 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Graphical Perception of Image Embedding Models using Channel Effectiveness
Paper and Code
Jul 30, 2024
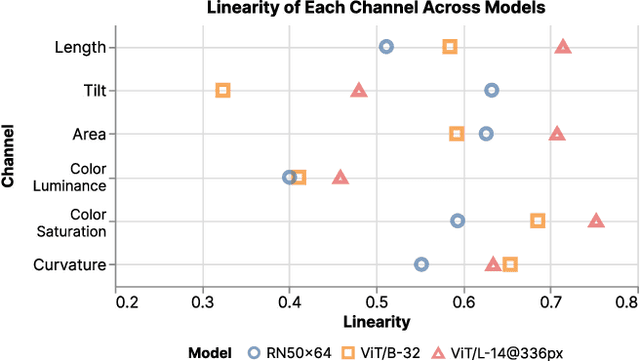


Recent advancements in vision models have greatly improved their ability to handle complex chart understanding tasks, like chart captioning and question answering. However, it remains challenging to assess how these models process charts. Existing benchmarks only roughly evaluate model performance without evaluating the underlying mechanisms, such as how models extract image embeddings. This limits our understanding of the model's ability to perceive fundamental graphical components. To address this, we introduce a novel evaluation framework to assess the graphical perception of image embedding models. For chart comprehension, we examine two main aspects of channel effectiveness: accuracy and discriminability of various visual channels. Channel accuracy is assessed through the linearity of embeddings, measuring how well the perceived magnitude aligns with the size of the stimulus. Discriminability is evaluated based on the distances between embeddings, indicating their distinctness. Our experiments with the CLIP model show that it perceives channel accuracy differently from humans and shows unique discriminability in channels like length, tilt, and curvature. We aim to develop this work into a broader benchmark for reliable visual encoders, enhancing models for precise chart comprehension and human-like perception in future applications.