 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUE-M: Contextual Understanding and Enhanced Search with Multimodal Large Language Model
Nov 19, 2024
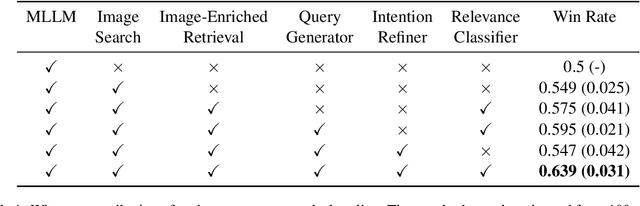
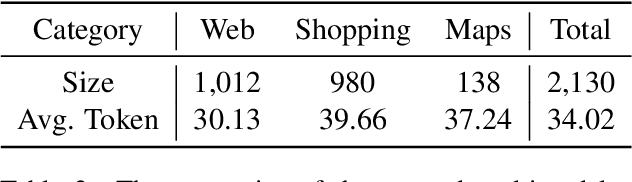
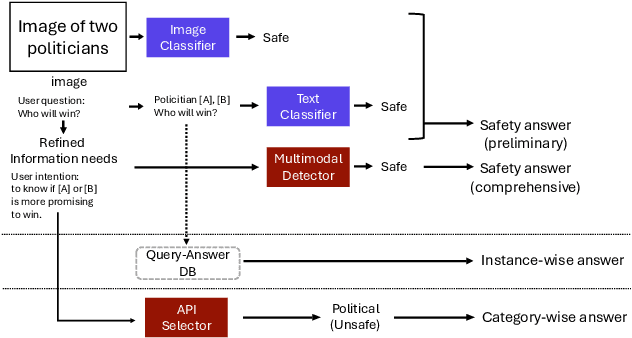
The integration of Retrieval-Augmented Generation (RAG) with Multimodal Large Language Models (MLLMs) has expanded the scope of multimodal query resolution. However, current systems struggle with intent understanding, information retrieval, and safety filtering, limiting their effectiveness. This paper introduces Contextual Understanding and Enhanced Search with MLLM (CUE-M), a novel multimodal search pipeline that addresses these challenges through a multi-stage framework comprising image context enrichment, intent refinement, contextual query generation, external API integration, and relevance-based filtering. CUE-M incorporates a robust safety framework combining image-based, text-based, and multimodal classifiers, dynamically adapting to instance- and category-specific risks. Evaluations on a multimodal Q&A dataset and a public safety benchmark demonstrate that CUE-M outperforms baselines in accuracy, knowledge integration, and safety, advancing the capabilities of multimodal retrieval systems.