 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorization: A Close Look at Books
Apr 17, 2025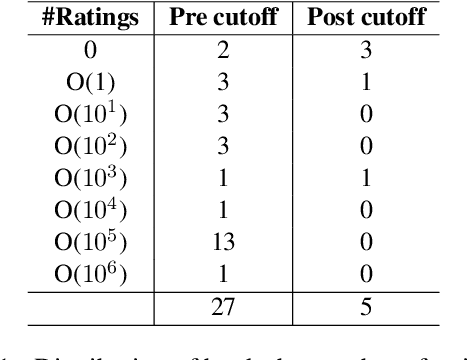
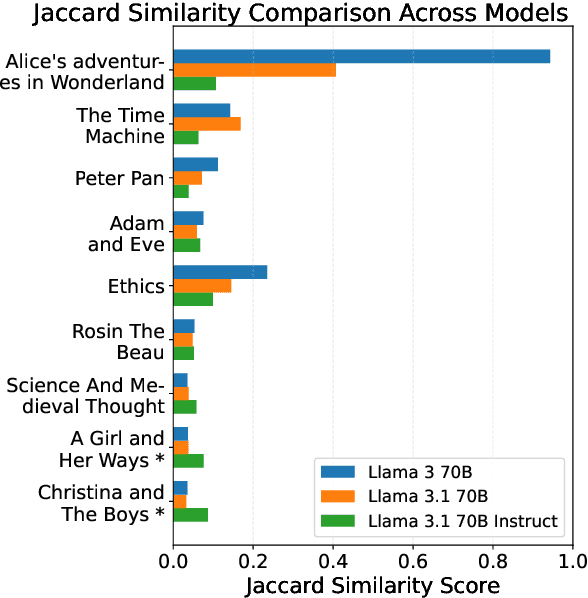
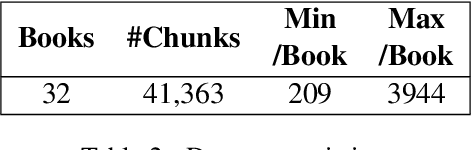
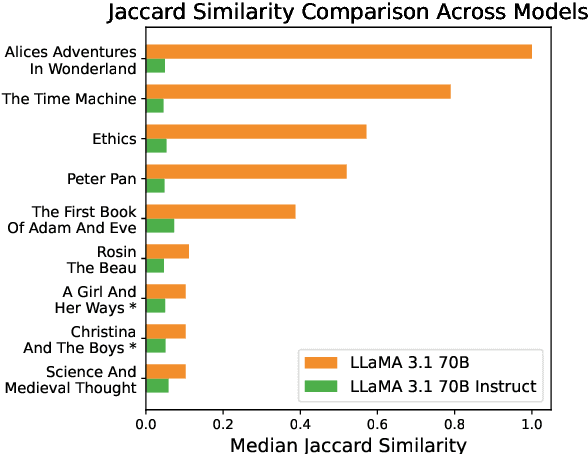
To what extent can entire books be extracted from LLMs? Using the Llama 3 70B family of models, and the "prefix-prompting" extraction technique, we were able to auto-regressively reconstruct, with a very high level of similarity, one entire book (Alice's Adventures in Wonderland) from just the first 500 tokens. We were also able to obtain high extraction rates on several other books, piece-wise. However, these successes do not extend uniformly to all books. We show that extraction rates of books correlate with book popularity and thus, likely duplication in the training data. We also confirm the undoing of mitigations in the instruction-tuned Llama 3.1, following recent work (Nasr et al., 2025). We further find that this undoing comes from changes to only a tiny fraction of weights concentrated primarily in the lower transformer blocks. Our results provide evidence of the limits of current regurgitation mitigation strategies and introduce a framework for studying how fine-tuning affects the retrieval of verbatim memorization in aligned LLMs.