 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDropBP: Accelerating Fine-Tuning of Large Language Models by Dropping Backward Propagation
Feb 27, 2024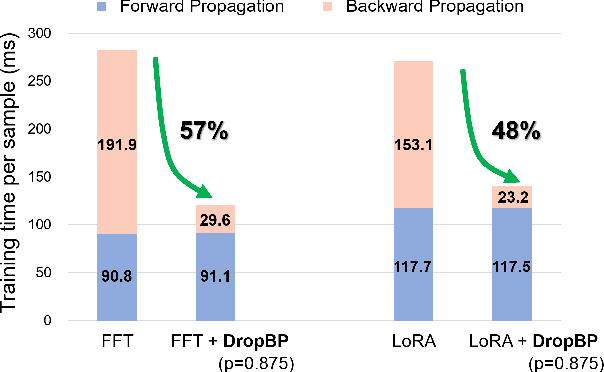

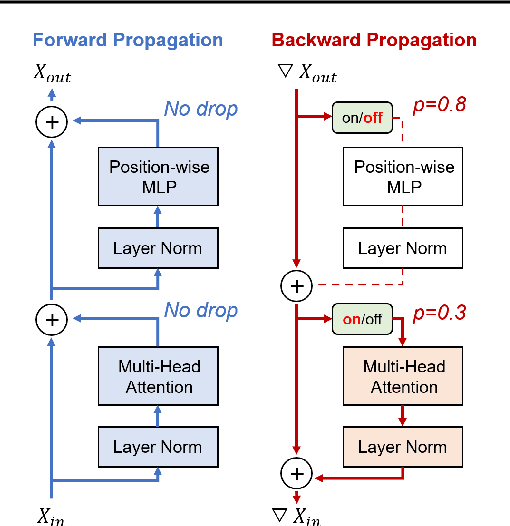

Training deep neural networks typically involves substantial computational costs during both forward and backward propagation. The conventional layer dropping techniques drop certain layers during training for reducing the computations burden. However, dropping layers during forward propagation adversely affects the training process by degrading accuracy. In this paper, we propose Dropping Backward Propagation (DropBP), a novel approach designed to reduce computational costs while maintaining accuracy. DropBP randomly drops layers during the backward propagation, which does not deviate forward propagation. Moreover, DropBP calculates the sensitivity of each layer to assign appropriate drop rate, thereby stabilizing the training process. DropBP is designed to enhance the efficiency of the training process with backpropagation, thereby enabling the acceleration of both full fine-tuning and parameter-efficient fine-tuning using backpropagation. Specifically, utilizing DropBP in QLoRA reduces training time by 44%, increases the convergence speed to the identical loss level by 1.5$\times$, and enables training with a 6.2$\times$ larger sequence length on a single NVIDIA-A100 80GiB GPU in LLaMA2-70B. The code is available at https://github.com/WooSunghyeon/dropbp.
Real-time Denoising and Dereverberation with Tiny Recurrent U-Net
Feb 10, 2021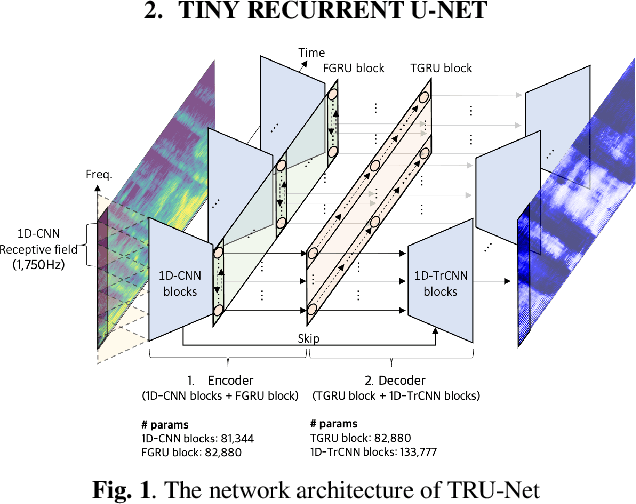
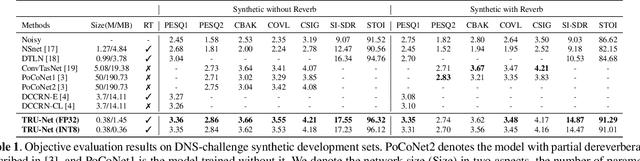
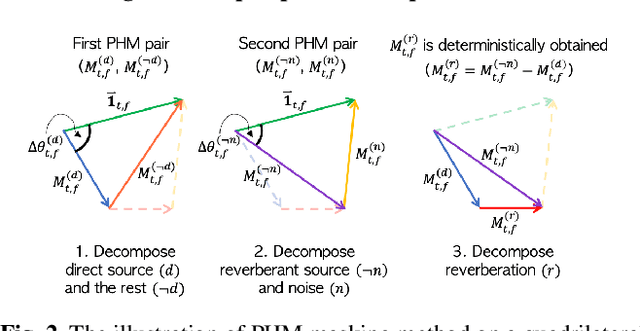
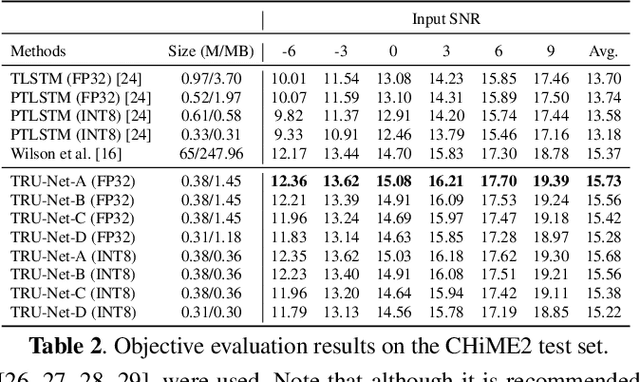
Modern deep learning-based models have seen outstanding performance improvement with speech enhancement tasks. The number of parameters of state-of-the-art models, however, is often too large to be deployed on devices for real-world applications. To this end, we propose Tiny Recurrent U-Net (TRU-Net), a lightweight online inference model that matches the performance of current state-of-the-art models. The size of the quantized version of TRU-Net is 362 kilobytes, which is small enough to be deployed on edge devices. In addition, we combine the small-sized model with a new masking method called phase-aware $\beta$-sigmoid mask, which enables simultaneous denoising and dereverberation. Results of both objective and subjective evaluations have shown that our model can achieve competitive performance with the current state-of-the-art models on benchmark datasets using fewer parameters by orders of magnitude.