 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Ontology Matching with Large Language Model Embeddings
Feb 19, 2025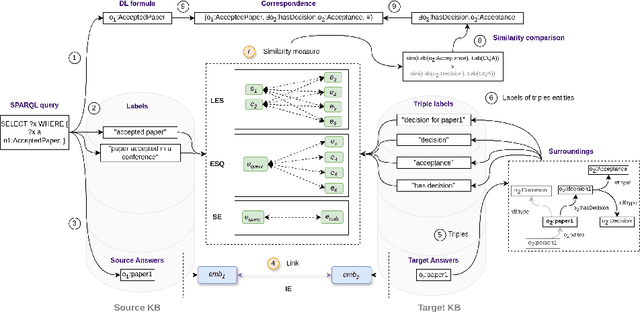
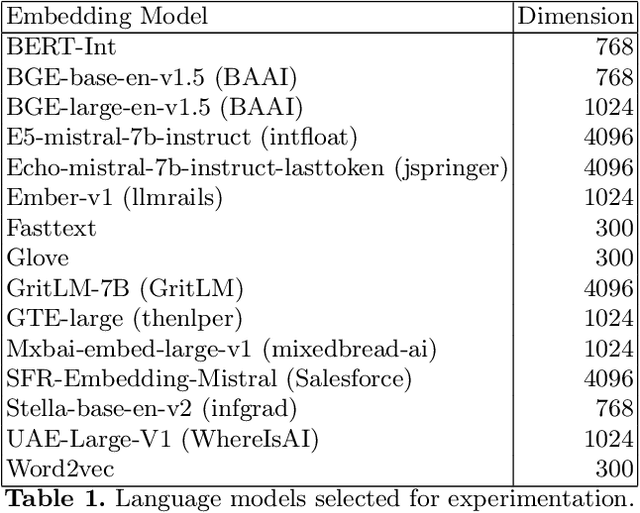

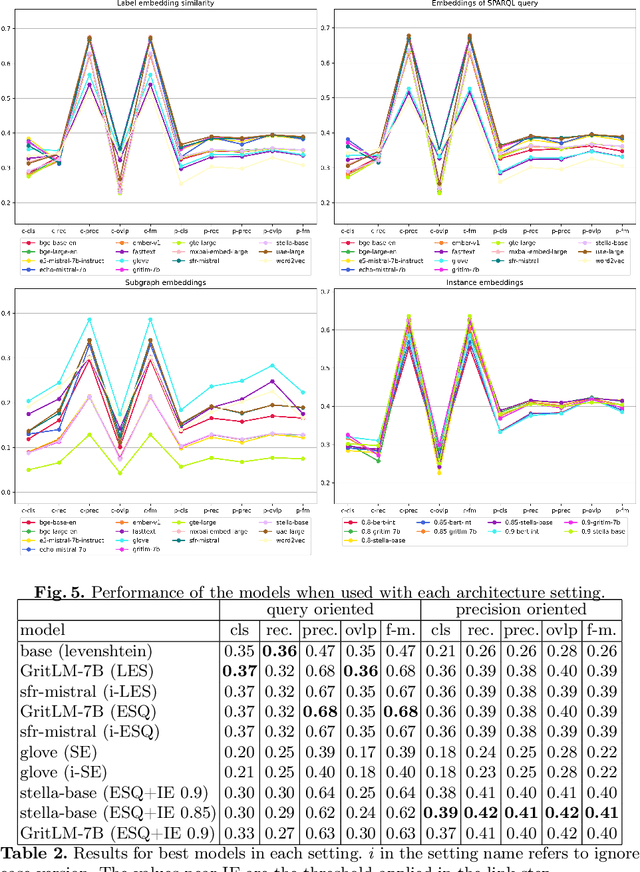
Ontology, and more broadly, Knowledge Graph Matching is a challenging task in which expressiveness has not been fully addressed. Despite the increasing use of embeddings and language models for this task, approaches for generating expressive correspondences still do not take full advantage of these models, in particular, large language models (LLMs). This paper proposes to integrate LLMs into an approach for generating expressive correspondences based on alignment need and ABox-based relation discovery. The generation of correspondences is performed by matching similar surroundings of instance sub-graphs. The integration of LLMs results in different architectural modifications, including label similarity, sub-graph matching, and entity matching. The performance word embeddings, sentence embeddings, and LLM-based embeddings, was compared. The results demonstrate that integrating LLMs surpasses all other models, enhancing the baseline version of the approach with a 45\% increase in F-measure.
A logic-based relational learning approach to relation extraction: The OntoILPER system
Jan 13, 2020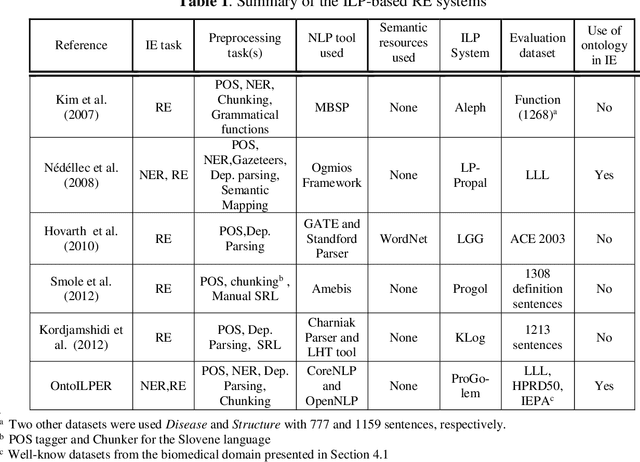

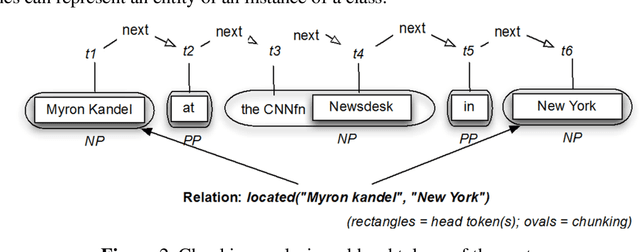
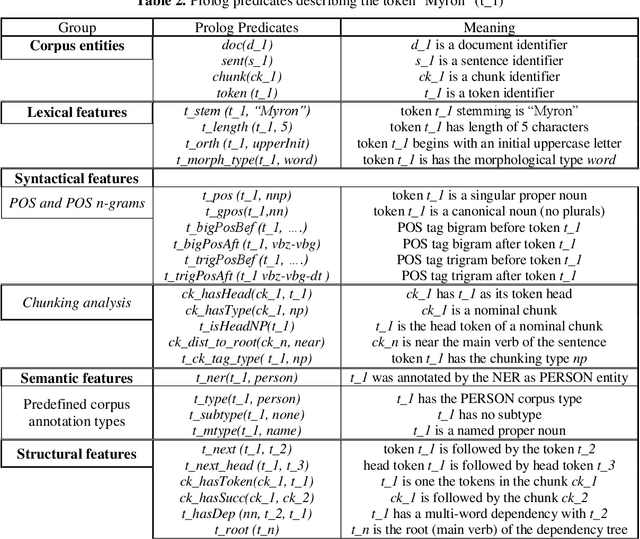
Relation Extraction (RE), the task of detecting and characterizing semantic relations between entities in text, has gained much importance in the last two decades, mainly in the biomedical domain. Many papers have been published on Relation Extraction using supervised machine learning techniques. Most of these techniques rely on statistical methods, such as feature-based and tree-kernels-based methods. Such statistical learning techniques are usually based on a propositional hypothesis space for representing examples, i.e., they employ an attribute-value representation of features. This kind of representation has some drawbacks, particularly in the extraction of complex relations which demand more contextual information about the involving instances, i.e., it is not able to effectively capture structural information from parse trees without loss of information. In this work, we present OntoILPER, a logic-based relational learning approach to Relation Extraction that uses Inductive Logic Programming for generating extraction models in the form of symbolic extraction rules. OntoILPER takes profit of a rich relational representation of examples, which can alleviate the aforementioned drawbacks. The proposed relational approach seems to be more suitable for Relation Extraction than statistical ones for several reasons that we argue. Moreover, OntoILPER uses a domain ontology that guides the background knowledge generation process and is used for storing the extracted relation instances. The induced extraction rules were evaluated on three protein-protein interaction datasets from the biomedical domain. The performance of OntoILPER extraction models was compared with other state-of-the-art RE systems. The encouraging results seem to demonstrate the effectiveness of the proposed solution.