 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Visual and Factual Correctness in LVLMs' Visualization Literacy
Jun 02, 2026Large Vision-Language Models (LVLMs) show strong visualization interpretation, yet it is unclear whether their responses reflect genuine reasoning over visual evidence or factual priors learned during training. Current evaluations mix these two sources, obscuring when correct visual interpretation is overridden by memorized facts. We present a framework that isolates visual correctness from factual correctness, revealing validity limitations in existing visualization literacy assessments. Across three experiments with 15 state-of-the-art LVLMs: (1) several models reach human-level performance on standard tests (VLAT), but this may reflect factual recall rather than visual understanding, while randomized-data tests (reVLAT) underestimate literacy when correct visual interpretation is superseded by factual priors. (2) Using our Counterfactual Visualization Literacy Assessment Test (CVLAT) with capability-normalized arbitration metrics, we classify models by the sign of their visual-factual reliance index (VFRI), revealing a visualization-oriented majority and a factual knowledge-oriented minority, though several near-zero cases warrant caution. A human baseline (N=30) on the same counterfactual items confirms that people overwhelmingly follow the chart under conflict, providing a human reference point. (3) Prompt-based intervention can shift prioritization, but its effectiveness is highly model-dependent and direction-asymmetric, and high chart-reading capability does not predict prompt-controllability. Overall, high visualization accuracy is not sufficient evidence of faithful visual reasoning: reliable integration into visual analytics requires evaluating not only visualization literacy but also how models arbitrate between visual evidence and factual priors when the two diverge. Benchmark and code: https://github.com/JaeyoungKim-HCIL/CVLAT
GhostUI: Unveiling Hidden Interactions in Mobile UI
Jan 27, 2026Modern mobile applications rely on hidden interactions--gestures without visual cues like long presses and swipes--to provide functionality without cluttering interfaces. While experienced users may discover these interactions through prior use or onboarding tutorials, their implicit nature makes them difficult for most users to uncover. Similarly, mobile agents--systems designed to automate tasks on mobile user interfaces, powered by vision language models (VLMs)--struggle to detect veiled interactions or determine actions for completing tasks. To address this challenge, we present GhostUI, a new dataset designed to enable the detection of hidden interactions in mobile applications. GhostUI provides before-and-after screenshots, simplified view hierarchies, gesture metadata, and task descriptions, allowing VLMs to better recognize concealed gestures and anticipate post-interaction states. Quantitative evaluations with VLMs show that models fine-tuned on GhostUI outperform baseline VLMs, particularly in predicting hidden interactions and inferring post-interaction screens, underscoring GhostUI's potential as a foundation for advancing mobile task automation.
Bridging Gulfs in UI Generation through Semantic Guidance
Jan 27, 2026While generative AI enables high-fidelity UI generation from text prompts, users struggle to articulate design intent and evaluate or refine results-creating gulfs of execution and evaluation. To understand the information needed for UI generation, we conducted a thematic analysis of UI prompting guidelines, identifying key design semantics and discovering that they are hierarchical and interdependent. Leveraging these findings, we developed a system that enables users to specify semantics, visualize relationships, and extract how semantics are reflected in generated UIs. By making semantics serve as an intermediate representation between human intent and AI output, our system bridges both gulfs by making requirements explicit and outcomes interpretable. A comparative user study suggests that our approach enhances users' perceived control over intent expression, outcome interpretation, and facilitates more predictable, iterative refinement. Our work demonstrates how explicit semantic representation enables systematic and explainable exploration of design possibilities in AI-driven UI design.
Measuring the Validity of Clustering Validation Datasets
Mar 03, 2025



Clustering techniques are often validated using benchmark datasets where class labels are used as ground-truth clusters. However, depending on the datasets, class labels may not align with the actual data clusters, and such misalignment hampers accurate validation. Therefore, it is essential to evaluate and compare datasets regarding their cluster-label matching (CLM), i.e., how well their class labels match actual clusters. Internal validation measures (IVMs), like Silhouette, can compare CLM over different labeling of the same dataset, but are not designed to do so across different datasets. We thus introduce Adjusted IVMs as fast and reliable methods to evaluate and compare CLM across datasets. We establish four axioms that require validation measures to be independent of data properties not related to cluster structure (e.g., dimensionality, dataset size). Then, we develop standardized protocols to convert any IVM to satisfy these axioms, and use these protocols to adjust six widely used IVMs. Quantitative experiments (1) verify the necessity and effectiveness of our protocols and (2) show that adjusted IVMs outperform the competitors, including standard IVMs, in accurately evaluating CLM both within and across datasets. We also show that the datasets can be filtered or improved using our method to form more reliable benchmarks for clustering validation.
Leveraging Multimodal LLM for Inspirational User Interface Search
Jan 30, 2025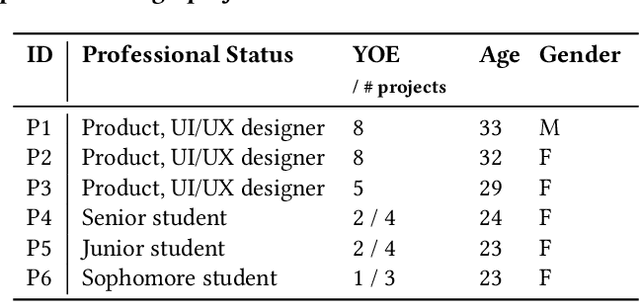
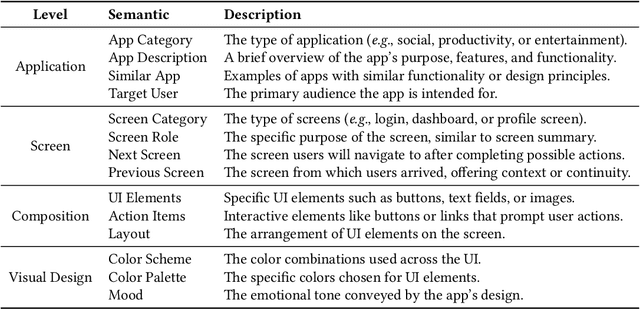

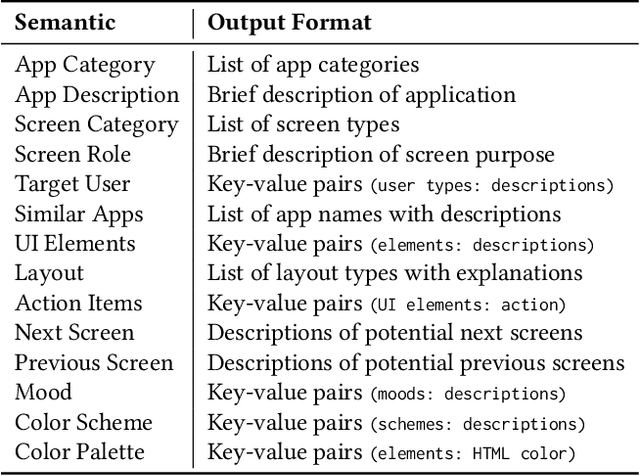
Inspirational search, the process of exploring designs to inform and inspire new creative work, is pivotal in mobile user interface (UI) design. However, exploring the vast space of UI references remains a challenge. Existing AI-based UI search methods often miss crucial semantics like target users or the mood of apps. Additionally, these models typically require metadata like view hierarchies, limiting their practical use. We used a multimodal large language model (MLLM) to extract and interpret semantics from mobile UI images. We identified key UI semantics through a formative study and developed a semantic-based UI search system. Through computational and human evaluations, we demonstrate that our approach significantly outperforms existing UI retrieval methods, offering UI designers a more enriched and contextually relevant search experience. We enhance the understanding of mobile UI design semantics and highlight MLLMs' potential in inspirational search, providing a rich dataset of UI semantics for future studies.
Assessing Graphical Perception of Image Embedding Models using Channel Effectiveness
Jul 30, 2024
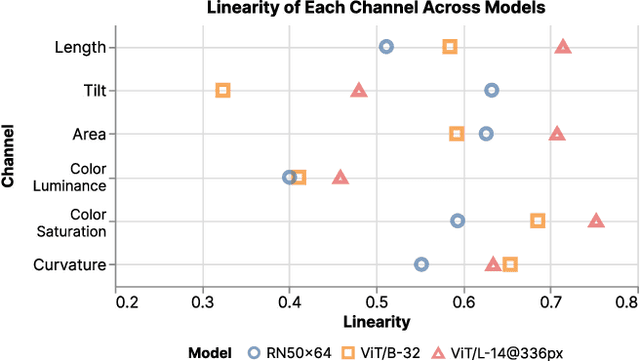


Recent advancements in vision models have greatly improved their ability to handle complex chart understanding tasks, like chart captioning and question answering. However, it remains challenging to assess how these models process charts. Existing benchmarks only roughly evaluate model performance without evaluating the underlying mechanisms, such as how models extract image embeddings. This limits our understanding of the model's ability to perceive fundamental graphical components. To address this, we introduce a novel evaluation framework to assess the graphical perception of image embedding models. For chart comprehension, we examine two main aspects of channel effectiveness: accuracy and discriminability of various visual channels. Channel accuracy is assessed through the linearity of embeddings, measuring how well the perceived magnitude aligns with the size of the stimulus. Discriminability is evaluated based on the distances between embeddings, indicating their distinctness. Our experiments with the CLIP model show that it perceives channel accuracy differently from humans and shows unique discriminability in channels like length, tilt, and curvature. We aim to develop this work into a broader benchmark for reliable visual encoders, enhancing models for precise chart comprehension and human-like perception in future applications.
Extracting Human Attention through Crowdsourced Patch Labeling
Mar 22, 2024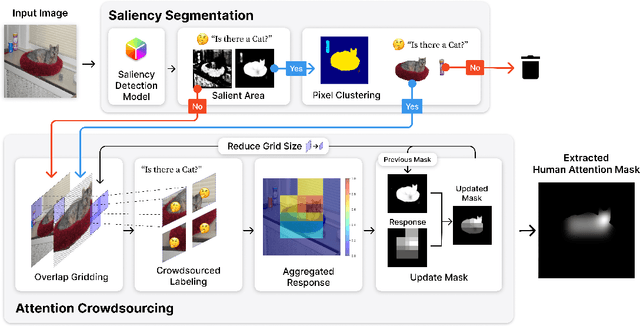


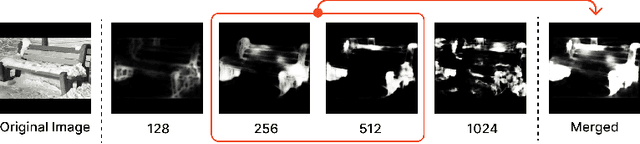
In image classification, a significant problem arises from bias in the datasets. When it contains only specific types of images, the classifier begins to rely on shortcuts - simplistic and erroneous rules for decision-making. This leads to high performance on the training dataset but inferior results on new, varied images, as the classifier's generalization capability is reduced. For example, if the images labeled as mustache consist solely of male figures, the model may inadvertently learn to classify images by gender rather than the presence of a mustache. One approach to mitigate such biases is to direct the model's attention toward the target object's location, usually marked using bounding boxes or polygons for annotation. However, collecting such annotations requires substantial time and human effort. Therefore, we propose a novel patch-labeling method that integrates AI assistance with crowdsourcing to capture human attention from images, which can be a viable solution for mitigating bias. Our method consists of two steps. First, we extract the approximate location of a target using a pre-trained saliency detection model supplemented by human verification for accuracy. Then, we determine the human-attentive area in the image by iteratively dividing the image into smaller patches and employing crowdsourcing to ascertain whether each patch can be classified as the target object. We demonstrated the effectiveness of our method in mitigating bias through improved classification accuracy and the refined focus of the model. Also, crowdsourced experiments validate that our method collects human annotation up to 3.4 times faster than annotating object locations with polygons, significantly reducing the need for human resources. We conclude the paper by discussing the advantages of our method in a crowdsourcing context, mainly focusing on aspects of human errors and accessibility.
Computational Approaches for App-to-App Retrieval and Design Consistency Check
Sep 19, 2023



Extracting semantic representations from mobile user interfaces (UI) and using the representations for designers' decision-making processes have shown the potential to be effective computational design support tools. Current approaches rely on machine learning models trained on small-sized mobile UI datasets to extract semantic vectors and use screenshot-to-screenshot comparison to retrieve similar-looking UIs given query screenshots. However, the usability of these methods is limited because they are often not open-sourced and have complex training pipelines for practitioners to follow, and are unable to perform screenshot set-to-set (i.e., app-to-app) retrieval. To this end, we (1) employ visual models trained with large web-scale images and test whether they could extract a UI representation in a zero-shot way and outperform existing specialized models, and (2) use mathematically founded methods to enable app-to-app retrieval and design consistency analysis. Our experiments show that our methods not only improve upon previous retrieval models but also enable multiple new applications.
Sanity Check for External Clustering Validation Benchmarks using Internal Validation Measures
Sep 20, 2022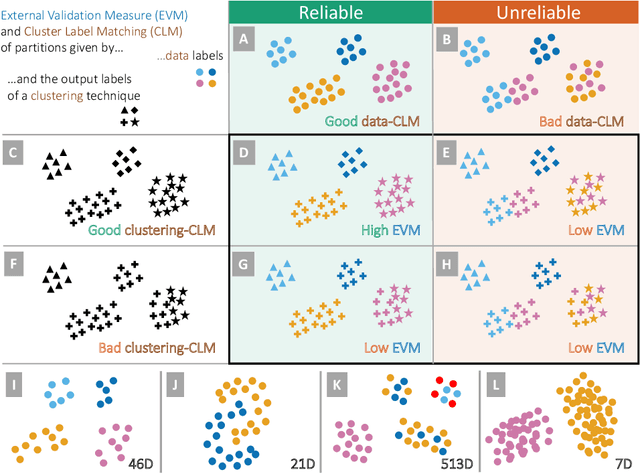
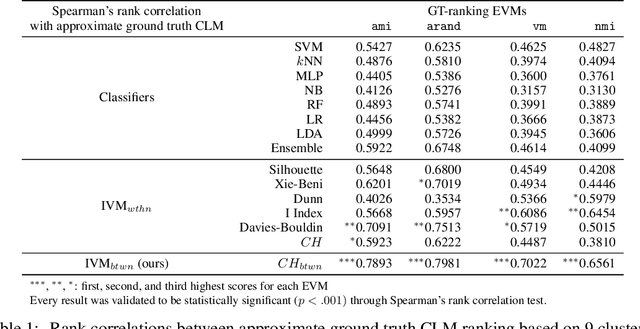
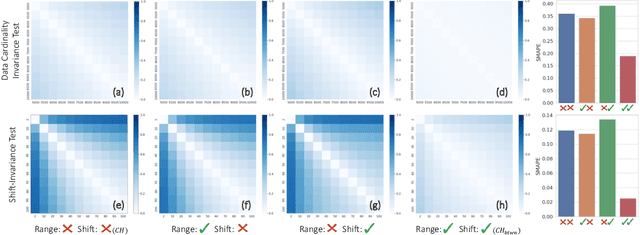
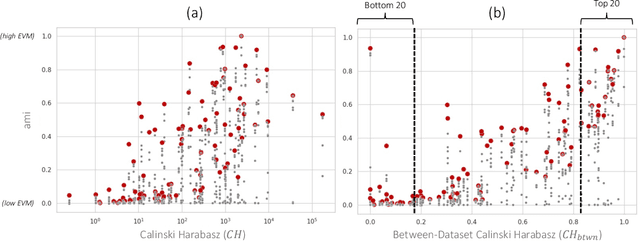
We address the lack of reliability in benchmarking clustering techniques based on labeled datasets. A standard scheme in external clustering validation is to use class labels as ground truth clusters, based on the assumption that each class forms a single, clearly separated cluster. However, as such cluster-label matching (CLM) assumption often breaks, the lack of conducting a sanity check for the CLM of benchmark datasets casts doubt on the validity of external validations. Still, evaluating the degree of CLM is challenging. For example, internal clustering validation measures can be used to quantify CLM within the same dataset to evaluate its different clusterings but are not designed to compare clusterings of different datasets. In this work, we propose a principled way to generate between-dataset internal measures that enable the comparison of CLM across datasets. We first determine four axioms for between-dataset internal measures, complementing Ackerman and Ben-David's within-dataset axioms. We then propose processes to generalize internal measures to fulfill these new axioms, and use them to extend the widely used Calinski-Harabasz index for between-dataset CLM evaluation. Through quantitative experiments, we (1) verify the validity and necessity of the generalization processes and (2) show that the proposed between-dataset Calinski-Harabasz index accurately evaluates CLM across datasets. Finally, we demonstrate the importance of evaluating CLM of benchmark datasets before conducting external validation.