 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DreamBooth: High-Fidelity 3D Subject-Driven Video Generation Model
Mar 19, 2026Creating dynamic, view-consistent videos of customized subjects is highly sought after for a wide range of emerging applications, including immersive VR/AR, virtual production, and next-generation e-commerce. However, despite rapid progress in subject-driven video generation, existing methods predominantly treat subjects as 2D entities, focusing on transferring identity through single-view visual features or textual prompts. Because real-world subjects are inherently 3D, applying these 2D-centric approaches to 3D object customization reveals a fundamental limitation: they lack the comprehensive spatial priors necessary to reconstruct the 3D geometry. Consequently, when synthesizing novel views, they must rely on generating plausible but arbitrary details for unseen regions, rather than preserving the true 3D identity. Achieving genuine 3D-aware customization remains challenging due to the scarcity of multi-view video datasets. While one might attempt to fine-tune models on limited video sequences, this often leads to temporal overfitting. To resolve these issues, we introduce a novel framework for 3D-aware video customization, comprising 3DreamBooth and 3Dapter. 3DreamBooth decouples spatial geometry from temporal motion through a 1-frame optimization paradigm. By restricting updates to spatial representations, it effectively bakes a robust 3D prior into the model without the need for exhaustive video-based training. To enhance fine-grained textures and accelerate convergence, we incorporate 3Dapter, a visual conditioning module. Following single-view pre-training, 3Dapter undergoes multi-view joint optimization with the main generation branch via an asymmetrical conditioning strategy. This design allows the module to act as a dynamic selective router, querying view-specific geometric hints from a minimal reference set. Project page: https://ko-lani.github.io/3DreamBooth/
ReFeed: Retrieval Feedback-Guided Dataset Construction for Style-Aware Query Rewriting
Mar 02, 2026Retrieval systems often fail when user queries differ stylistically or semantically from the language used in domain documents. Query rewriting has been proposed to bridge this gap, improving retrieval by reformulating user queries into semantically equivalent forms. However, most existing approaches overlook the stylistic characteristics of target documents-their domain-specific phrasing, tone, and structure-which are crucial for matching real-world data distributions. We introduce a retrieval feedback-driven dataset generation framework that automatically identifies failed retrieval cases, leverages large language models to rewrite queries in the style of relevant documents, and verifies improvement through re-retrieval. The resulting corpus of (original, rewritten) query pairs enables the training of rewriter models that are explicitly aware of document style and retrieval feedback. This work highlights a new direction in data-centric information retrieval, emphasizing how feedback loops and document-style alignment can enhance the reasoning and adaptability of RAG systems in real-world, domain-specific contexts.
Decomate: Leveraging Generative Models for Co-Creative SVG Animation
Nov 09, 2025Designers often encounter friction when animating static SVG graphics, especially when the visual structure does not match the desired level of motion detail. Existing tools typically depend on predefined groupings or require technical expertise, which limits designers' ability to experiment and iterate independently. We present Decomate, a system that enables intuitive SVG animation through natural language. Decomate leverages a multimodal large language model to restructure raw SVGs into semantically meaningful, animation-ready components. Designers can then specify motions for each component via text prompts, after which the system generates corresponding HTML/CSS/JS animations. By supporting iterative refinement through natural language interaction, Decomate integrates generative AI into creative workflows, allowing animation outcomes to be directly shaped by user intent.
Gather-Scatter Mamba: Accelerating Propagation with Efficient State Space Model
Oct 01, 2025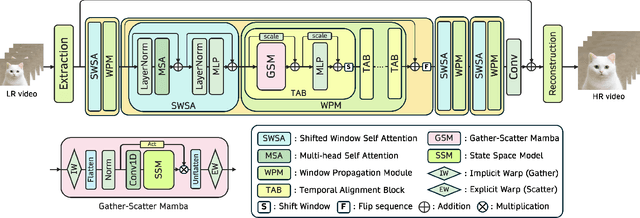
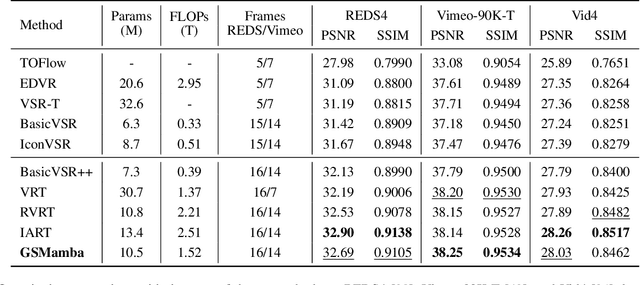
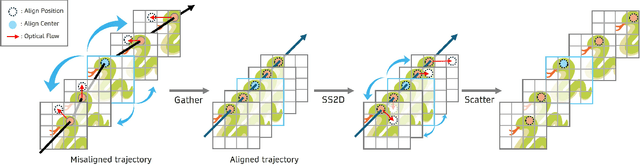
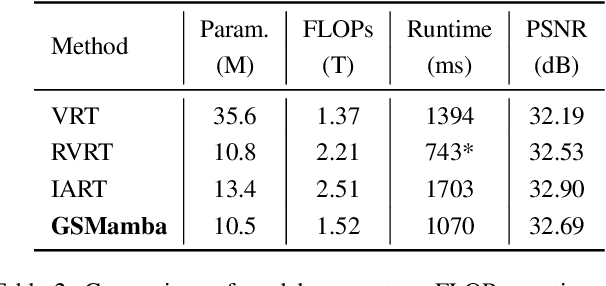
State Space Models (SSMs)-most notably RNNs-have historically played a central role in sequential modeling. Although attention mechanisms such as Transformers have since dominated due to their ability to model global context, their quadratic complexity and limited scalability make them less suited for long sequences. Video super-resolution (VSR) methods have traditionally relied on recurrent architectures to propagate features across frames. However, such approaches suffer from well-known issues including vanishing gradients, lack of parallelism, and slow inference speed. Recent advances in selective SSMs like Mamba offer a compelling alternative: by enabling input-dependent state transitions with linear-time complexity, Mamba mitigates these issues while maintaining strong long-range modeling capabilities. Despite this potential, Mamba alone struggles to capture fine-grained spatial dependencies due to its causal nature and lack of explicit context aggregation. To address this, we propose a hybrid architecture that combines shifted window self-attention for spatial context aggregation with Mamba-based selective scanning for efficient temporal propagation. Furthermore, we introduce Gather-Scatter Mamba (GSM), an alignment-aware mechanism that warps features toward a center anchor frame within the temporal window before Mamba propagation and scatters them back afterward, effectively reducing occlusion artifacts and ensuring effective redistribution of aggregated information across all frames. The official implementation is provided at: https://github.com/Ko-Lani/GSMamba.
HyST: LLM-Powered Hybrid Retrieval over Semi-Structured Tabular Data
Aug 25, 2025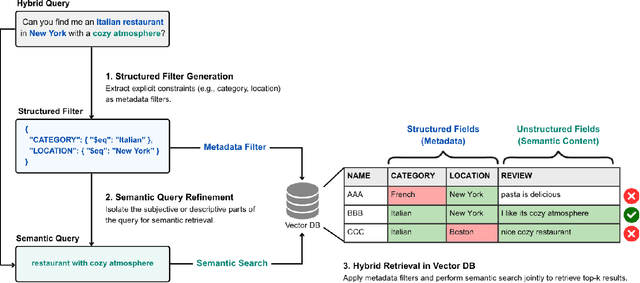

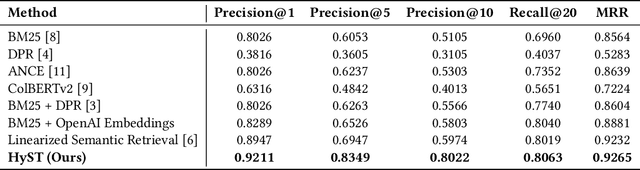

User queries in real-world recommendation systems often combine structured constraints (e.g., category, attributes) with unstructured preferences (e.g., product descriptions or reviews). We introduce HyST (Hybrid retrieval over Semi-structured Tabular data), a hybrid retrieval framework that combines LLM-powered structured filtering with semantic embedding search to support complex information needs over semi-structured tabular data. HyST extracts attribute-level constraints from natural language using large language models (LLMs) and applies them as metadata filters, while processing the remaining unstructured query components via embedding-based retrieval. Experiments on a semi-structured benchmark show that HyST consistently outperforms tradtional baselines, highlighting the importance of structured filtering in improving retrieval precision, offering a scalable and accurate solution for real-world user queries.
SelfSplat: Pose-Free and 3D Prior-Free Generalizable 3D Gaussian Splatting
Nov 26, 2024



We propose SelfSplat, a novel 3D Gaussian Splatting model designed to perform pose-free and 3D prior-free generalizable 3D reconstruction from unposed multi-view images. These settings are inherently ill-posed due to the lack of ground-truth data, learned geometric information, and the need to achieve accurate 3D reconstruction without finetuning, making it difficult for conventional methods to achieve high-quality results. Our model addresses these challenges by effectively integrating explicit 3D representations with self-supervised depth and pose estimation techniques, resulting in reciprocal improvements in both pose accuracy and 3D reconstruction quality. Furthermore, we incorporate a matching-aware pose estimation network and a depth refinement module to enhance geometry consistency across views, ensuring more accurate and stable 3D reconstructions. To present the performance of our method, we evaluated it on large-scale real-world datasets, including RealEstate10K, ACID, and DL3DV. SelfSplat achieves superior results over previous state-of-the-art methods in both appearance and geometry quality, also demonstrates strong cross-dataset generalization capabilities. Extensive ablation studies and analysis also validate the effectiveness of our proposed methods. Code and pretrained models are available at https://gynjn.github.io/selfsplat/
VISTA: Visual Integrated System for Tailored Automation in Math Problem Generation Using LLM
Nov 08, 2024



Generating accurate and consistent visual aids is a critical challenge in mathematics education, where visual representations like geometric shapes and functions play a pivotal role in enhancing student comprehension. This paper introduces a novel multi-agent framework that leverages Large Language Models (LLMs) to automate the creation of complex mathematical visualizations alongside coherent problem text. Our approach not only simplifies the generation of precise visual aids but also aligns these aids with the problem's core mathematical concepts, improving both problem creation and assessment. By integrating multiple agents, each responsible for distinct tasks such as numeric calculation, geometry validation, and visualization, our system delivers mathematically accurate and contextually relevant problems with visual aids. Evaluation across Geometry and Function problem types shows that our method significantly outperforms basic LLMs in terms of text coherence, consistency, relevance and similarity, while maintaining the essential geometrical and functional integrity of the original problems. Although some challenges remain in ensuring consistent visual outputs, our framework demonstrates the immense potential of LLMs in transforming the way educators generate and utilize visual aids in math education.
Efficient Technical Term Translation: A Knowledge Distillation Approach for Parenthetical Terminology Translation
Oct 01, 2024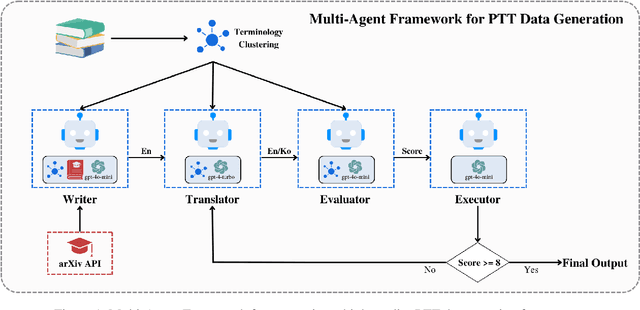

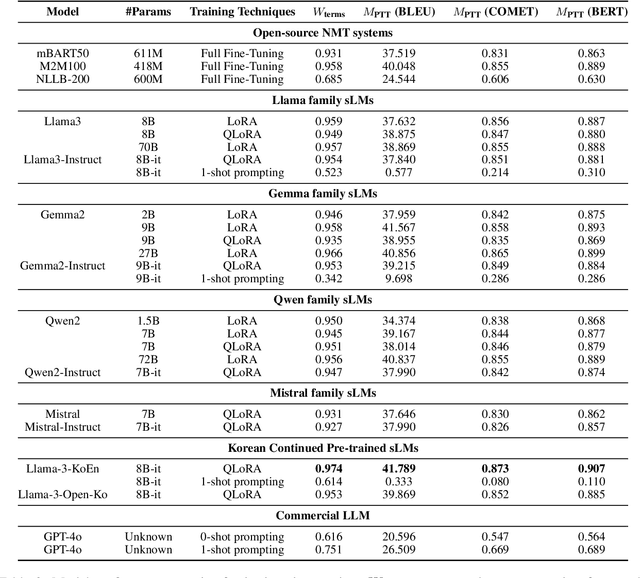
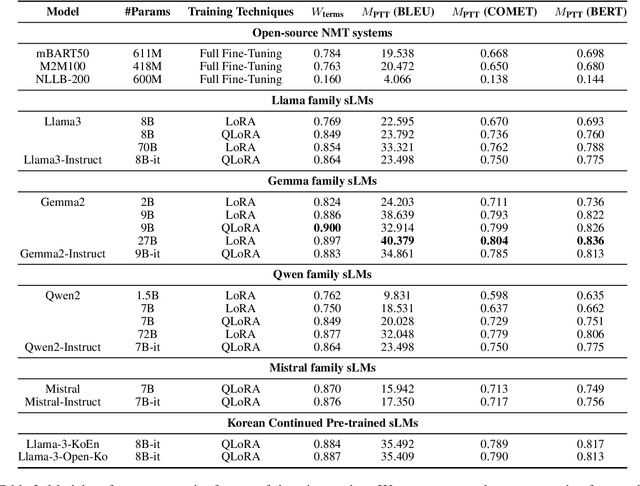
This paper addresses the challenge of accurately translating technical terms, which are crucial for clear communication in specialized fields. We introduce the Parenthetical Terminology Translation (PTT) task, designed to mitigate potential inaccuracies by displaying the original term in parentheses alongside its translation. To implement this approach, we generated a representative PTT dataset using a collaborative approach with large language models and applied knowledge distillation to fine-tune traditional Neural Machine Translation (NMT) models and small-sized Large Language Models (sLMs). Additionally, we developed a novel evaluation metric to assess both overall translation accuracy and the correct parenthetical presentation of terms. Our findings indicate that sLMs did not consistently outperform NMT models, with fine-tuning proving more effective than few-shot prompting, particularly in models with continued pre-training in the target language. These insights contribute to the advancement of more reliable terminology translation methodologies.
Inpaint Biases: A Pathway to Accurate and Unbiased Image Generation
May 29, 2024

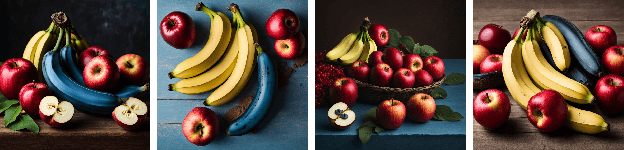

This paper examines the limitations of advanced text-to-image models in accurately rendering unconventional concepts which are scarcely represented or absent in their training datasets. We identify how these limitations not only confine the creative potential of these models but also pose risks of reinforcing stereotypes. To address these challenges, we introduce the Inpaint Biases framework, which employs user-defined masks and inpainting techniques to enhance the accuracy of image generation, particularly for novel or inaccurately rendered objects. Through experimental validation, we demonstrate how this framework significantly improves the fidelity of generated images to the user's intent, thereby expanding the models' creative capabilities and mitigating the risk of perpetuating biases. Our study contributes to the advancement of text-to-image models as unbiased, versatile tools for creative expression.