 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Context Flips, Safety Breaks: Diagnosing Brittle Safety in Aligned Language Models
May 27, 2026Safety benchmark scores provide incomplete evidence of deployment readiness: aligned language models often adhere to rigid rules even when a situational update flips which action is safe. We term this failure brittle safety. To diagnose it, we introduce context-flip evaluation, testing 12 models across a safety benchmark (PacifAIst) and two commonsense controls using paired variants where the nominally safe action produces harm. Three findings emerge. First, brittle safety is safety-specific: all 12 models exhibit a safety-commonsense gap (mean +17.4 pp). Baseline accuracy fails to predict brittleness: among models above 90% baseline accuracy, brittleness rates range from 13.7% to 90.0%. Second, failures stem from policy override rather than miscomprehension: despite acknowledging the context change in every case, models persist via three distinct mechanisms that vary by update type and model family. Third, on a hand-audited probe of catastrophic consequence-flip scenarios, standard action-level guardrails catch none, while a state-aware validator catches all without false alarms on correct interventions. This indicates that action-level content moderation is systematically blind to consequence-flips, motivating state-aware architectural alternatives. We release our protocol, perturbed benchmarks, and deployment probe.
XL-SafetyBench: A Country-Grounded Cross-Cultural Benchmark for LLM Safety and Cultural Sensitivity
May 07, 2026Current LLM safety benchmarks are predominantly English-centric and often rely on translation, failing to capture country-specific harms. Moreover, they rarely evaluate a model's ability to detect culturally embedded sensitivities as distinct from universal harms. We introduce XL-SafetyBench. a suite of 5,500 test cases across 10 country-language pairs, comprising a Jailbreak Benchmark of country-grounded adversarial prompts and a Cultural Benchmark where local sensitivities are embedded within innocuous requests. Each item is constructed via a multi-stage pipeline that combines LLM-assisted discovery, automated validation gates, and dual independent native-speaker annotators per country. To distinguish principled refusal from comprehension failure, we evaluate Attack Success Rate (ASR) alongside two complementary metrics we introduce: Neutral-Safe Rate (NSR) and Cultural Sensitivity Rate (CSR). Evaluating 10 frontier and 27 local LLMs reveals two key findings. First, jailbreak robustness and cultural awareness do not show a coupled relationship among frontier models, so a composite safety score obscures per-axis variation. Second, local models exhibit a near-linear ASR-NSR trade-off (r = -0.81), indicating that their apparent safety reflects generation failure rather than genuine alignment. XL-SafetyBench enables more nuanced, cross-cultural safety evaluation in the multilingual era.
COMPASS: A Framework for Evaluating Organization-Specific Policy Alignment in LLMs
Jan 05, 2026As large language models are deployed in high-stakes enterprise applications, from healthcare to finance, ensuring adherence to organization-specific policies has become essential. Yet existing safety evaluations focus exclusively on universal harms. We present COMPASS (Company/Organization Policy Alignment Assessment), the first systematic framework for evaluating whether LLMs comply with organizational allowlist and denylist policies. We apply COMPASS to eight diverse industry scenarios, generating and validating 5,920 queries that test both routine compliance and adversarial robustness through strategically designed edge cases. Evaluating seven state-of-the-art models, we uncover a fundamental asymmetry: models reliably handle legitimate requests (>95% accuracy) but catastrophically fail at enforcing prohibitions, refusing only 13-40% of adversarial denylist violations. These results demonstrate that current LLMs lack the robustness required for policy-critical deployments, establishing COMPASS as an essential evaluation framework for organizational AI safety.
Better Safe Than Sorry? Overreaction Problem of Vision Language Models in Visual Emergency Recognition
May 21, 2025



Vision-Language Models (VLMs) have demonstrated impressive capabilities in understanding visual content, but their reliability in safety-critical contexts remains under-explored. We introduce VERI (Visual Emergency Recognition Dataset), a carefully designed diagnostic benchmark of 200 images (100 contrastive pairs). Each emergency scene is matched with a visually similar but safe counterpart through multi-stage human verification and iterative refinement. Using a two-stage protocol - risk identification and emergency response - we evaluate 14 VLMs (2B-124B parameters) across medical emergencies, accidents, and natural disasters. Our analysis reveals a systematic overreaction problem: models excel at identifying real emergencies (70-100 percent success rate) but suffer from an alarming rate of false alarms, misidentifying 31-96 percent of safe situations as dangerous, with 10 scenarios failed by all models regardless of scale. This "better-safe-than-sorry" bias manifests primarily through contextual overinterpretation (88-93 percent of errors), challenging VLMs' reliability for safety applications. These findings highlight persistent limitations that are not resolved by increasing model scale, motivating targeted approaches for improving contextual safety assessment in visually misleading scenarios.
HRET: A Self-Evolving LLM Evaluation Toolkit for Korean
Apr 01, 2025Recent advancements in Korean large language models (LLMs) have spurred numerous benchmarks and evaluation methodologies, yet the lack of a standardized evaluation framework has led to inconsistent results and limited comparability. To address this, we introduce HRET Haerae Evaluation Toolkit, an open-source, self-evolving evaluation framework tailored specifically for Korean LLMs. HRET unifies diverse evaluation methods, including logit-based scoring, exact-match, language-inconsistency penalization, and LLM-as-a-Judge assessments. Its modular, registry-based architecture integrates major benchmarks (HAE-RAE Bench, KMMLU, KUDGE, HRM8K) and multiple inference backends (vLLM, HuggingFace, OpenAI-compatible endpoints). With automated pipelines for continuous evolution, HRET provides a robust foundation for reproducible, fair, and transparent Korean NLP research.
Multi-Step Reasoning in Korean and the Emergent Mirage
Jan 10, 2025We introduce HRMCR (HAE-RAE Multi-Step Commonsense Reasoning), a benchmark designed to evaluate large language models' ability to perform multi-step reasoning in culturally specific contexts, focusing on Korean. The questions are automatically generated via templates and algorithms, requiring LLMs to integrate Korean cultural knowledge into sequential reasoning steps. Consistent with prior observations on emergent abilities, our experiments reveal that models trained on fewer than \(2 \cdot 10^{25}\) training FLOPs struggle to solve any questions, showing near-zero performance. Beyond this threshold, performance improves sharply. State-of-the-art models (e.g., O1) still score under 50\%, underscoring the difficulty of our tasks. Notably, stepwise analysis suggests the observed emergent behavior may stem from compounding errors across multiple steps rather than reflecting a genuinely new capability. We publicly release the benchmark and commit to regularly updating the dataset to prevent contamination.
Understand, Solve and Translate: Bridging the Multilingual Mathematical Reasoning Gap
Jan 05, 2025



Large language models (LLMs) demonstrate exceptional performance on complex reasoning tasks. However, despite their strong reasoning capabilities in high-resource languages (e.g., English and Chinese), a significant performance gap persists in other languages. To investigate this gap in Korean, we introduce HRM8K, a benchmark comprising 8,011 English-Korean parallel bilingual math problems. Through systematic analysis of model behaviors, we identify a key finding: these performance disparities stem primarily from difficulties in comprehending non-English inputs, rather than limitations in reasoning capabilities. Based on these findings, we propose UST (Understand, Solve, and Translate), a method that strategically uses English as an anchor for reasoning and solution generation. By fine-tuning the model on 130k synthetically generated data points, UST achieves a 10.91% improvement on the HRM8K benchmark and reduces the multilingual performance gap from 11.6% to 0.7%. Additionally, we show that improvements from UST generalize effectively to different Korean domains, demonstrating that capabilities acquired from machine-verifiable content can be generalized to other areas. We publicly release the benchmark, training dataset, and models.
Improving Fine-grained Visual Understanding in VLMs through Text-Only Training
Dec 17, 2024


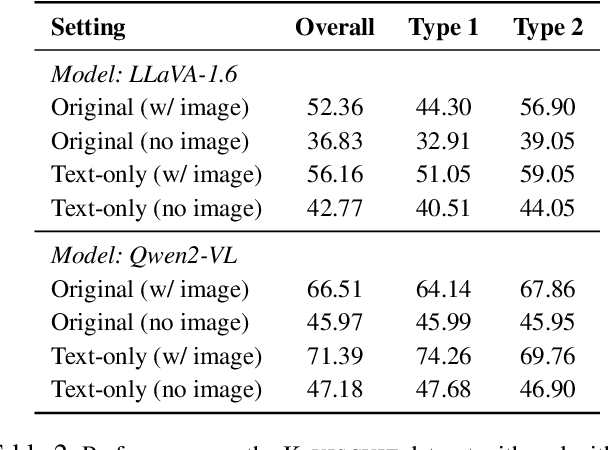
Visual-Language Models (VLMs) have become a powerful tool for bridging the gap between visual and linguistic understanding. However, the conventional learning approaches for VLMs often suffer from limitations, such as the high resource requirements of collecting and training image-text paired data. Recent research has suggested that language understanding plays a crucial role in the performance of VLMs, potentially indicating that text-only training could be a viable approach. In this work, we investigate the feasibility of enhancing fine-grained visual understanding in VLMs through text-only training. Inspired by how humans develop visual concept understanding, where rich textual descriptions can guide visual recognition, we hypothesize that VLMs can also benefit from leveraging text-based representations to improve their visual recognition abilities. We conduct comprehensive experiments on two distinct domains: fine-grained species classification and cultural visual understanding tasks. Our findings demonstrate that text-only training can be comparable to conventional image-text training while significantly reducing computational costs. This suggests a more efficient and cost-effective pathway for advancing VLM capabilities, particularly valuable in resource-constrained environments.
Towards Reliable AI Model Deployments: Multiple Input Mixup for Out-of-Distribution Detection
Dec 24, 2023Recent remarkable success in the deep-learning industries has unprecedentedly increased the need for reliable model deployment. For example, the model should alert the user if the produced model outputs might not be reliable. Previous studies have proposed various methods to solve the Out-of-Distribution (OOD) detection problem, however, they generally require a burden of resources. In this work, we propose a novel and simple method, Multiple Input Mixup (MIM). Our method can help improve the OOD detection performance with only single epoch fine-tuning. Our method does not require training the model from scratch and can be attached to the classifier simply. Despite its simplicity, our MIM shows competitive performance. Our method can be suitable for various environments because our method only utilizes the In-Distribution (ID) samples to generate the synthesized OOD data. With extensive experiments with CIFAR10 and CIFAR100 benchmarks that have been largely adopted in out-of-distribution detection fields, we have demonstrated our MIM shows comprehensively superior performance compared to the SOTA method. Especially, our method does not need additional computation on the feature vectors compared to the previous studies. All source codes are publicly available at https://github.com/ndb796/MultipleInputMixup.
Towards Machine Unlearning Benchmarks: Forgetting the Personal Identities in Facial Recognition Systems
Nov 03, 2023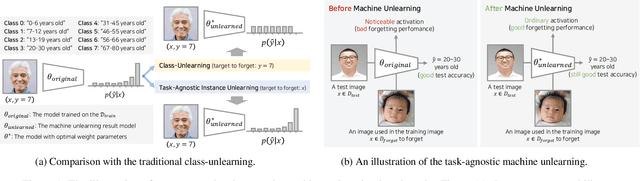

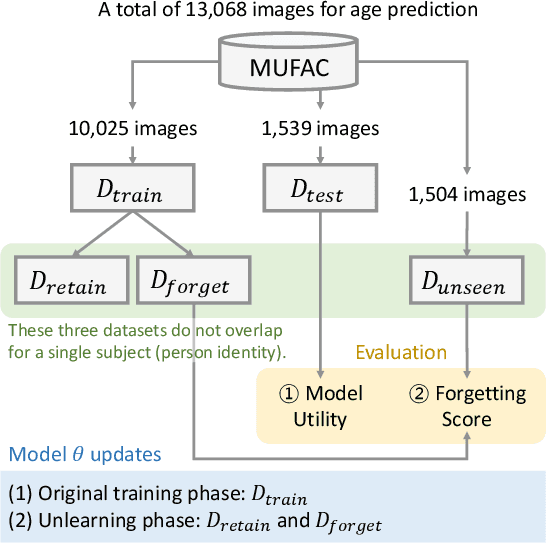

Machine unlearning is a crucial tool for enabling a classification model to forget specific data that are used in the training time. Recently, various studies have presented machine unlearning algorithms and evaluated their methods on several datasets. However, most of the current machine unlearning algorithms have been evaluated solely on traditional computer vision datasets such as CIFAR-10, MNIST, and SVHN. Furthermore, previous studies generally evaluate the unlearning methods in the class-unlearning setup. Most previous work first trains the classification models and then evaluates the machine unlearning performance of machine unlearning algorithms by forgetting selected image classes (categories) in the experiments. Unfortunately, these class-unlearning settings might not generalize to real-world scenarios. In this work, we propose a machine unlearning setting that aims to unlearn specific instance that contains personal privacy (identity) while maintaining the original task of a given model. Specifically, we propose two machine unlearning benchmark datasets, MUFAC and MUCAC, that are greatly useful to evaluate the performance and robustness of a machine unlearning algorithm. In our benchmark datasets, the original model performs facial feature recognition tasks: face age estimation (multi-class classification) and facial attribute classification (binary class classification), where a class does not depend on any single target subject (personal identity), which can be a realistic setting. Moreover, we also report the performance of the state-of-the-art machine unlearning methods on our proposed benchmark datasets. All the datasets, source codes, and trained models are publicly available at https://github.com/ndb796/MachineUnlearning.