 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecond FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
TCDiff: Triple Condition Diffusion Model with 3D Constraints for Stylizing Synthetic Faces
Sep 05, 2024



A robust face recognition model must be trained using datasets that include a large number of subjects and numerous samples per subject under varying conditions (such as pose, expression, age, noise, and occlusion). Due to ethical and privacy concerns, large-scale real face datasets have been discontinued, such as MS1MV3, and synthetic face generators have been proposed, utilizing GANs and Diffusion Models, such as SYNFace, SFace, DigiFace-1M, IDiff-Face, DCFace, and GANDiffFace, aiming to supply this demand. Some of these methods can produce high-fidelity realistic faces, but with low intra-class variance, while others generate high-variance faces with low identity consistency. In this paper, we propose a Triple Condition Diffusion Model (TCDiff) to improve face style transfer from real to synthetic faces through 2D and 3D facial constraints, enhancing face identity consistency while keeping the necessary high intra-class variance. Face recognition experiments using 1k, 2k, and 5k classes of our new dataset for training outperform state-of-the-art synthetic datasets in real face benchmarks such as LFW, CFP-FP, AgeDB, and BUPT. Our source code is available at: https://github.com/BOVIFOCR/tcdiff.
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024



Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
SDFR: Synthetic Data for Face Recognition Competition
Apr 09, 2024



Large-scale face recognition datasets are collected by crawling the Internet and without individuals' consent, raising legal, ethical, and privacy concerns. With the recent advances in generative models, recently several works proposed generating synthetic face recognition datasets to mitigate concerns in web-crawled face recognition datasets. This paper presents the summary of the Synthetic Data for Face Recognition (SDFR) Competition held in conjunction with the 18th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2024) and established to investigate the use of synthetic data for training face recognition models. The SDFR competition was split into two tasks, allowing participants to train face recognition systems using new synthetic datasets and/or existing ones. In the first task, the face recognition backbone was fixed and the dataset size was limited, while the second task provided almost complete freedom on the model backbone, the dataset, and the training pipeline. The submitted models were trained on existing and also new synthetic datasets and used clever methods to improve training with synthetic data. The submissions were evaluated and ranked on a diverse set of seven benchmarking datasets. The paper gives an overview of the submitted face recognition models and reports achieved performance compared to baseline models trained on real and synthetic datasets. Furthermore, the evaluation of submissions is extended to bias assessment across different demography groups. Lastly, an outlook on the current state of the research in training face recognition models using synthetic data is presented, and existing problems as well as potential future directions are also discussed.
FRCSyn Challenge at WACV 2024:Face Recognition Challenge in the Era of Synthetic Data
Nov 17, 2023



Despite the widespread adoption of face recognition technology around the world, and its remarkable performance on current benchmarks, there are still several challenges that must be covered in more detail. This paper offers an overview of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at WACV 2024. This is the first international challenge aiming to explore the use of synthetic data in face recognition to address existing limitations in the technology. Specifically, the FRCSyn Challenge targets concerns related to data privacy issues, demographic biases, generalization to unseen scenarios, and performance limitations in challenging scenarios, including significant age disparities between enrollment and testing, pose variations, and occlusions. The results achieved in the FRCSyn Challenge, together with the proposed benchmark, contribute significantly to the application of synthetic data to improve face recognition technology.
Imitating Unknown Policies via Exploration
Aug 13, 2020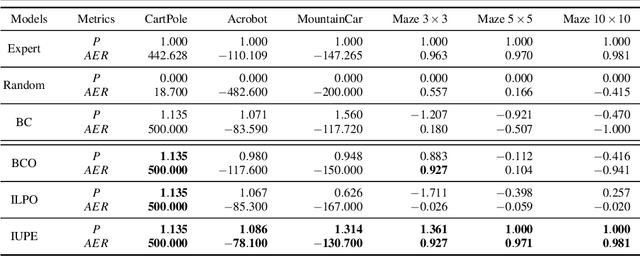
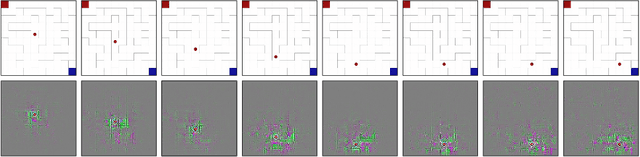

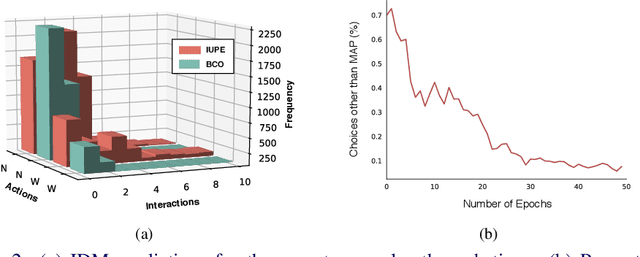
Behavioral cloning is an imitation learning technique that teaches an agent how to behave through expert demonstrations. Recent approaches use self-supervision of fully-observable unlabeled snapshots of the states to decode state-pairs into actions. However, the iterative learning scheme from these techniques are prone to getting stuck into bad local minima. We address these limitations incorporating a two-phase model into the original framework, which learns from unlabeled observations via exploration, substantially improving traditional behavioral cloning by exploiting (i) a sampling mechanism to prevent bad local minima, (ii) a sampling mechanism to improve exploration, and (iii) self-attention modules to capture global features. The resulting technique outperforms the previous state-of-the-art in four different environments by a large margin.
Augmented Behavioral Cloning from Observation
Apr 28, 2020
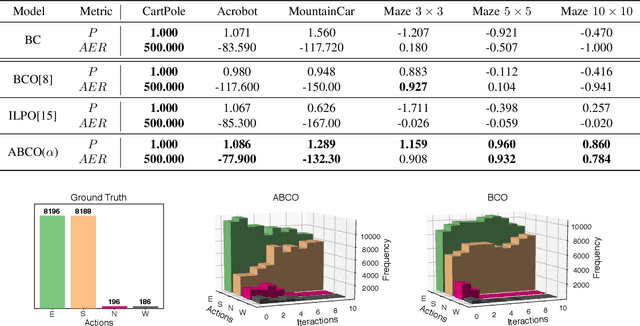

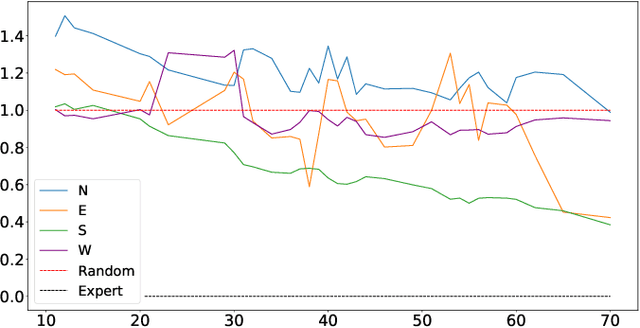
Imitation from observation is a computational technique that teaches an agent on how to mimic the behavior of an expert by observing only the sequence of states from the expert demonstrations. Recent approaches learn the inverse dynamics of the environment and an imitation policy by interleaving epochs of both models while changing the demonstration data. However, such approaches often get stuck into sub-optimal solutions that are distant from the expert, limiting their imitation effectiveness. We address this problem with a novel approach that overcomes the problem of reaching bad local minima by exploring: (I) a self-attention mechanism that better captures global features of the states; and (ii) a sampling strategy that regulates the observations that are used for learning. We show empirically that our approach outperforms the state-of-the-art approaches in four different environments by a large margin.
HAPRec: Hybrid Activity and Plan Recognizer
Apr 28, 2020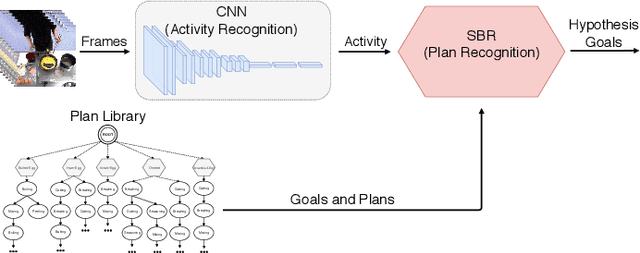
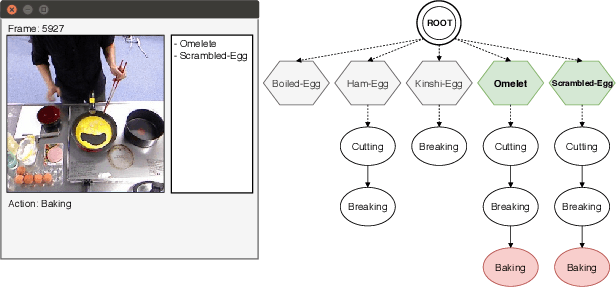
Computer-based assistants have recently attracted much interest due to its applicability to ambient assisted living. Such assistants have to detect and recognize the high-level activities and goals performed by the assisted human beings. In this work, we demonstrate activity recognition in an indoor environment in order to identify the goal towards which the subject of the video is pursuing. Our hybrid approach combines an action recognition module and a goal recognition algorithm to identify the ultimate goal of the subject in the video.
Classifying Norm Conflicts using Learned Semantic Representations
May 13, 2019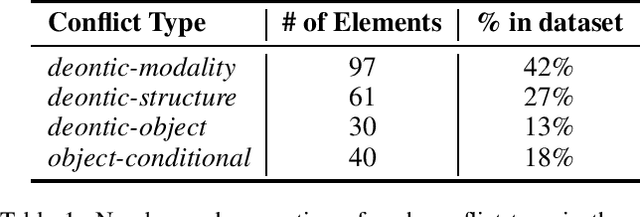
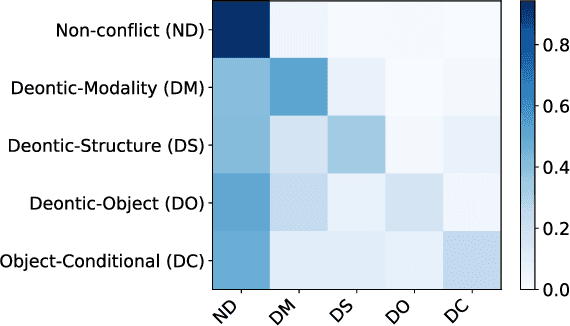
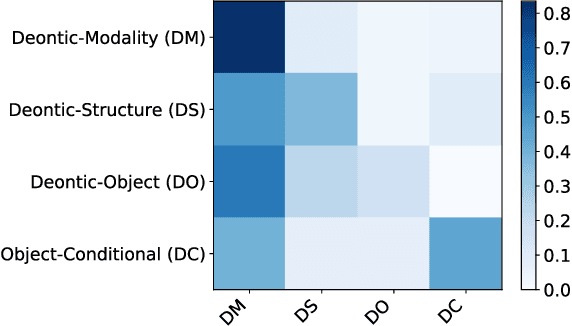
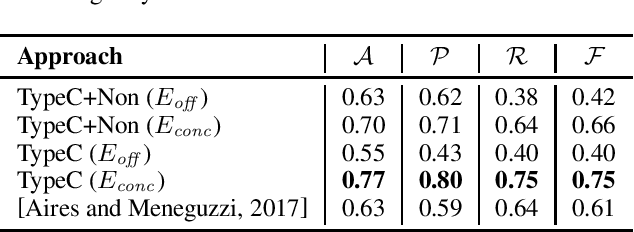
While most social norms are informal, they are often formalized by companies in contracts to regulate trades of goods and services. When poorly written, contracts may contain normative conflicts resulting from opposing deontic meanings or contradict specifications. As contracts tend to be long and contain many norms, manually identifying such conflicts requires human-effort, which is time-consuming and error-prone. Automating such task benefits contract makers increasing productivity and making conflict identification more reliable. To address this problem, we introduce an approach to detect and classify norm conflicts in contracts by converting them into latent representations that preserve both syntactic and semantic information and training a model to classify norm conflicts in four conflict types. Our results reach the new state of the art when compared to a previous approach.
Evaluating the Complementarity of Taxonomic Relation Extraction Methods Across Different Languages
Nov 08, 2018
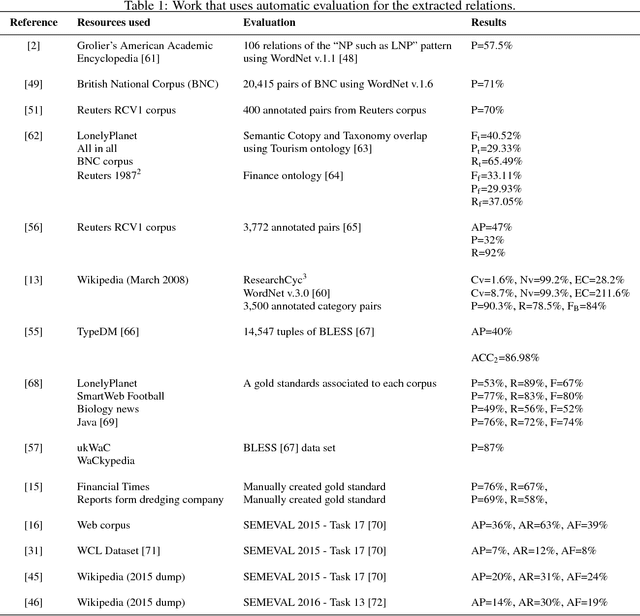


Modern information systems are changing the idea of "data processing" to the idea of "concept processing", meaning that instead of processing words, such systems process semantic concepts which carry meaning and share contexts with other concepts. Ontology is commonly used as a structure that captures the knowledge about a certain area via providing concepts and relations between them. Traditionally, concept hierarchies have been built manually by knowledge engineers or domain experts. However, the manual construction of a concept hierarchy suffers from several limitations such as its coverage and the enormous costs of its extension and maintenance. Ontology learning, usually referred to the (semi-)automatic support in ontology development, is usually divided into steps, going from concepts identification, passing through hierarchy and non-hierarchy relations detection and, seldom, axiom extraction. It is reasonable to say that among these steps the current frontier is in the establishment of concept hierarchies, since this is the backbone of ontologies and, therefore, a good concept hierarchy is already a valuable resource for many ontology applications. The automatic construction of concept hierarchies from texts is a complex task and much work have been proposing approaches to better extract relations between concepts. These different proposals have never been contrasted against each other on the same set of data and across different languages. Such comparison is important to see whether they are complementary or incremental. Also, we can see whether they present different tendencies towards recall and precision. This paper evaluates these different methods on the basis of hierarchy metrics such as density and depth, and evaluation metrics such as Recall and Precision. Results shed light over the comprehensive set of methods according to the literature in the area.