 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Ontology Matching with Large Language Model Embeddings
Feb 19, 2025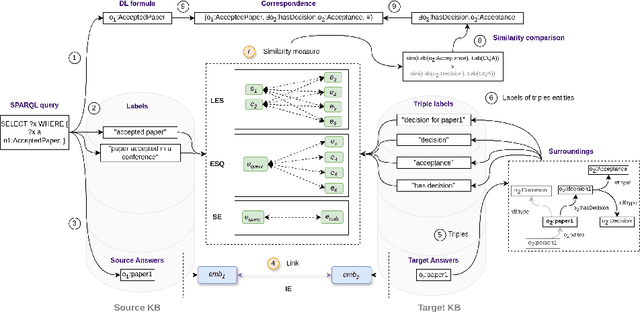
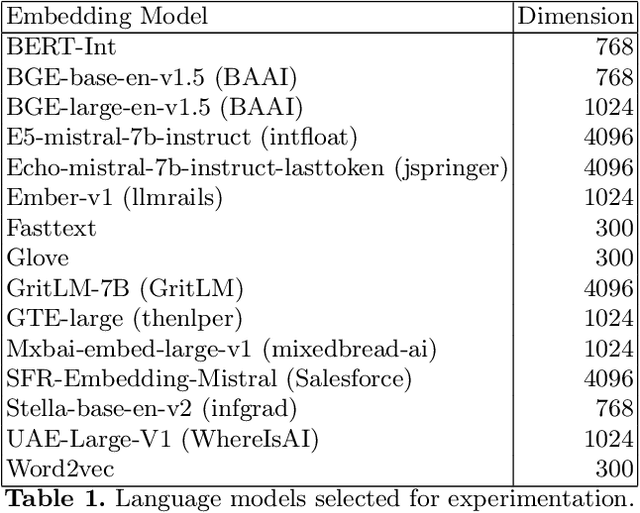

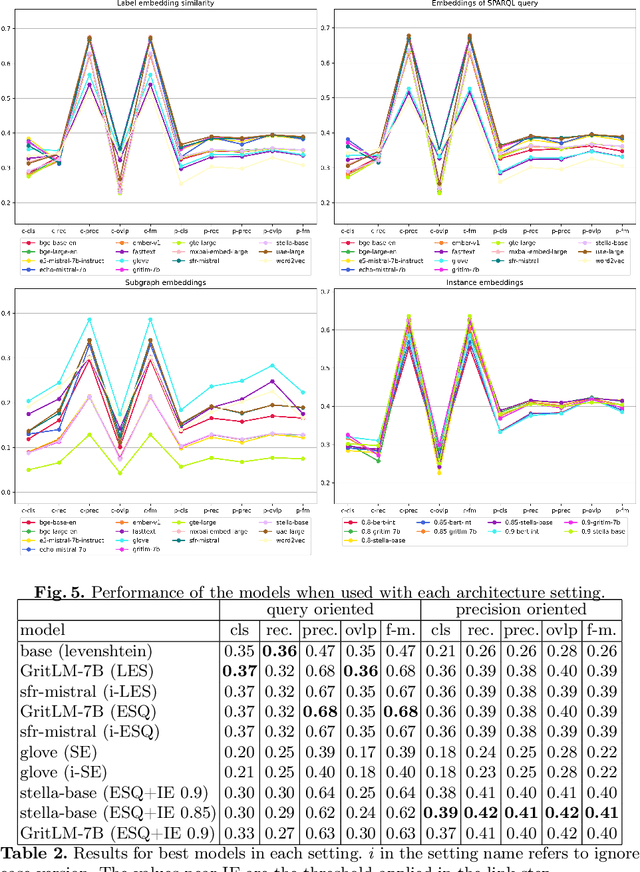
Ontology, and more broadly, Knowledge Graph Matching is a challenging task in which expressiveness has not been fully addressed. Despite the increasing use of embeddings and language models for this task, approaches for generating expressive correspondences still do not take full advantage of these models, in particular, large language models (LLMs). This paper proposes to integrate LLMs into an approach for generating expressive correspondences based on alignment need and ABox-based relation discovery. The generation of correspondences is performed by matching similar surroundings of instance sub-graphs. The integration of LLMs results in different architectural modifications, including label similarity, sub-graph matching, and entity matching. The performance word embeddings, sentence embeddings, and LLM-based embeddings, was compared. The results demonstrate that integrating LLMs surpasses all other models, enhancing the baseline version of the approach with a 45\% increase in F-measure.
Evaluating the Complementarity of Taxonomic Relation Extraction Methods Across Different Languages
Nov 08, 2018
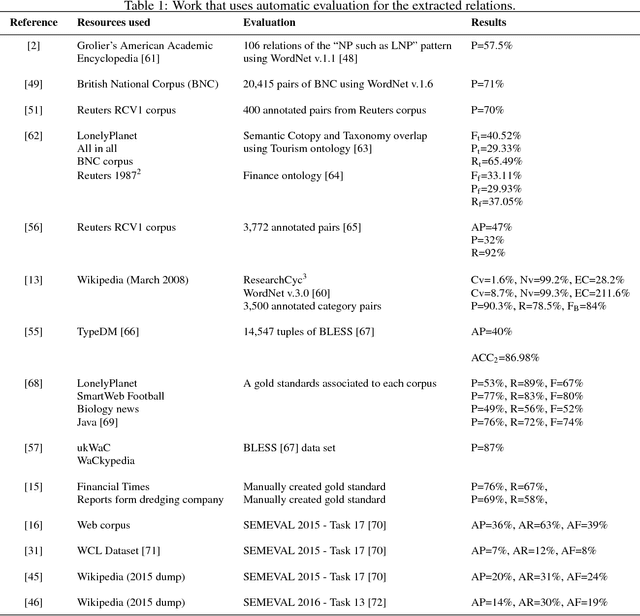


Modern information systems are changing the idea of "data processing" to the idea of "concept processing", meaning that instead of processing words, such systems process semantic concepts which carry meaning and share contexts with other concepts. Ontology is commonly used as a structure that captures the knowledge about a certain area via providing concepts and relations between them. Traditionally, concept hierarchies have been built manually by knowledge engineers or domain experts. However, the manual construction of a concept hierarchy suffers from several limitations such as its coverage and the enormous costs of its extension and maintenance. Ontology learning, usually referred to the (semi-)automatic support in ontology development, is usually divided into steps, going from concepts identification, passing through hierarchy and non-hierarchy relations detection and, seldom, axiom extraction. It is reasonable to say that among these steps the current frontier is in the establishment of concept hierarchies, since this is the backbone of ontologies and, therefore, a good concept hierarchy is already a valuable resource for many ontology applications. The automatic construction of concept hierarchies from texts is a complex task and much work have been proposing approaches to better extract relations between concepts. These different proposals have never been contrasted against each other on the same set of data and across different languages. Such comparison is important to see whether they are complementary or incremental. Also, we can see whether they present different tendencies towards recall and precision. This paper evaluates these different methods on the basis of hierarchy metrics such as density and depth, and evaluation metrics such as Recall and Precision. Results shed light over the comprehensive set of methods according to the literature in the area.