 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of On-Device Translation for Real-Time Live-Stream Chat on Mobile Devices
Jan 06, 2026Despite its efficiency, there has been little research on the practical aspects required for real-world deployment of on-device AI models, such as the device's CPU utilization and thermal conditions. In this paper, through extensive experiments, we investigate two key issues that must be addressed to deploy on-device models in real-world services: (i) the selection of on-device models and the resource consumption of each model, and (ii) the capability and potential of on-device models for domain adaptation. To this end, we focus on a task of translating live-stream chat messages and manually construct LiveChatBench, a benchmark consisting of 1,000 Korean-English parallel sentence pairs. Experiments on five mobile devices demonstrate that, although serving a large and heterogeneous user base requires careful consideration of highly constrained deployment settings and model selection, the proposed approach nevertheless achieves performance comparable to commercial models such as GPT-5.1 on the well-targeted task. We expect that our findings will provide meaningful insights to the on-device AI community.
ChatLang-8: An LLM-Based Synthetic Data Generation Framework for Grammatical Error Correction
Jun 05, 2024We explore and improve the capabilities of LLMs to generate data for grammatical error correction (GEC). When merely producing parallel sentences, their patterns are too simplistic to be valuable as a corpus. To address this issue, we propose an automated framework that includes a Subject Selector, Grammar Selector, Prompt Manager, and Evaluator. Additionally, we introduce a new dataset for GEC tasks, named \textbf{ChatLang-8}, which encompasses eight types of subject nouns and 23 types of grammar. It consists of 1 million pairs featuring human-like grammatical errors. Our experiments reveal that ChatLang-8 exhibits a more uniform pattern composition compared to existing GEC datasets. Furthermore, we observe improved model performance when using ChatLang-8 instead of existing GEC datasets. The experimental results suggest that our framework and ChatLang-8 are valuable resources for enhancing ChatGPT's data generation capabilities.
Enhancing Consistency and Role-Specific Knowledge Capturing by Rebuilding Fictional Character's Persona
Jun 01, 2024With the recent introduction of Assistants API, it is expected that document-based language models will be actively used in various domains, especially Role-playing. However, a key challenge lies in utilizing protagonist's persona: Assistants API often fails to achieve with its search because the information extraction part is different each time and it often omits important information such as protagonist's backstory or relationships. It is hard to maintain a consistent persona simply by using the persona document as input to the Assistants API. To address the challenge of achieving stable persona consistency, we propose CharacterGPT, a novel persona reconstruction framework to alleviate the shortcomings of the Assistants API. Our method involves Character Persona Training (CPT), an effective persona rebuilding process that updates the character persona by extracting the character's traits from given summary of the novel for each character as if the story in a novel progresses. In our experiments, we ask each character to take the Big Five Inventory personality test in various settings and analyze the results. To assess whether it can think outside the box, we let each character generate short novels. Extensive experiments and human evaluation demonstrate that CharacterGPT presents new possibilities for role-playing agent research.
Analysis of Utterance Embeddings and Clustering Methods Related to Intent Induction for Task-Oriented Dialogue
Dec 06, 2022

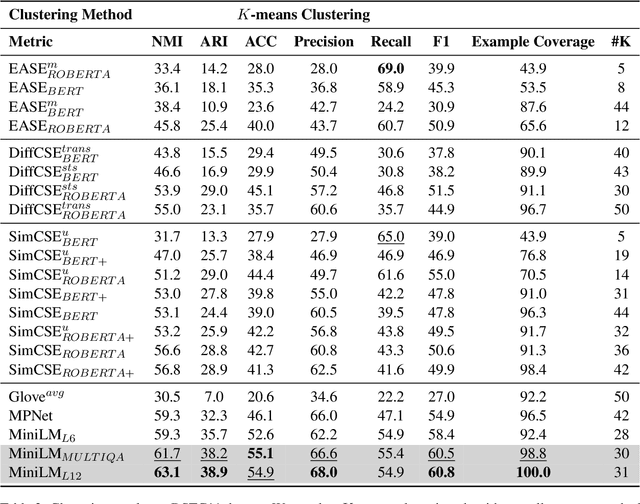

This paper investigates unsupervised approaches to overcome quintessential challenges in designing task-oriented dialog schema: assigning intent labels to each dialog turn (intent clustering) and generating a set of intents based on the intent clustering methods (intent induction). We postulate there are two salient factors for automatic induction of intents: (1) clustering algorithm for intent labeling and (2) user utterance embedding space. We compare existing off-the-shelf clustering models and embeddings based on DSTC11 evaluation. Our extensive experiments demonstrate that we sholud add two huge caveat that selection of utterance embedding and clustering method in intent induction task should be very careful. We also present that pretrained MiniLM with Agglomerative clustering shows significant improvement in NMI, ARI, F1, accuracy and example coverage in intent induction tasks. The source code for reimplementation will be available at Github.
Multimodal Frame-Scoring Transformer for Video Summarization
Jul 05, 2022
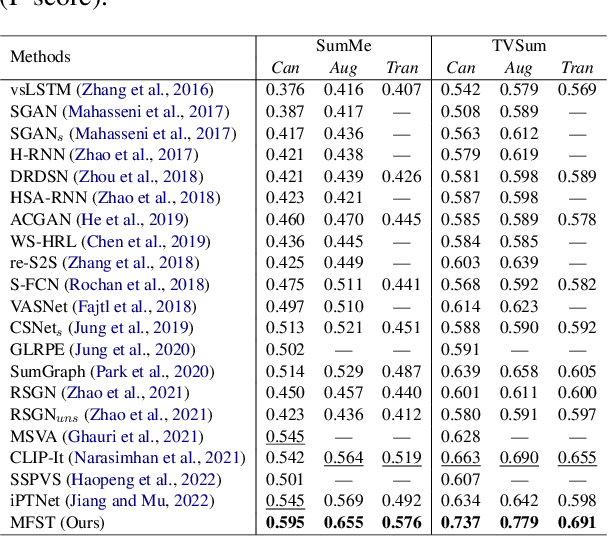
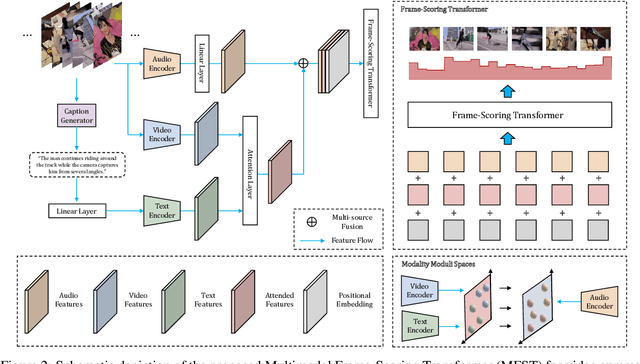
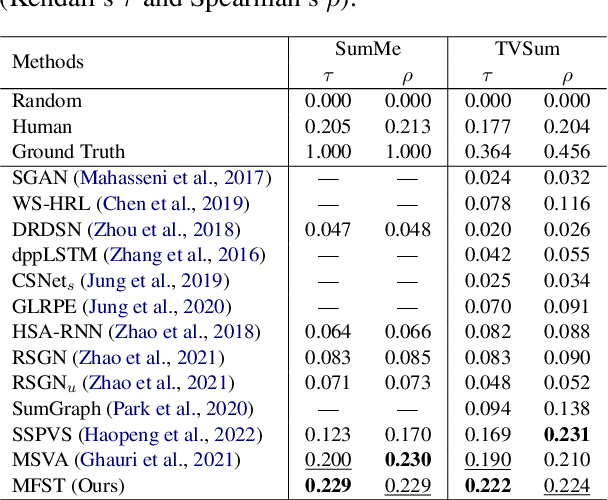
As the number of video content has mushroomed in recent years, automatic video summarization has come useful when we want to just peek at the content of the video. However, there are two underlying limitations in generic video summarization task. First, most previous approaches read in just visual features as input, leaving other modality features behind. Second, existing datasets for generic video summarization are relatively insufficient to train a caption generator and multimodal feature extractors. To address these two problems, this paper proposes the Multimodal Frame-Scoring Transformer (MFST) framework exploiting visual, text and audio features and scoring a video with respect to frames. Our MFST framework first extracts each modality features (visual-text-audio) using pretrained encoders. Then, MFST trains the multimodal frame-scoring transformer that uses video-text-audio representations as inputs and predicts frame-level scores. Our extensive experiments with previous models and ablation studies on TVSum and SumMe datasets demonstrate the effectiveness and superiority of our proposed method.
Variational Reward Estimator Bottleneck: Learning Robust Reward Estimator for Multi-Domain Task-Oriented Dialog
May 31, 2020
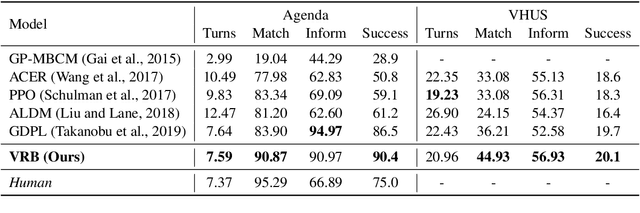
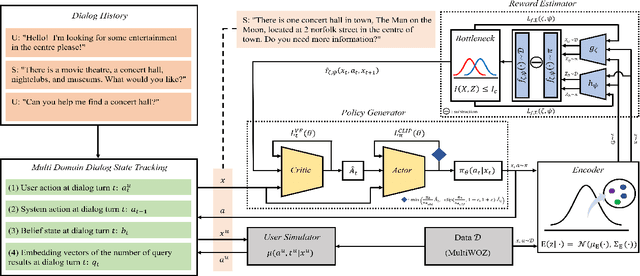
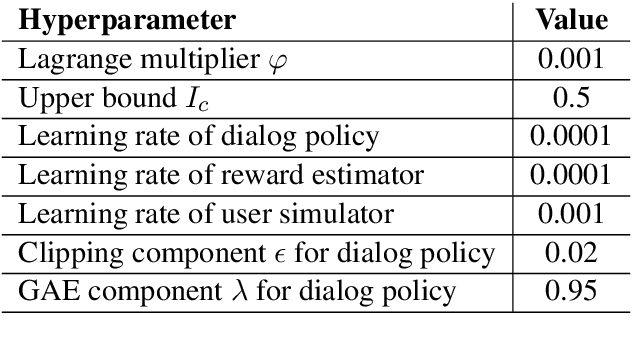
Despite its notable success in adversarial learning approaches to multi-domain task-oriented dialog system, training the dialog policy via adversarial inverse reinforcement learning often fails to balance the performance of the policy generator and reward estimator. During optimization, the reward estimator often overwhelms the policy generator and produces excessively uninformative gradients. We proposes the Variational Reward estimator Bottleneck (VRB), which is an effective regularization method that aims to constrain unproductive information flows between inputs and the reward estimator. The VRB focuses on capturing discriminative features, by exploiting information bottleneck on mutual information. Empirical results on a multi-domain task-oriented dialog dataset demonstrate that the VRB significantly outperforms previous methods.