization ability. In human evaluations, InstructBooth outperforms DreamBooth when considering all comprehensive factors.
Bridging the Domain Gap by Clustering-based Image-Text Graph Matching
Oct 04, 2023Learning domain-invariant representations is important to train a model that can generalize well to unseen target task domains. Text descriptions inherently contain semantic structures of concepts and such auxiliary semantic cues can be used as effective pivot embedding for domain generalization problems. Here, we use multimodal graph representations, fusing images and text, to get domain-invariant pivot embeddings by considering the inherent semantic structure between local images and text descriptors. Specifically, we aim to learn domain-invariant features by (i) representing the image and text descriptions with graphs, and by (ii) clustering and matching the graph-based image node features into textual graphs simultaneously. We experiment with large-scale public datasets, such as CUB-DG and DomainBed, and our model achieves matched or better state-of-the-art performance on these datasets. Our code will be publicly available upon publication.
Grounding Visual Representations with Texts for Domain Generalization
Jul 21, 2022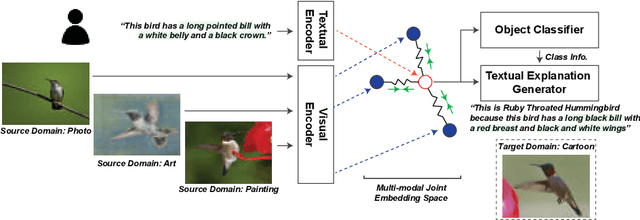
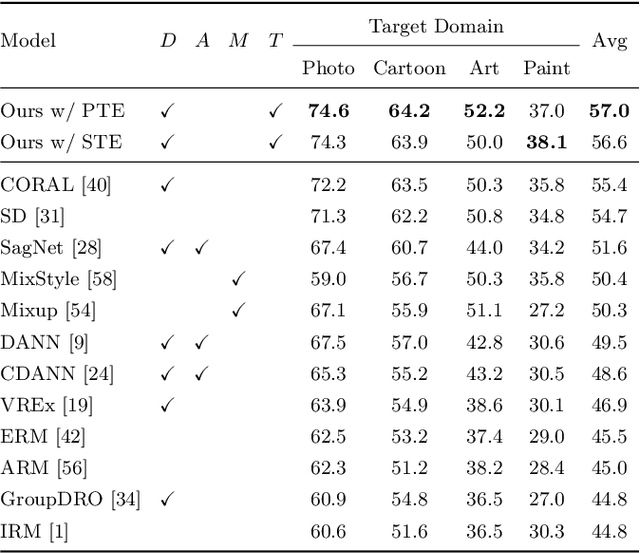
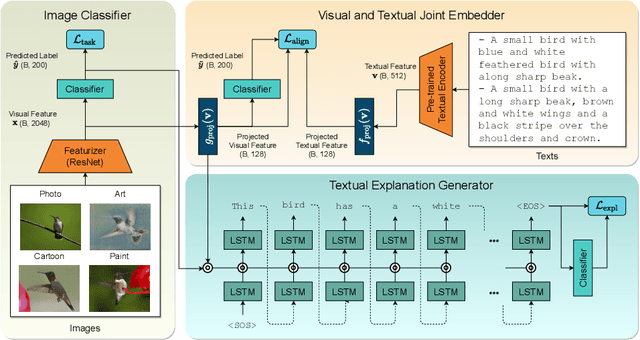
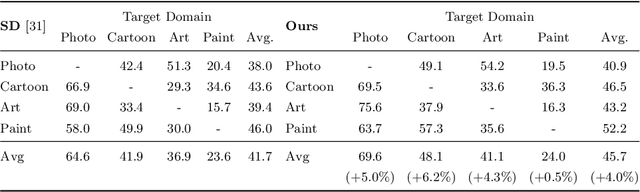
Reducing the representational discrepancy between source and target domains is a key component to maximize the model generalization. In this work, we advocate for leveraging natural language supervision for the domain generalization task. We introduce two modules to ground visual representations with texts containing typical reasoning of humans: (1) Visual and Textual Joint Embedder and (2) Textual Explanation Generator. The former learns the image-text joint embedding space where we can ground high-level class-discriminative information into the model. The latter leverages an explainable model and generates explanations justifying the rationale behind its decision. To the best of our knowledge, this is the first work to leverage the vision-and-language cross-modality approach for the domain generalization task. Our experiments with a newly created CUB-DG benchmark dataset demonstrate that cross-modality supervision can be successfully used to ground domain-invariant visual representations and improve the model generalization. Furthermore, in the large-scale DomainBed benchmark, our proposed method achieves state-of-the-art results and ranks 1st in average performance for five multi-domain datasets. The dataset and codes are available at https://github.com/mswzeus/GVRT.
A Framework for Recognizing and Estimating Human Concentration Levels
Apr 23, 2021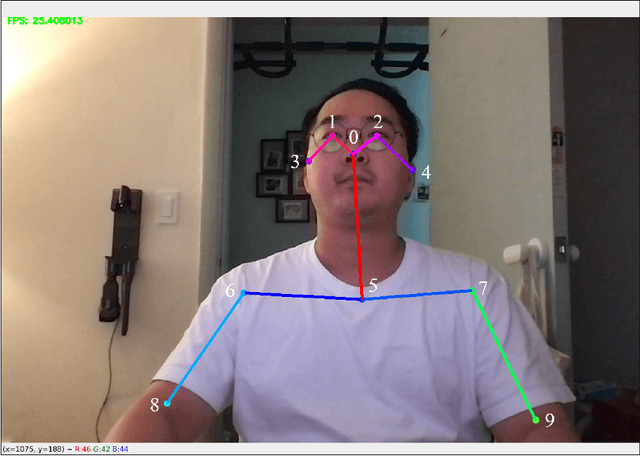

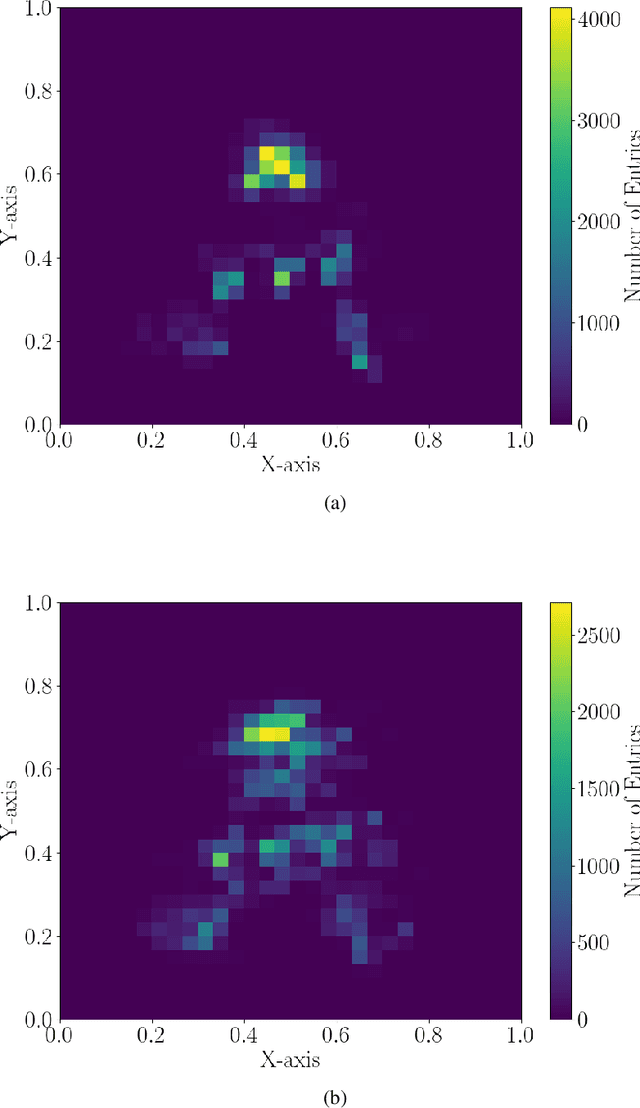
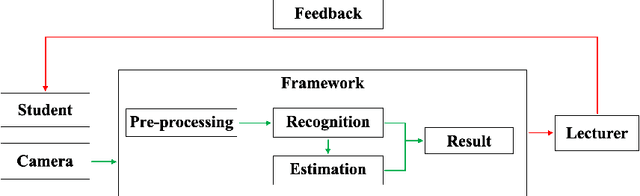
One of the major tasks in online education is to estimate the concentration levels of each student. Previous studies have a limitation of classifying the levels using discrete states only. The purpose of this paper is to estimate the subtle levels as specified states by using the minimum amount of body movement data. This is done by a framework composed of a Deep Neural Network and Kalman Filter. Using this framework, we successfully extracted the concentration levels, which can be used to aid lecturers and expand to other areas.