 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpportunities in AI/ML for the Rubin LSST Dark Energy Science Collaboration
Jan 20, 2026The Vera C. Rubin Observatory's Legacy Survey of Space and Time (LSST) will produce unprecedented volumes of heterogeneous astronomical data (images, catalogs, and alerts) that challenge traditional analysis pipelines. The LSST Dark Energy Science Collaboration (DESC) aims to derive robust constraints on dark energy and dark matter from these data, requiring methods that are statistically powerful, scalable, and operationally reliable. Artificial intelligence and machine learning (AI/ML) are already embedded across DESC science workflows, from photometric redshifts and transient classification to weak lensing inference and cosmological simulations. Yet their utility for precision cosmology hinges on trustworthy uncertainty quantification, robustness to covariate shift and model misspecification, and reproducible integration within scientific pipelines. This white paper surveys the current landscape of AI/ML across DESC's primary cosmological probes and cross-cutting analyses, revealing that the same core methodologies and fundamental challenges recur across disparate science cases. Since progress on these cross-cutting challenges would benefit multiple probes simultaneously, we identify key methodological research priorities, including Bayesian inference at scale, physics-informed methods, validation frameworks, and active learning for discovery. With an eye on emerging techniques, we also explore the potential of the latest foundation model methodologies and LLM-driven agentic AI systems to reshape DESC workflows, provided their deployment is coupled with rigorous evaluation and governance. Finally, we discuss critical software, computing, data infrastructure, and human capital requirements for the successful deployment of these new methodologies, and consider associated risks and opportunities for broader coordination with external actors.
Fink: early supernovae Ia classification using active learning
Nov 22, 2021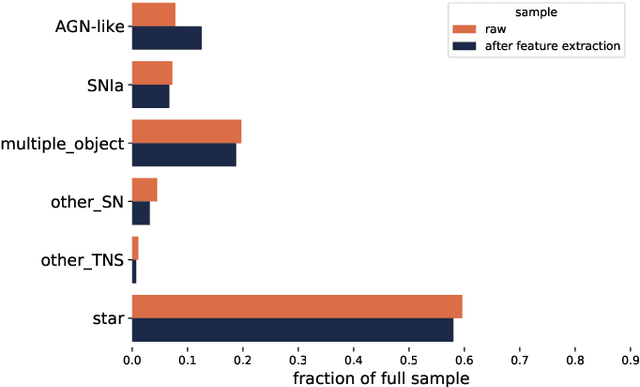
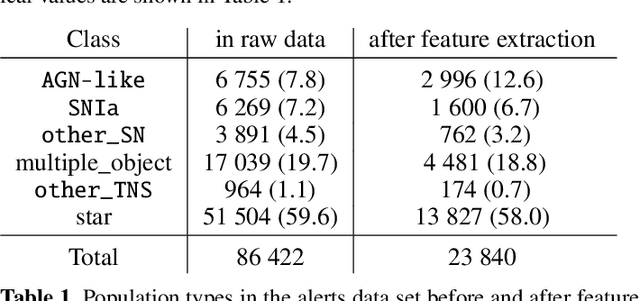
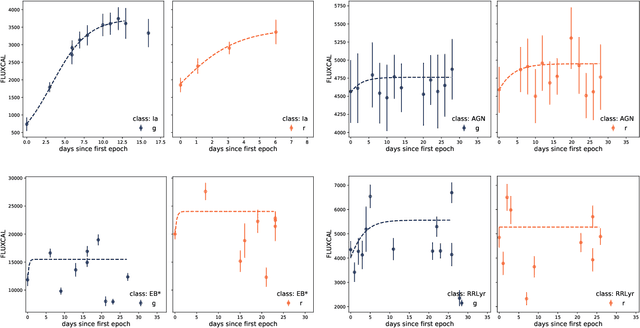

We describe how the Fink broker early supernova Ia classifier optimizes its ML classifications by employing an active learning (AL) strategy. We demonstrate the feasibility of implementation of such strategies in the current Zwicky Transient Facility (ZTF) public alert data stream. We compare the performance of two AL strategies: uncertainty sampling and random sampling. Our pipeline consists of 3 stages: feature extraction, classification and learning strategy. Starting from an initial sample of 10 alerts (5 SN Ia and 5 non-Ia), we let the algorithm identify which alert should be added to the training sample. The system is allowed to evolve through 300 iterations. Our data set consists of 23 840 alerts from the ZTF with confirmed classification via cross-match with SIMBAD database and the Transient name server (TNS), 1 600 of which were SNe Ia (1 021 unique objects). The data configuration, after the learning cycle was completed, consists of 310 alerts for training and 23 530 for testing. Averaging over 100 realizations, the classifier achieved 89% purity and 54% efficiency. From 01/November/2020 to 31/October/2021 Fink has applied its early supernova Ia module to the ZTF stream and communicated promising SN Ia candidates to the TNS. From the 535 spectroscopically classified Fink candidates, 459 (86%) were proven to be SNe Ia. Our results confirm the effectiveness of active learning strategies for guiding the construction of optimal training samples for astronomical classifiers. It demonstrates in real data that the performance of learning algorithms can be highly improved without the need of extra computational resources or overwhelmingly large training samples. This is, to our knowledge, the first application of AL to real alerts data.