 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructBooth: Instruction-following Personalized Text-to-Image Generation
Paper and Code



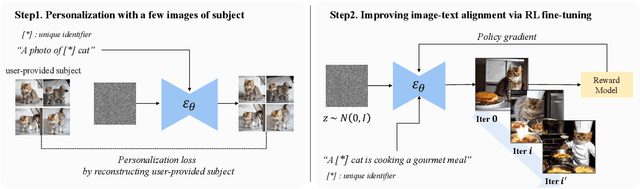
Personalizing text-to-image models using a limited set of images for a specific object has been explored in subject-specific image generation. However, existing methods often encounter challenges in aligning with text prompts due to overfitting to the limited training images. In this work, we introduce InstructBooth, a novel method designed to enhance image-text alignment in personalized text-to-image models. Our approach first personalizes text-to-image models with a small number of subject-specific images using a unique identifier. After personalization, we fine-tune personalized text-to-image models using reinforcement learning to maximize a reward that quantifies image-text alignment. Additionally, we propose complementary techniques to increase the synergy between these two processes. Our method demonstrates superior image-text alignment compared to baselines while maintaining personalization ability. In human evaluations, InstructBooth outperforms DreamBooth when considering all comprehensive factors.