 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarrating the Video: Boosting Text-Video Retrieval via Comprehensive Utilization of Frame-Level Captions
Mar 07, 2025In recent text-video retrieval, the use of additional captions from vision-language models has shown promising effects on the performance. However, existing models using additional captions often have struggled to capture the rich semantics, including temporal changes, inherent in the video. In addition, incorrect information caused by generative models can lead to inaccurate retrieval. To address these issues, we propose a new framework, Narrating the Video (NarVid), which strategically leverages the comprehensive information available from frame-level captions, the narration. The proposed NarVid exploits narration in multiple ways: 1) feature enhancement through cross-modal interactions between narration and video, 2) query-aware adaptive filtering to suppress irrelevant or incorrect information, 3) dual-modal matching score by adding query-video similarity and query-narration similarity, and 4) hard-negative loss to learn discriminative features from multiple perspectives using the two similarities from different views. Experimental results demonstrate that NarVid achieves state-of-the-art performance on various benchmark datasets.
An Evaluation Dataset and Strategy for Building Robust Multi-turn Response Selection Model
Sep 10, 2021


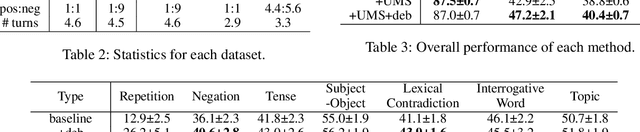
Multi-turn response selection models have recently shown comparable performance to humans in several benchmark datasets. However, in the real environment, these models often have weaknesses, such as making incorrect predictions based heavily on superficial patterns without a comprehensive understanding of the context. For example, these models often give a high score to the wrong response candidate containing several keywords related to the context but using the inconsistent tense. In this study, we analyze the weaknesses of the open-domain Korean Multi-turn response selection models and publish an adversarial dataset to evaluate these weaknesses. We also suggest a strategy to build a robust model in this adversarial environment.
Do Response Selection Models Really Know What's Next? Utterance Manipulation Strategies for Multi-turn Response Selection
Sep 10, 2020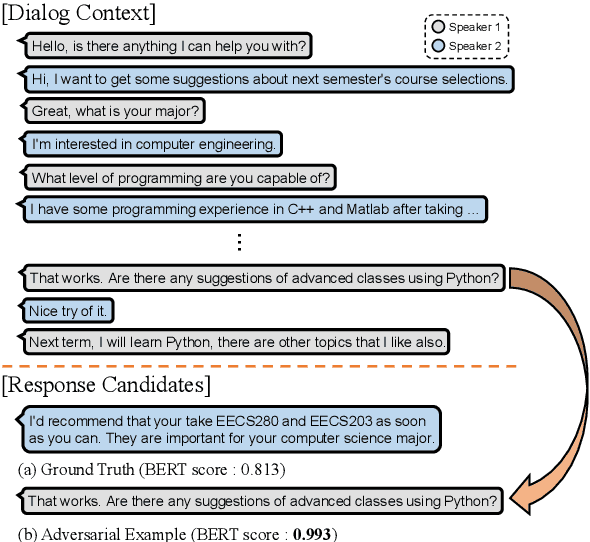

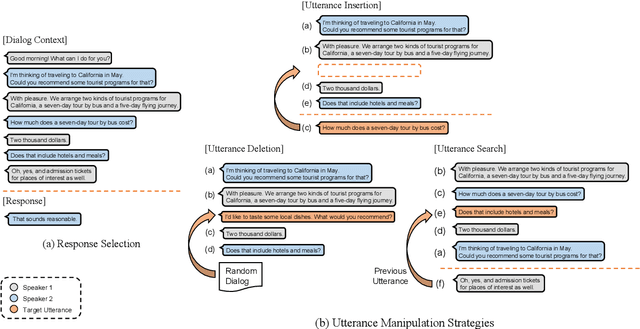
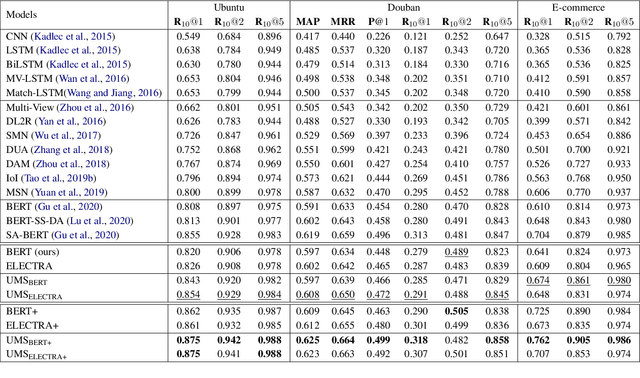
In this paper, we study the task of selecting optimal response given user and system utterance history in retrieval-based multi-turn dialog systems. Recently, pre-trained language models (e.g., BERT, RoBERTa, and ELECTRA) have shown significant improvements in various natural language processing tasks. This and similar response selection tasks can also be solved using such language models by formulating them as dialog-response binary classification tasks. Although existing works using this approach successfully obtained state-of-the-art results, we observe that language models trained in this manner tend to make predictions based on the relatedness of history and candidates, ignoring the sequential nature of multi-turn dialog systems. This suggests that the response selection task alone is insufficient in learning temporal dependencies between utterances. To this end, we propose utterance manipulation strategies (UMS) to address this problem. Specifically, UMS consist of several strategies (i.e., insertion, deletion, and search), which aid the response selection model towards maintaining dialog coherence. Further, UMS are self-supervised methods that do not require additional annotation and thus can be easily incorporated into existing approaches. Extensive evaluation across multiple languages and models shows that UMS are highly effective in teaching dialog consistency, which lead to models pushing the state-of-the-art with significant margins on multiple public benchmark datasets.