 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the Validity of Clustering Validation Datasets
Mar 03, 2025



Clustering techniques are often validated using benchmark datasets where class labels are used as ground-truth clusters. However, depending on the datasets, class labels may not align with the actual data clusters, and such misalignment hampers accurate validation. Therefore, it is essential to evaluate and compare datasets regarding their cluster-label matching (CLM), i.e., how well their class labels match actual clusters. Internal validation measures (IVMs), like Silhouette, can compare CLM over different labeling of the same dataset, but are not designed to do so across different datasets. We thus introduce Adjusted IVMs as fast and reliable methods to evaluate and compare CLM across datasets. We establish four axioms that require validation measures to be independent of data properties not related to cluster structure (e.g., dimensionality, dataset size). Then, we develop standardized protocols to convert any IVM to satisfy these axioms, and use these protocols to adjust six widely used IVMs. Quantitative experiments (1) verify the necessity and effectiveness of our protocols and (2) show that adjusted IVMs outperform the competitors, including standard IVMs, in accurately evaluating CLM both within and across datasets. We also show that the datasets can be filtered or improved using our method to form more reliable benchmarks for clustering validation.
Sanity Check for External Clustering Validation Benchmarks using Internal Validation Measures
Sep 20, 2022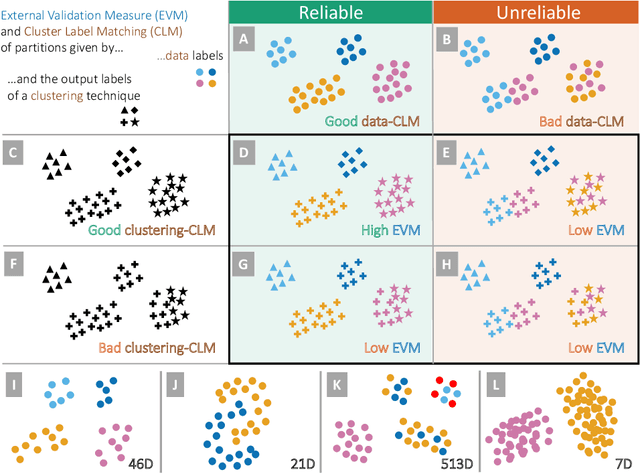
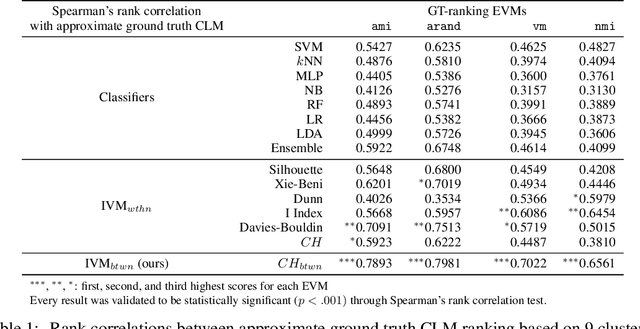
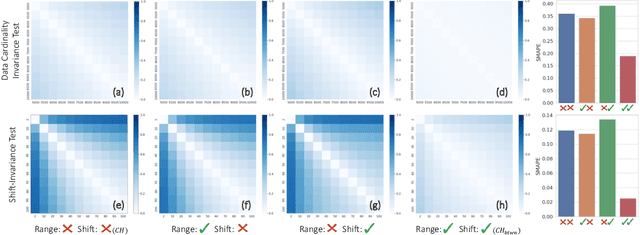
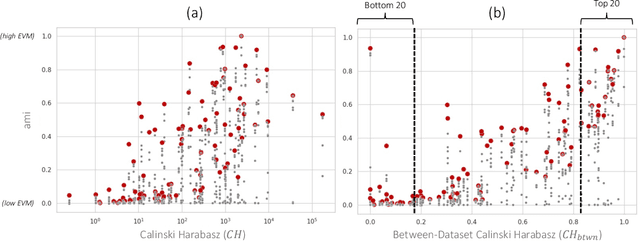
We address the lack of reliability in benchmarking clustering techniques based on labeled datasets. A standard scheme in external clustering validation is to use class labels as ground truth clusters, based on the assumption that each class forms a single, clearly separated cluster. However, as such cluster-label matching (CLM) assumption often breaks, the lack of conducting a sanity check for the CLM of benchmark datasets casts doubt on the validity of external validations. Still, evaluating the degree of CLM is challenging. For example, internal clustering validation measures can be used to quantify CLM within the same dataset to evaluate its different clusterings but are not designed to compare clusterings of different datasets. In this work, we propose a principled way to generate between-dataset internal measures that enable the comparison of CLM across datasets. We first determine four axioms for between-dataset internal measures, complementing Ackerman and Ben-David's within-dataset axioms. We then propose processes to generalize internal measures to fulfill these new axioms, and use them to extend the widely used Calinski-Harabasz index for between-dataset CLM evaluation. Through quantitative experiments, we (1) verify the validity and necessity of the generalization processes and (2) show that the proposed between-dataset Calinski-Harabasz index accurately evaluates CLM across datasets. Finally, we demonstrate the importance of evaluating CLM of benchmark datasets before conducting external validation.