 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Preference Logic meets Iterated Belief Change: Representation Results and Postulates Characterization
Jan 05, 2021


AGM's belief revision is one of the main paradigms in the study of belief change operations. Recently, several logics for belief and information change have been proposed in the literature and used to encode belief change operations in rich and expressive semantic frameworks. While the connections of AGM-like operations and their encoding in dynamic doxastic logics have been studied before by the work of Segerberg, most works on the area of Dynamic Epistemic Logics (DEL) have not, to our knowledge, attempted to use those logics as tools to investigate mathematical properties of belief change operators. This work investigates how Dynamic Preference Logic, a logic in the DEL family, can be used to study properties of dynamic belief change operators, focusing on well-known postulates of iterated belief change.
A Machine Learning Early Warning System: Multicenter Validation in Brazilian Hospitals
Jun 09, 2020
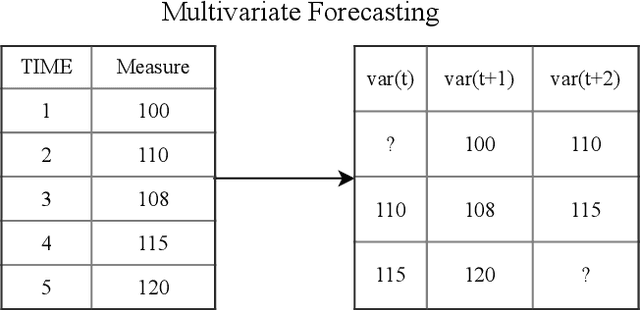
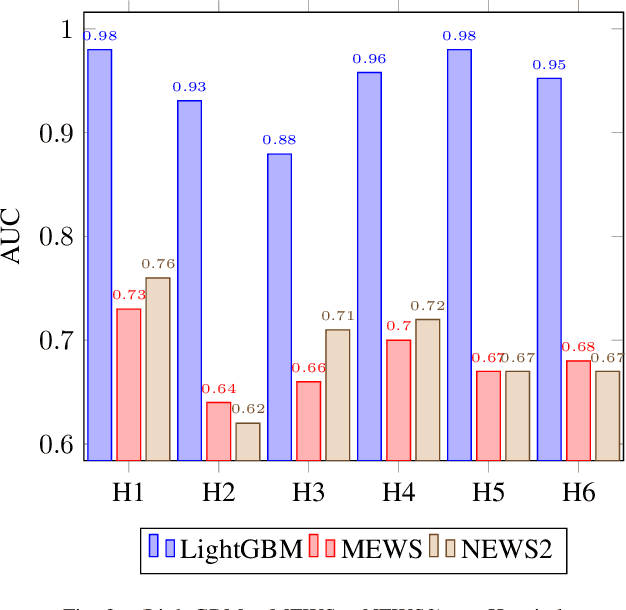
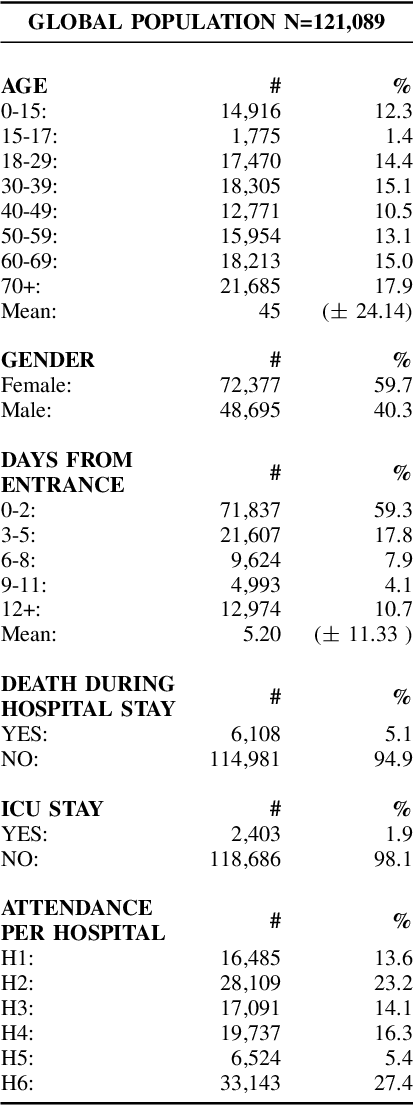
Early recognition of clinical deterioration is one of the main steps for reducing inpatient morbidity and mortality. The challenging task of clinical deterioration identification in hospitals lies in the intense daily routines of healthcare practitioners, in the unconnected patient data stored in the Electronic Health Records (EHRs) and in the usage of low accuracy scores. Since hospital wards are given less attention compared to the Intensive Care Unit, ICU, we hypothesized that when a platform is connected to a stream of EHR, there would be a drastic improvement in dangerous situations awareness and could thus assist the healthcare team. With the application of machine learning, the system is capable to consider all patient's history and through the use of high-performing predictive models, an intelligent early warning system is enabled. In this work we used 121,089 medical encounters from six different hospitals and 7,540,389 data points, and we compared popular ward protocols with six different scalable machine learning methods (three are classic machine learning models, logistic and probabilistic-based models, and three gradient boosted models). The results showed an advantage in AUC (Area Under the Receiver Operating Characteristic Curve) of 25 percentage points in the best Machine Learning model result compared to the current state-of-the-art protocols. This is shown by the generalization of the algorithm with leave-one-group-out (AUC of 0.949) and the robustness through cross-validation (AUC of 0.961). We also perform experiments to compare several window sizes to justify the use of five patient timestamps. A sample dataset, experiments, and code are available for replicability purposes.
Iterated Belief Base Revision: A Dynamic Epistemic Logic Approach
Feb 17, 2019AGM's belief revision is one of the main paradigms in the study of belief change operations. In this context, belief bases (prioritised bases) have been largely used to specify the agent's belief state - whether representing the agent's `explicit beliefs' or as a computational model for her belief state. While the connection of iterated AGM-like operations and their encoding in dynamic epistemic logics have been studied before, few works considered how well-known postulates from iterated belief revision theory can be characterised by means of belief bases and their counterpart in a dynamic epistemic logic. This work investigates how priority graphs, a syntactic representation of preference relations deeply connected to prioritised bases, can be used to characterise belief change operators, focusing on well-known postulates of Iterated Belief Change. We provide syntactic representations of belief change operators in a dynamic context, as well as new negative results regarding the possibility of representing an iterated belief revision operation using transformations on priority graphs.
Evaluating the Complementarity of Taxonomic Relation Extraction Methods Across Different Languages
Nov 08, 2018
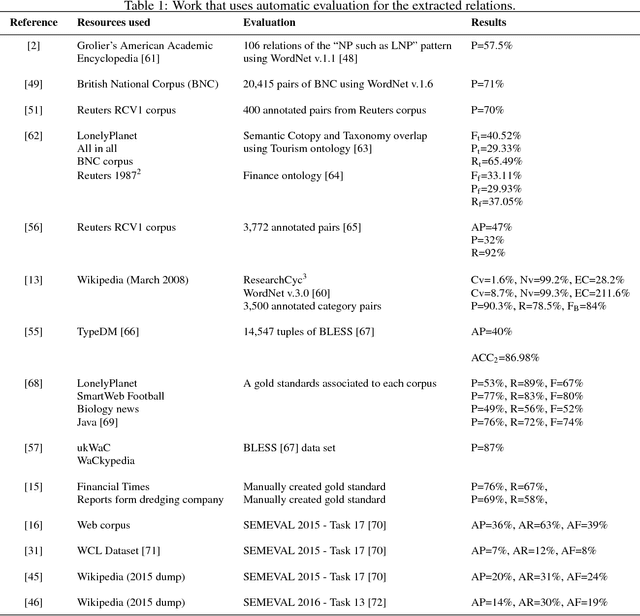


Modern information systems are changing the idea of "data processing" to the idea of "concept processing", meaning that instead of processing words, such systems process semantic concepts which carry meaning and share contexts with other concepts. Ontology is commonly used as a structure that captures the knowledge about a certain area via providing concepts and relations between them. Traditionally, concept hierarchies have been built manually by knowledge engineers or domain experts. However, the manual construction of a concept hierarchy suffers from several limitations such as its coverage and the enormous costs of its extension and maintenance. Ontology learning, usually referred to the (semi-)automatic support in ontology development, is usually divided into steps, going from concepts identification, passing through hierarchy and non-hierarchy relations detection and, seldom, axiom extraction. It is reasonable to say that among these steps the current frontier is in the establishment of concept hierarchies, since this is the backbone of ontologies and, therefore, a good concept hierarchy is already a valuable resource for many ontology applications. The automatic construction of concept hierarchies from texts is a complex task and much work have been proposing approaches to better extract relations between concepts. These different proposals have never been contrasted against each other on the same set of data and across different languages. Such comparison is important to see whether they are complementary or incremental. Also, we can see whether they present different tendencies towards recall and precision. This paper evaluates these different methods on the basis of hierarchy metrics such as density and depth, and evaluation metrics such as Recall and Precision. Results shed light over the comprehensive set of methods according to the literature in the area.
A Corpus-Based Investigation of Definite Description Use
Oct 24, 1997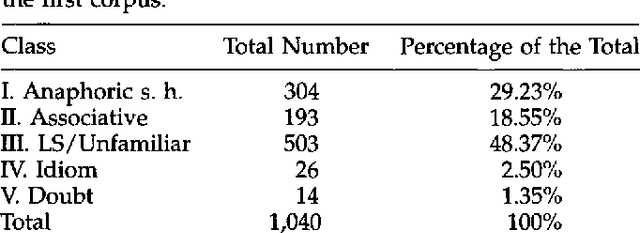
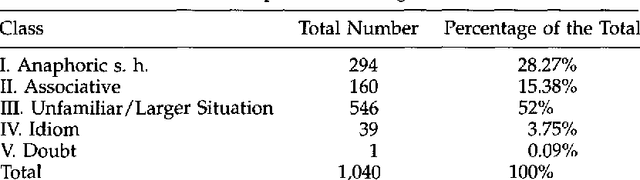
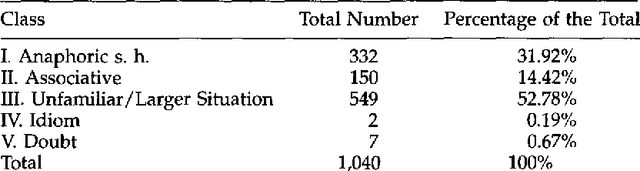
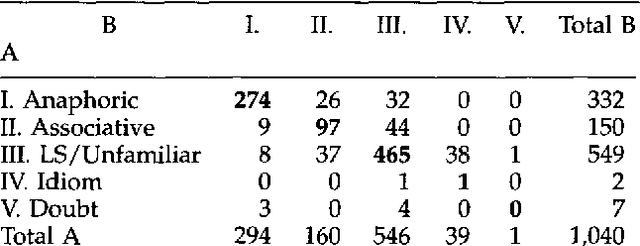
We present the results of a study of definite descriptions use in written texts aimed at assessing the feasibility of annotating corpora with information about definite description interpretation. We ran two experiments, in which subjects were asked to classify the uses of definite descriptions in a corpus of 33 newspaper articles, containing a total of 1412 definite descriptions. We measured the agreement among annotators about the classes assigned to definite descriptions, as well as the agreement about the antecedent assigned to those definites that the annotators classified as being related to an antecedent in the text. The most interesting result of this study from a corpus annotation perspective was the rather low agreement (K=0.63) that we obtained using versions of Hawkins' and Prince's classification schemes; better results (K=0.76) were obtained using the simplified scheme proposed by Fraurud that includes only two classes, first-mention and subsequent-mention. The agreement about antecedents was also not complete. These findings raise questions concerning the strategy of evaluating systems for definite description interpretation by comparing their results with a standardized annotation. From a linguistic point of view, the most interesting observations were the great number of discourse-new definites in our corpus (in one of our experiments, about 50% of the definites in the collection were classified as discourse-new, 30% as anaphoric, and 18% as associative/bridging) and the presence of definites which did not seem to require a complete disambiguation.