 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorization: A Close Look at Books
Apr 17, 2025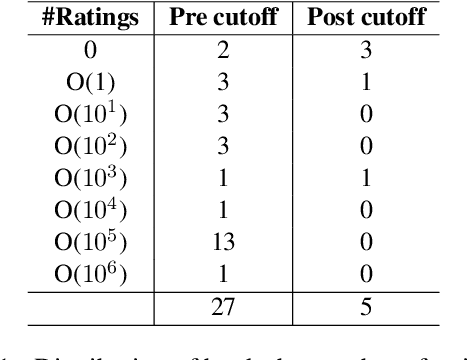
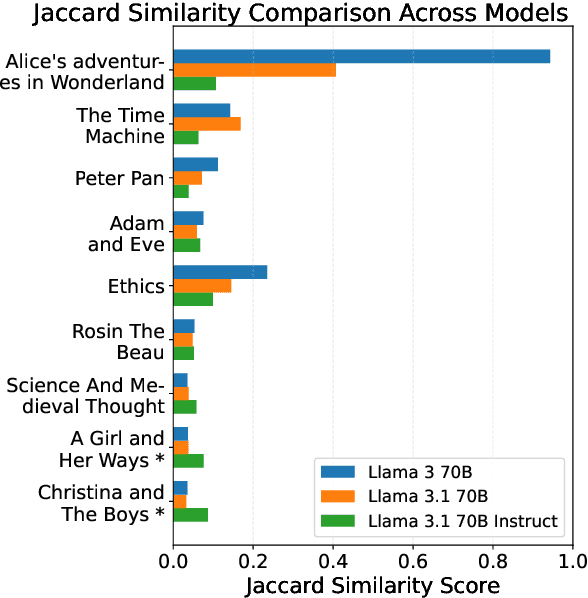
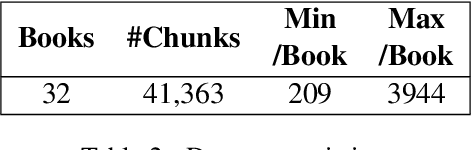
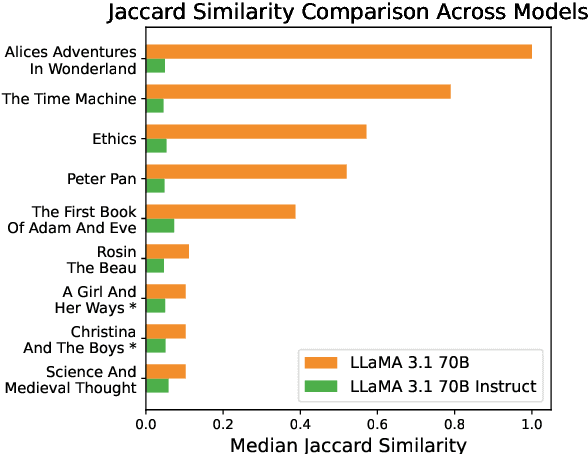
To what extent can entire books be extracted from LLMs? Using the Llama 3 70B family of models, and the "prefix-prompting" extraction technique, we were able to auto-regressively reconstruct, with a very high level of similarity, one entire book (Alice's Adventures in Wonderland) from just the first 500 tokens. We were also able to obtain high extraction rates on several other books, piece-wise. However, these successes do not extend uniformly to all books. We show that extraction rates of books correlate with book popularity and thus, likely duplication in the training data. We also confirm the undoing of mitigations in the instruction-tuned Llama 3.1, following recent work (Nasr et al., 2025). We further find that this undoing comes from changes to only a tiny fraction of weights concentrated primarily in the lower transformer blocks. Our results provide evidence of the limits of current regurgitation mitigation strategies and introduce a framework for studying how fine-tuning affects the retrieval of verbatim memorization in aligned LLMs.
From Galaxy Zoo DECaLS to BASS/MzLS: detailed galaxy morphology classification with unsupervised domain adaption
Dec 20, 2024



The DESI Legacy Imaging Surveys (DESI-LIS) comprise three distinct surveys: the Dark Energy Camera Legacy Survey (DECaLS), the Beijing-Arizona Sky Survey (BASS), and the Mayall z-band Legacy Survey (MzLS). The citizen science project Galaxy Zoo DECaLS 5 (GZD-5) has provided extensive and detailed morphology labels for a sample of 253,287 galaxies within the DECaLS survey. This dataset has been foundational for numerous deep learning-based galaxy morphology classification studies. However, due to differences in signal-to-noise ratios and resolutions between the DECaLS images and those from BASS and MzLS (collectively referred to as BMz), a neural network trained on DECaLS images cannot be directly applied to BMz images due to distributional mismatch. In this study, we explore an unsupervised domain adaptation (UDA) method that fine-tunes a source domain model trained on DECaLS images with GZD-5 labels to BMz images, aiming to reduce bias in galaxy morphology classification within the BMz survey. Our source domain model, used as a starting point for UDA, achieves performance on the DECaLS galaxies' validation set comparable to the results of related works. For BMz galaxies, the fine-tuned target domain model significantly improves performance compared to the direct application of the source domain model, reaching a level comparable to that of the source domain. We also release a catalogue of detailed morphology classifications for 248,088 galaxies within the BMz survey, accompanied by usage recommendations.
Fast emulation of cosmological density fields based on dimensionality reduction and supervised machine-learning
Apr 12, 2023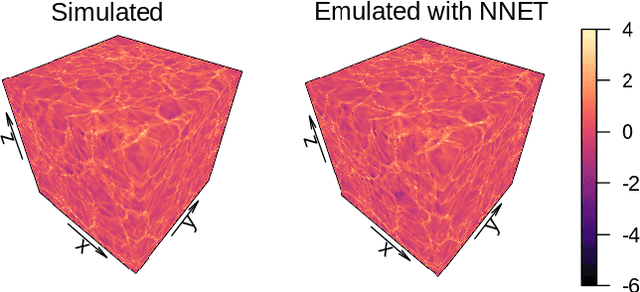
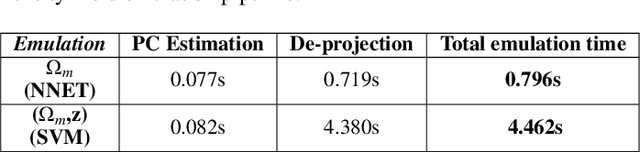
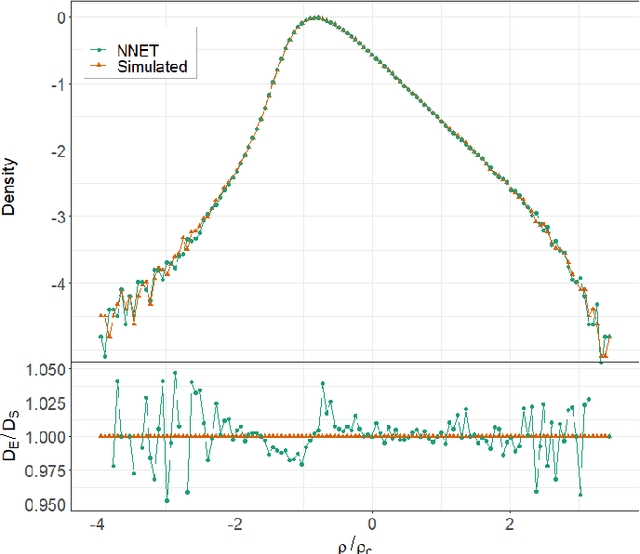
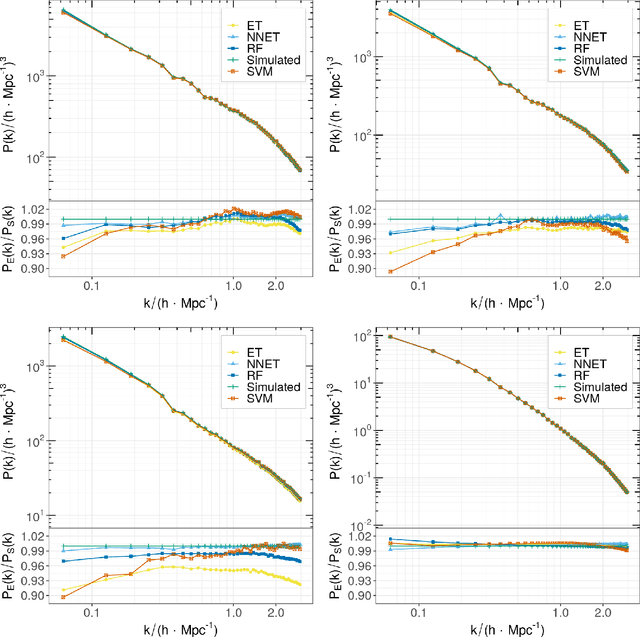
N-body simulations are the most powerful method to study the non-linear evolution of large-scale structure. However, they require large amounts of computational resources, making unfeasible their direct adoption in scenarios that require broad explorations of parameter spaces. In this work, we show that it is possible to perform fast dark matter density field emulations with competitive accuracy using simple machine-learning approaches. We build an emulator based on dimensionality reduction and machine learning regression combining simple Principal Component Analysis and supervised learning methods. For the estimations with a single free parameter, we train on the dark matter density parameter, $\Omega_m$, while for emulations with two free parameters, we train on a range of $\Omega_m$ and redshift. The method first adopts a projection of a grid of simulations on a given basis; then, a machine learning regression is trained on this projected grid. Finally, new density cubes for different cosmological parameters can be estimated without relying directly on new N-body simulations by predicting and de-projecting the basis coefficients. We show that the proposed emulator can generate density cubes at non-linear cosmological scales with density distributions within a few percent compared to the corresponding N-body simulations. The method enables gains of three orders of magnitude in CPU run times compared to performing a full N-body simulation while reproducing the power spectrum and bispectrum within $\sim 1\%$ and $\sim 3\%$, respectively, for the single free parameter emulation and $\sim 5\%$ and $\sim 15\%$ for two free parameters. This can significantly accelerate the generation of density cubes for a wide variety of cosmological models, opening the doors to previously unfeasible applications, such as parameter and model inferences at full survey scales as the ESA/NASA Euclid mission.
From Images to Features: Unbiased Morphology Classification via Variational Auto-Encoders and Domain Adaptation
Mar 15, 2023We present a novel approach for the dimensionality reduction of galaxy images by leveraging a combination of variational auto-encoders (VAE) and domain adaptation (DA). We demonstrate the effectiveness of this approach using a sample of low redshift galaxies with detailed morphological type labels from the Galaxy-Zoo DECaLS project. We show that 40-dimensional latent variables can effectively reproduce most morphological features in galaxy images. To further validate the effectiveness of our approach, we utilised a classical random forest (RF) classifier on the 40-dimensional latent variables to make detailed morphology feature classifications. This approach performs similarly to a direct neural network application on galaxy images. We further enhance our model by tuning the VAE network via DA using galaxies in the overlapping footprint of DECaLS and BASS+MzLS, enabling the unbiased application of our model to galaxy images in both surveys. We observed that noise suppression during DA led to even better morphological feature extraction and classification performance. Overall, this combination of VAE and DA can be applied to achieve image dimensionality reduction, defect image identification, and morphology classification in large optical surveys.
Active learning with RESSPECT: Resource allocation for extragalactic astronomical transients
Oct 26, 2020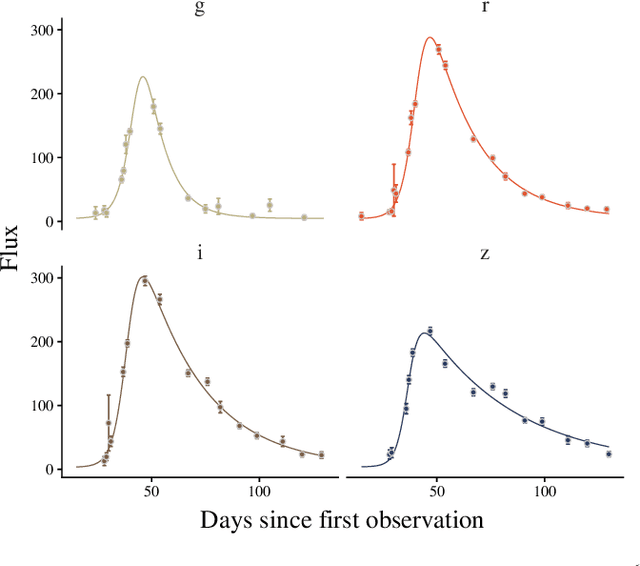
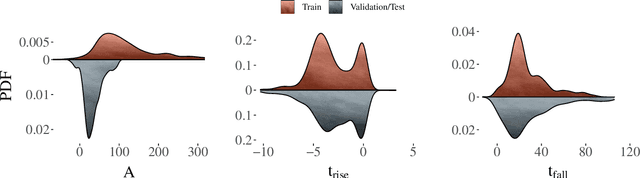
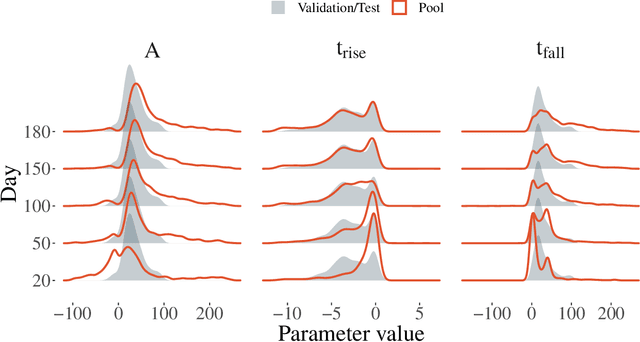
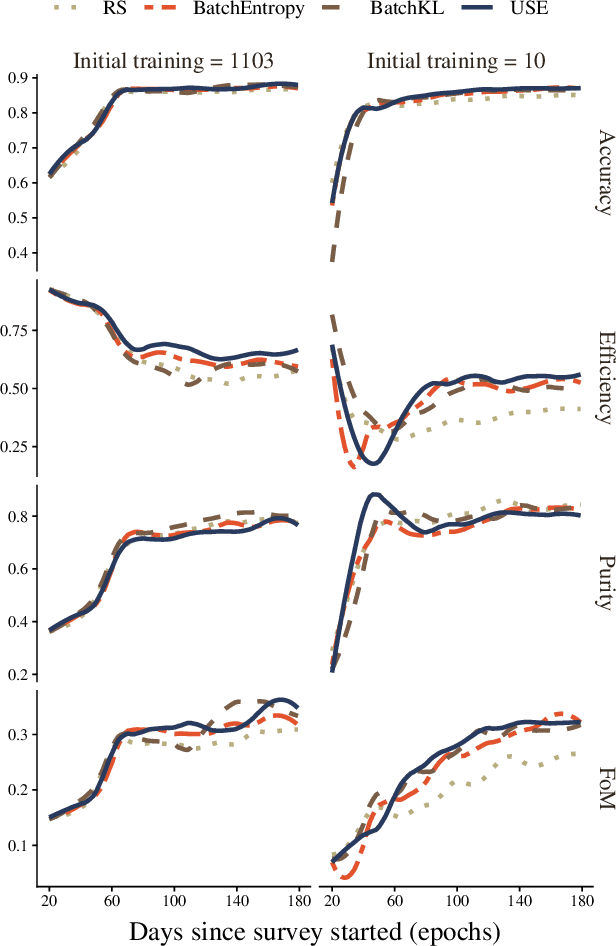
The recent increase in volume and complexity of available astronomical data has led to a wide use of supervised machine learning techniques. Active learning strategies have been proposed as an alternative to optimize the distribution of scarce labeling resources. However, due to the specific conditions in which labels can be acquired, fundamental assumptions, such as sample representativeness and labeling cost stability cannot be fulfilled. The Recommendation System for Spectroscopic follow-up (RESSPECT) project aims to enable the construction of optimized training samples for the Rubin Observatory Legacy Survey of Space and Time (LSST), taking into account a realistic description of the astronomical data environment. In this work, we test the robustness of active learning techniques in a realistic simulated astronomical data scenario. Our experiment takes into account the evolution of training and pool samples, different costs per object, and two different sources of budget. Results show that traditional active learning strategies significantly outperform random sampling. Nevertheless, more complex batch strategies are not able to significantly overcome simple uncertainty sampling techniques. Our findings illustrate three important points: 1) active learning strategies are a powerful tool to optimize the label-acquisition task in astronomy, 2) for upcoming large surveys like LSST, such techniques allow us to tailor the construction of the training sample for the first day of the survey, and 3) the peculiar data environment related to the detection of astronomical transients is a fertile ground that calls for the development of tailored machine learning algorithms.