 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Semantic Segmentation with Adaptive Focal Loss: A Novel Approach
Jul 13, 2024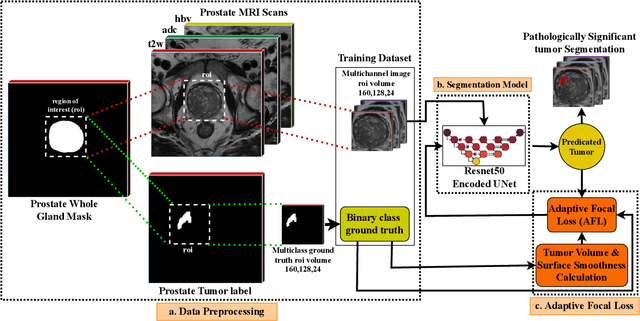



Deep learning has achieved outstanding accuracy in medical image segmentation, particularly for objects like organs or tumors with smooth boundaries or large sizes. Whereas, it encounters significant difficulties with objects that have zigzag boundaries or are small in size, leading to a notable decrease in segmentation effectiveness. In this context, using a loss function that incorporates smoothness and volume information into a model's predictions offers a promising solution to these shortcomings. In this work, we introduce an Adaptive Focal Loss (A-FL) function designed to mitigate class imbalance by down-weighting the loss for easy examples that results in up-weighting the loss for hard examples and giving greater emphasis to challenging examples, such as small and irregularly shaped objects. The proposed A-FL involves dynamically adjusting a focusing parameter based on an object's surface smoothness, size information, and adjusting the class balancing parameter based on the ratio of targeted area to total area in an image. We evaluated the performance of the A-FL using ResNet50-encoded U-Net architecture on the Picai 2022 and BraTS 2018 datasets. On the Picai 2022 dataset, the A-FL achieved an Intersection over Union (IoU) of 0.696 and a Dice Similarity Coefficient (DSC) of 0.769, outperforming the regular Focal Loss (FL) by 5.5% and 5.4% respectively. It also surpassed the best baseline Dice-Focal by 2.0% and 1.2%. On the BraTS 2018 dataset, A-FL achieved an IoU of 0.883 and a DSC of 0.931. The comparative studies show that the proposed A-FL function surpasses conventional methods, including Dice Loss, Focal Loss, and their hybrid variants, in IoU, DSC, Sensitivity, and Specificity metrics. This work highlights A-FL's potential to improve deep learning models for segmenting clinically significant regions in medical images, leading to more precise and reliable diagnostic tools.
An Empirical Study of the Relationships between Code Readability and Software Complexity
Aug 30, 2019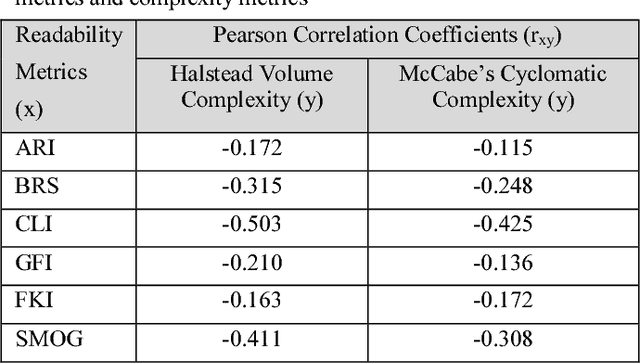
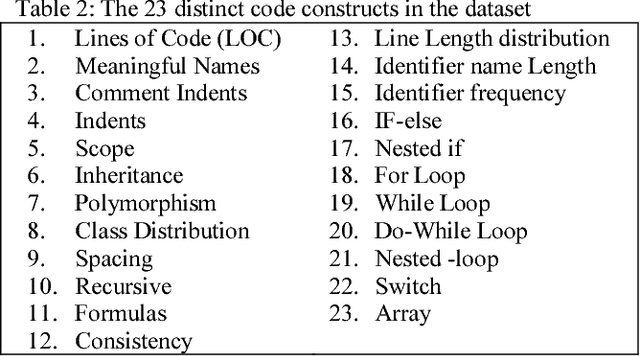
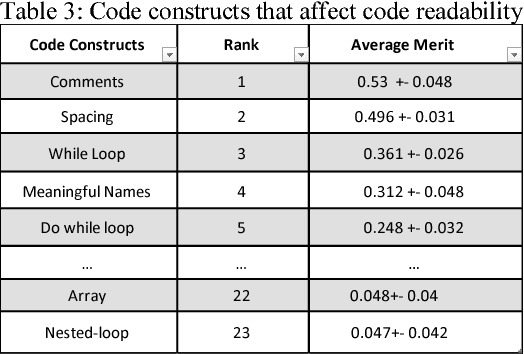
Code readability and software complexity are important software quality metrics that impact other software metrics such as maintainability, reusability, portability and reliability. This paper presents an empirical study of the relationships between code readability and program complexity. The results are derived from an analysis of 35 Java programs that cover 23 distinct code constructs. The analysis includes six readability metrics and two complexity metrics. Our study empirically confirms the existing wisdom that readability and complexity are negatively correlated. Applying a machine learning technique, we also identify and rank those code constructs that substantially affect code readability.
* 7 pages, 2 figures, 3 tables
Active Anomaly Detection via Ensembles: Insights, Algorithms, and Interpretability
Jan 23, 2019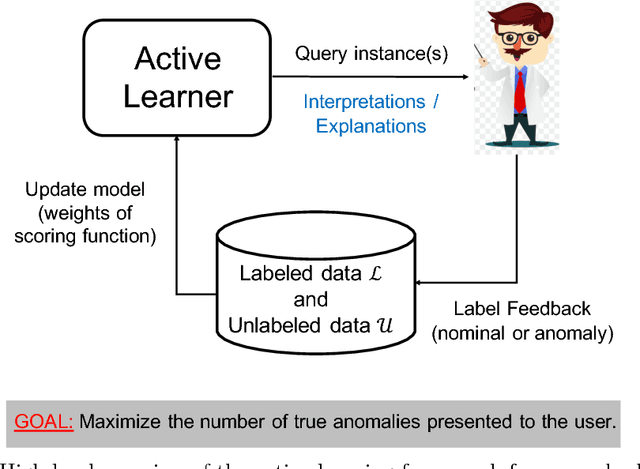
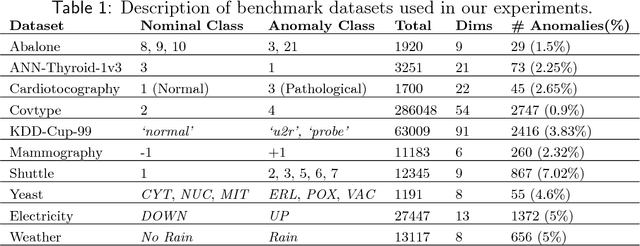
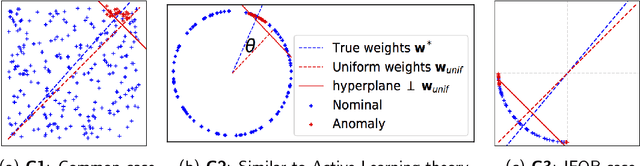
Anomaly detection (AD) task corresponds to identifying the true anomalies from a given set of data instances. AD algorithms score the data instances and produce a ranked list of candidate anomalies, which are then analyzed by a human to discover the true anomalies. However, this process can be laborious for the human analyst when the number of false-positives is very high. Therefore, in many real-world AD applications including computer security and fraud prevention, the anomaly detector must be configurable by the human analyst to minimize the effort on false positives. In this paper, we study the problem of active learning to automatically tune ensemble of anomaly detectors to maximize the number of true anomalies discovered. We make four main contributions towards this goal. First, we present an important insight that explains the practical successes of AD ensembles and how ensembles are naturally suited for active learning. Second, we present several algorithms for active learning with tree-based AD ensembles. These algorithms help us to improve the diversity of discovered anomalies, generate rule sets for improved interpretability of anomalous instances, and adapt to streaming data settings in a principled manner. Third, we present a novel algorithm called GLocalized Anomaly Detection (GLAD) for active learning with generic AD ensembles. GLAD allows end-users to retain the use of simple and understandable global anomaly detectors by automatically learning their local relevance to specific data instances using label feedback. Fourth, we present extensive experiments to evaluate our insights and algorithms. Our results show that in addition to discovering significantly more anomalies than state-of-the-art unsupervised baselines, our active learning algorithms under the streaming-data setup are competitive with the batch setup.
Active Anomaly Detection via Ensembles
Sep 17, 2018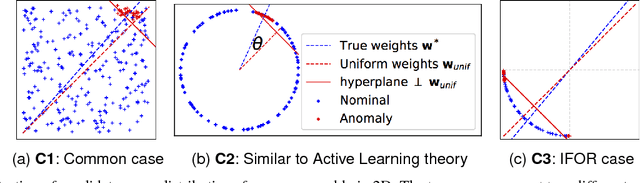
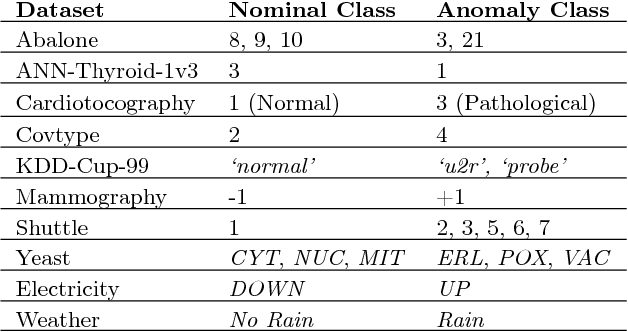
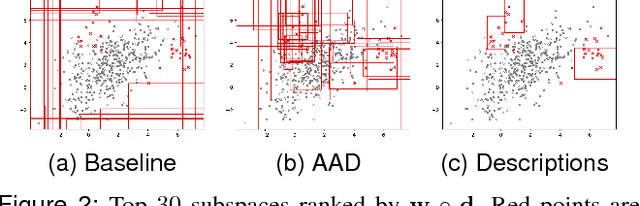
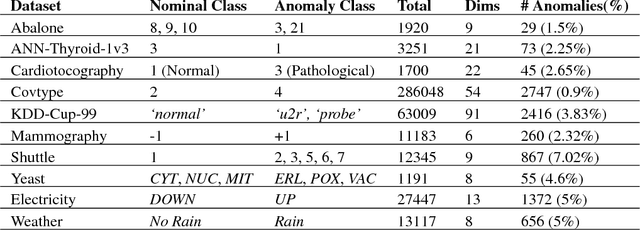
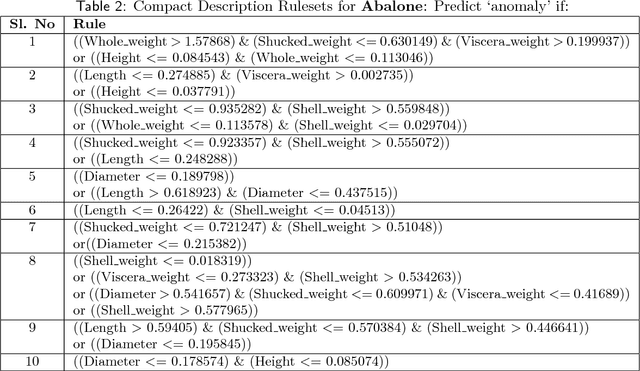
In critical applications of anomaly detection including computer security and fraud prevention, the anomaly detector must be configurable by the analyst to minimize the effort on false positives. One important way to configure the anomaly detector is by providing true labels for a few instances. We study the problem of label-efficient active learning to automatically tune anomaly detection ensembles and make four main contributions. First, we present an important insight into how anomaly detector ensembles are naturally suited for active learning. This insight allows us to relate the greedy querying strategy to uncertainty sampling, with implications for label-efficiency. Second, we present a novel formalism called compact description to describe the discovered anomalies and show that it can also be employed to improve the diversity of the instances presented to the analyst without loss in the anomaly discovery rate. Third, we present a novel data drift detection algorithm that not only detects the drift robustly, but also allows us to take corrective actions to adapt the detector in a principled manner. Fourth, we present extensive experiments to evaluate our insights and algorithms in both batch and streaming settings. Our results show that in addition to discovering significantly more anomalies than state-of-the-art unsupervised baselines, our active learning algorithms under the streaming-data setup are competitive with the batch setup.