 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Machine Unlearning Benchmarks: Forgetting the Personal Identities in Facial Recognition Systems
Paper and Code
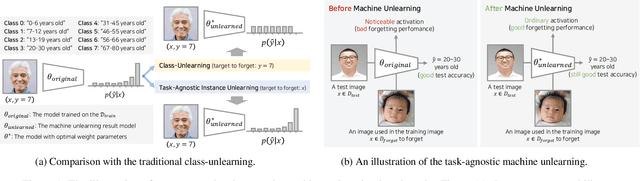

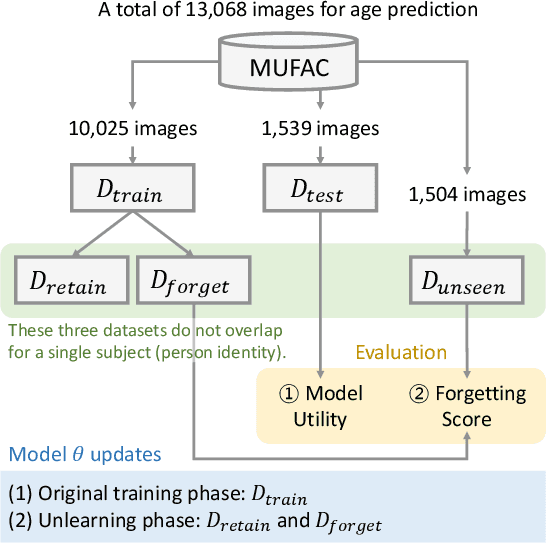

Machine unlearning is a crucial tool for enabling a classification model to forget specific data that are used in the training time. Recently, various studies have presented machine unlearning algorithms and evaluated their methods on several datasets. However, most of the current machine unlearning algorithms have been evaluated solely on traditional computer vision datasets such as CIFAR-10, MNIST, and SVHN. Furthermore, previous studies generally evaluate the unlearning methods in the class-unlearning setup. Most previous work first trains the classification models and then evaluates the machine unlearning performance of machine unlearning algorithms by forgetting selected image classes (categories) in the experiments. Unfortunately, these class-unlearning settings might not generalize to real-world scenarios. In this work, we propose a machine unlearning setting that aims to unlearn specific instance that contains personal privacy (identity) while maintaining the original task of a given model. Specifically, we propose two machine unlearning benchmark datasets, MUFAC and MUCAC, that are greatly useful to evaluate the performance and robustness of a machine unlearning algorithm. In our benchmark datasets, the original model performs facial feature recognition tasks: face age estimation (multi-class classification) and facial attribute classification (binary class classification), where a class does not depend on any single target subject (personal identity), which can be a realistic setting. Moreover, we also report the performance of the state-of-the-art machine unlearning methods on our proposed benchmark datasets. All the datasets, source codes, and trained models are publicly available at https://github.com/ndb796/MachineUnlearning.