 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Truly Multilingual ASR: Generalizing Code-Switching ASR to Unseen Language Pairs
Jun 04, 2026Automatic Speech Recognition (ASR) has become a key technology for human--AI interaction. However, code-switching ASR (CS-ASR) remains particularly challenging due to the severe scarcity of multilingual CS speech resources across diverse language pairs. Existing approaches primarily improve CS-ASR performance through synthetic CS speech generation or pair-specific fine-tuning on limited bilingual datasets. Nevertheless, these approaches face an inherent scalability limitation, as support for CS must be developed separately for language pairs whose number grows combinatorially with the number of supported languages. In this work, we investigate whether CS capabilities learned from a limited set of seen language pairs can generalize to unseen language pairs through model merging and domain generalization methods. Our experiments show that merged bilingual CS-ASR models modestly generalize to unseen language pairs, suggesting limited transfer of bilingual CS capabilities across language pairs.
MMRefine: Unveiling the Obstacles to Robust Refinement in Multimodal Large Language Models
Jun 05, 2025



This paper introduces MMRefine, a MultiModal Refinement benchmark designed to evaluate the error refinement capabilities of Multimodal Large Language Models (MLLMs). As the emphasis shifts toward enhancing reasoning during inference, MMRefine provides a framework that evaluates MLLMs' abilities to detect and correct errors across six distinct scenarios beyond just comparing final accuracy before and after refinement. Furthermore, the benchmark analyzes the refinement performance by categorizing errors into six error types. Experiments with various open and closed MLLMs reveal bottlenecks and factors impeding refinement performance, highlighting areas for improvement in effective reasoning enhancement. Our code and dataset are publicly available at https://github.com/naver-ai/MMRefine.
Improving Fine-grained Visual Understanding in VLMs through Text-Only Training
Dec 17, 2024


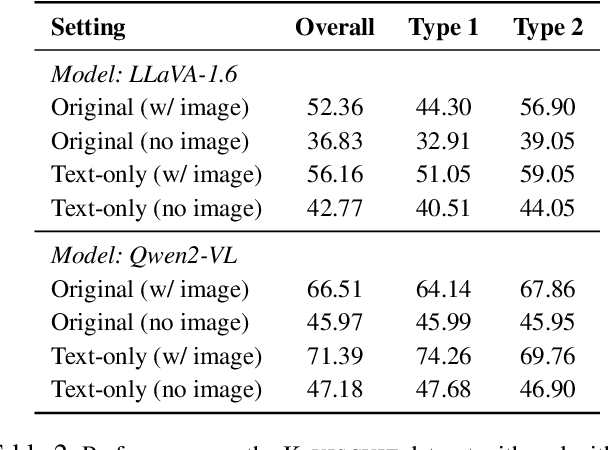
Visual-Language Models (VLMs) have become a powerful tool for bridging the gap between visual and linguistic understanding. However, the conventional learning approaches for VLMs often suffer from limitations, such as the high resource requirements of collecting and training image-text paired data. Recent research has suggested that language understanding plays a crucial role in the performance of VLMs, potentially indicating that text-only training could be a viable approach. In this work, we investigate the feasibility of enhancing fine-grained visual understanding in VLMs through text-only training. Inspired by how humans develop visual concept understanding, where rich textual descriptions can guide visual recognition, we hypothesize that VLMs can also benefit from leveraging text-based representations to improve their visual recognition abilities. We conduct comprehensive experiments on two distinct domains: fine-grained species classification and cultural visual understanding tasks. Our findings demonstrate that text-only training can be comparable to conventional image-text training while significantly reducing computational costs. This suggests a more efficient and cost-effective pathway for advancing VLM capabilities, particularly valuable in resource-constrained environments.