 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegative Lexical Constraints in Neural Machine Translation
Aug 07, 2023



This paper explores negative lexical constraining in English to Czech neural machine translation. Negative lexical constraining is used to prohibit certain words or expressions in the translation produced by the neural translation model. We compared various methods based on modifying either the decoding process or the training data. The comparison was performed on two tasks: paraphrasing and feedback-based translation refinement. We also studied to which extent these methods "evade" the constraints presented to the model (usually in the dictionary form) by generating a different surface form of a given constraint.We propose a way to mitigate the issue through training with stemmed negative constraints to counter the model's ability to induce a variety of the surface forms of a word that can result in bypassing the constraint. We demonstrate that our method improves the constraining, although the problem still persists in many cases.
CUNI systems for WMT21: Multilingual Low-Resource Translation for Indo-European Languages Shared Task
Sep 20, 2021
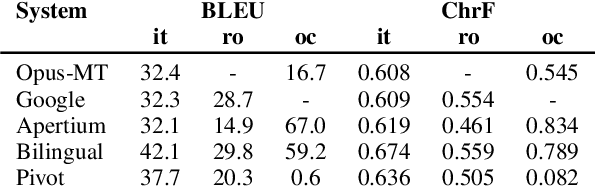
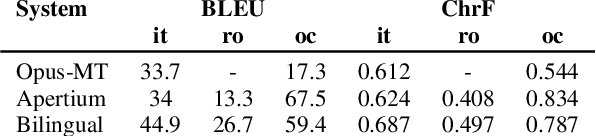

This paper describes Charles University submission for Multilingual Low-Resource Translation for Indo-European Languages shared task at WMT21. We competed in translation from Catalan into Romanian, Italian and Occitan. Our systems are based on shared multilingual model. We show that using joint model for multiple similar language pairs improves upon translation quality in each pair. We also demonstrate that chararacter-level bilingual models are competitive for very similar language pairs (Catalan-Occitan) but less so for more distant pairs. We also describe our experiments with multi-task learning, where aside from a textual translation, the models are also trained to perform grapheme-to-phoneme conversion.
CUNI systems for WMT21: Terminology translation Shared Task
Sep 20, 2021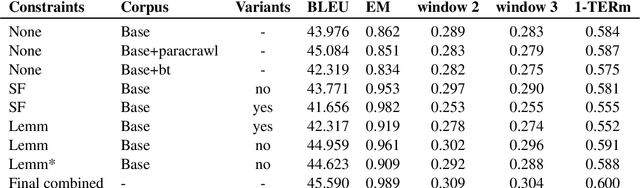

This paper describes Charles University submission for Terminology translation Shared Task at WMT21. The objective of this task is to design a system which translates certain terms based on a provided terminology database, while preserving high overall translation quality. We competed in English-French language pair. Our approach is based on providing the desired translations alongside the input sentence and training the model to use these provided terms. We lemmatize the terms both during the training and inference, to allow the model to learn how to produce correct surface forms of the words, when they differ from the forms provided in the terminology database. Our submission ranked second in Exact Match metric which evaluates the ability of the model to produce desired terms in the translation.
End-to-End Lexically Constrained Machine Translation for Morphologically Rich Languages
Jun 24, 2021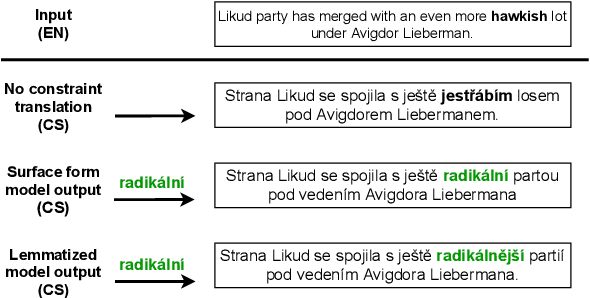
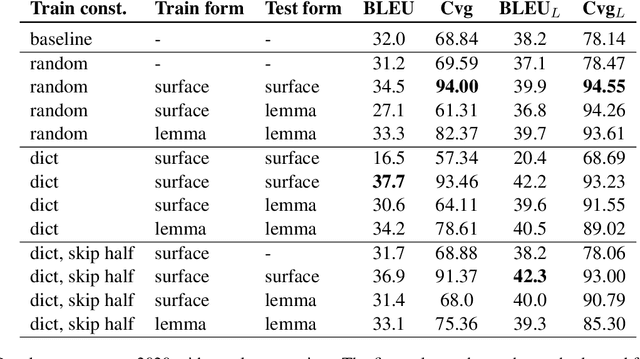
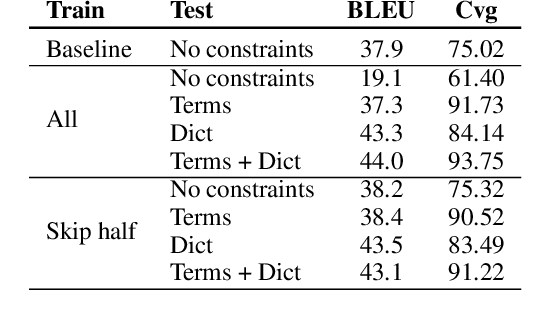
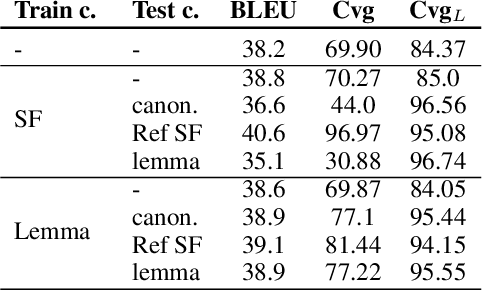
Lexically constrained machine translation allows the user to manipulate the output sentence by enforcing the presence or absence of certain words and phrases. Although current approaches can enforce terms to appear in the translation, they often struggle to make the constraint word form agree with the rest of the generated output. Our manual analysis shows that 46% of the errors in the output of a baseline constrained model for English to Czech translation are related to agreement. We investigate mechanisms to allow neural machine translation to infer the correct word inflection given lemmatized constraints. In particular, we focus on methods based on training the model with constraints provided as part of the input sequence. Our experiments on the English-Czech language pair show that this approach improves the translation of constrained terms in both automatic and manual evaluation by reducing errors in agreement. Our approach thus eliminates inflection errors, without introducing new errors or decreasing the overall quality of the translation.
Classifying Norm Conflicts using Learned Semantic Representations
May 13, 2019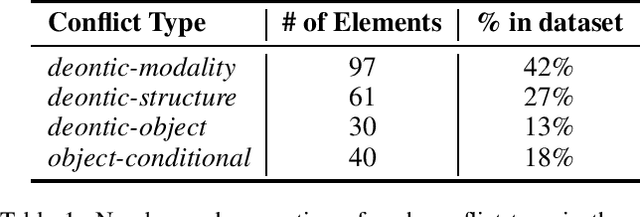
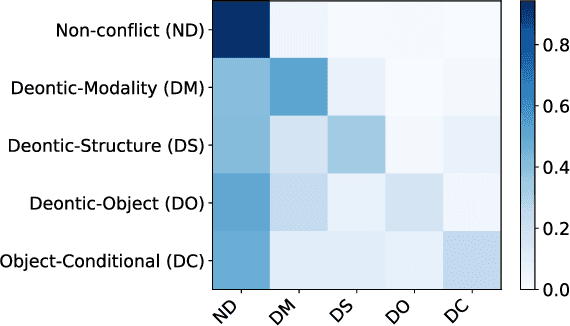
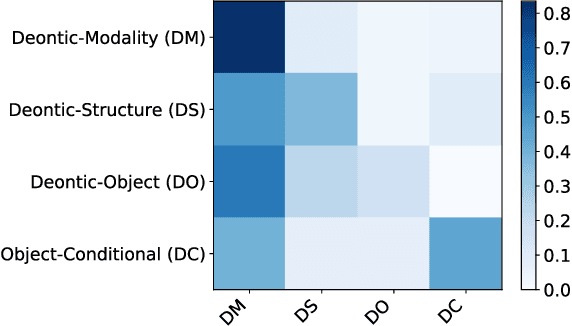
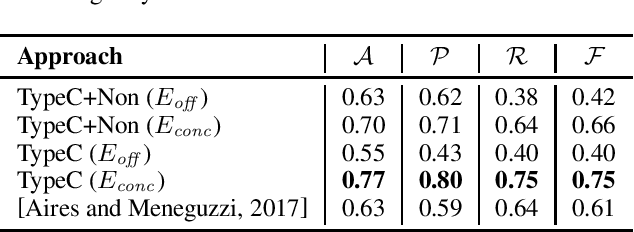
While most social norms are informal, they are often formalized by companies in contracts to regulate trades of goods and services. When poorly written, contracts may contain normative conflicts resulting from opposing deontic meanings or contradict specifications. As contracts tend to be long and contain many norms, manually identifying such conflicts requires human-effort, which is time-consuming and error-prone. Automating such task benefits contract makers increasing productivity and making conflict identification more reliable. To address this problem, we introduce an approach to detect and classify norm conflicts in contracts by converting them into latent representations that preserve both syntactic and semantic information and training a model to classify norm conflicts in four conflict types. Our results reach the new state of the art when compared to a previous approach.
LSTM-Based Goal Recognition in Latent Space
Aug 20, 2018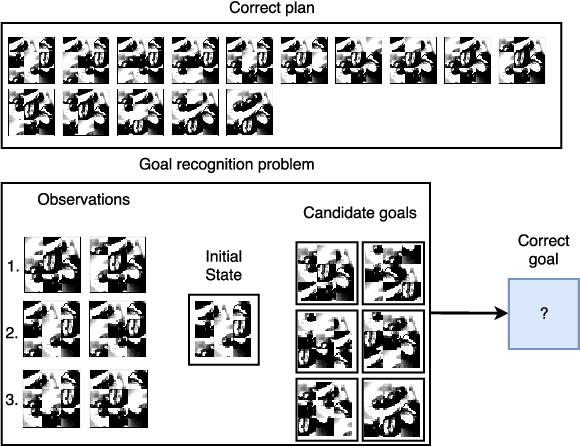
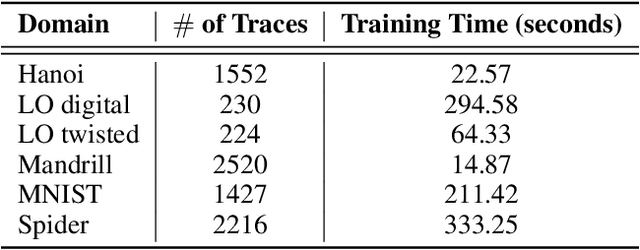
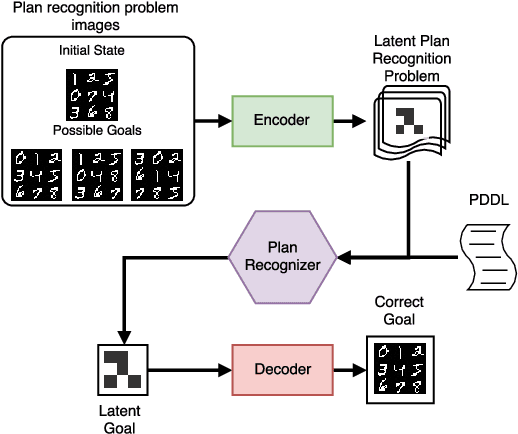

Approaches to goal recognition have progressively relaxed the requirements about the amount of domain knowledge and available observations, yielding accurate and efficient algorithms capable of recognizing goals. However, to recognize goals in raw data, recent approaches require either human engineered domain knowledge, or samples of behavior that account for almost all actions being observed to infer possible goals. This is clearly too strong a requirement for real-world applications of goal recognition, and we develop an approach that leverages advances in recurrent neural networks to perform goal recognition as a classification task, using encoded plan traces for training. We empirically evaluate our approach against the state-of-the-art in goal recognition with image-based domains, and discuss under which conditions our approach is superior to previous ones.