 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Expanded Massive Multilingual Dataset for High-Performance Language Technologies
Mar 13, 2025Training state-of-the-art large language models requires vast amounts of clean and diverse textual data. However, building suitable multilingual datasets remains a challenge. In this work, we present HPLT v2, a collection of high-quality multilingual monolingual and parallel corpora. The monolingual portion of the data contains 8T tokens covering 193 languages, while the parallel data contains 380M sentence pairs covering 51 languages. We document the entire data pipeline and release the code to reproduce it. We provide extensive analysis of the quality and characteristics of our data. Finally, we evaluate the performance of language models and machine translation systems trained on HPLT v2, demonstrating its value.
Adversarial Testing as a Tool for Interpretability: Length-based Overfitting of Elementary Functions in Transformers
Oct 17, 2024



The Transformer model has a tendency to overfit various aspects of the training data, such as the overall sequence length. We study elementary string edit functions using a defined set of error indicators to interpret the behaviour of the sequence-to-sequence Transformer. We show that generalization to shorter sequences is often possible, but confirm that longer sequences are highly problematic, although partially correct answers are often obtained. Additionally, we find that other structural characteristics of the sequences, such as subsegment length, may be equally important. We hypothesize that the models learn algorithmic aspects of the tasks simultaneously with structural aspects but adhering to the structural aspects is unfortunately often preferred by Transformer when they come into conflict.
Negative Lexical Constraints in Neural Machine Translation
Aug 07, 2023This paper explores negative lexical constraining in English to Czech neural machine translation. Negative lexical constraining is used to prohibit certain words or expressions in the translation produced by the neural translation model. We compared various methods based on modifying either the decoding process or the training data. The comparison was performed on two tasks: paraphrasing and feedback-based translation refinement. We also studied to which extent these methods "evade" the constraints presented to the model (usually in the dictionary form) by generating a different surface form of a given constraint.We propose a way to mitigate the issue through training with stemmed negative constraints to counter the model's ability to induce a variety of the surface forms of a word that can result in bypassing the constraint. We demonstrate that our method improves the constraining, although the problem still persists in many cases.
CUNI systems for WMT21: Multilingual Low-Resource Translation for Indo-European Languages Shared Task
Sep 20, 2021
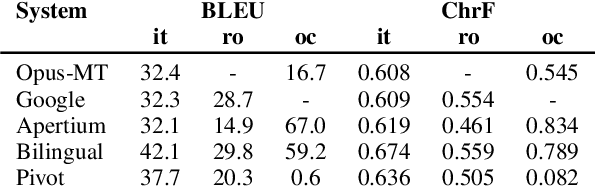
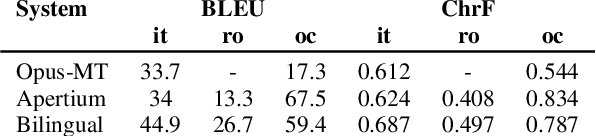

This paper describes Charles University submission for Multilingual Low-Resource Translation for Indo-European Languages shared task at WMT21. We competed in translation from Catalan into Romanian, Italian and Occitan. Our systems are based on shared multilingual model. We show that using joint model for multiple similar language pairs improves upon translation quality in each pair. We also demonstrate that chararacter-level bilingual models are competitive for very similar language pairs (Catalan-Occitan) but less so for more distant pairs. We also describe our experiments with multi-task learning, where aside from a textual translation, the models are also trained to perform grapheme-to-phoneme conversion.
CUNI systems for WMT21: Terminology translation Shared Task
Sep 20, 2021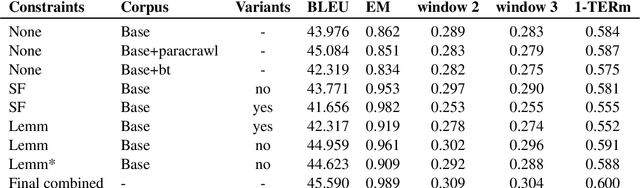

This paper describes Charles University submission for Terminology translation Shared Task at WMT21. The objective of this task is to design a system which translates certain terms based on a provided terminology database, while preserving high overall translation quality. We competed in English-French language pair. Our approach is based on providing the desired translations alongside the input sentence and training the model to use these provided terms. We lemmatize the terms both during the training and inference, to allow the model to learn how to produce correct surface forms of the words, when they differ from the forms provided in the terminology database. Our submission ranked second in Exact Match metric which evaluates the ability of the model to produce desired terms in the translation.
Sequence Length is a Domain: Length-based Overfitting in Transformer Models
Sep 15, 2021
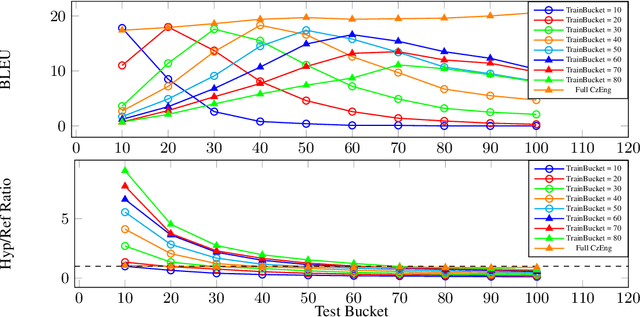


Transformer-based sequence-to-sequence architectures, while achieving state-of-the-art results on a large number of NLP tasks, can still suffer from overfitting during training. In practice, this is usually countered either by applying regularization methods (e.g. dropout, L2-regularization) or by providing huge amounts of training data. Additionally, Transformer and other architectures are known to struggle when generating very long sequences. For example, in machine translation, the neural-based systems perform worse on very long sequences when compared to the preceding phrase-based translation approaches (Koehn and Knowles, 2017). We present results which suggest that the issue might also be in the mismatch between the length distributions of the training and validation data combined with the aforementioned tendency of the neural networks to overfit to the training data. We demonstrate on a simple string editing task and a machine translation task that the Transformer model performance drops significantly when facing sequences of length diverging from the length distribution in the training data. Additionally, we show that the observed drop in performance is due to the hypothesis length corresponding to the lengths seen by the model during training rather than the length of the input sequence.
End-to-End Lexically Constrained Machine Translation for Morphologically Rich Languages
Jun 24, 2021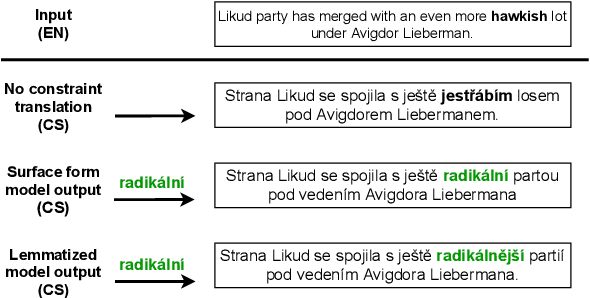
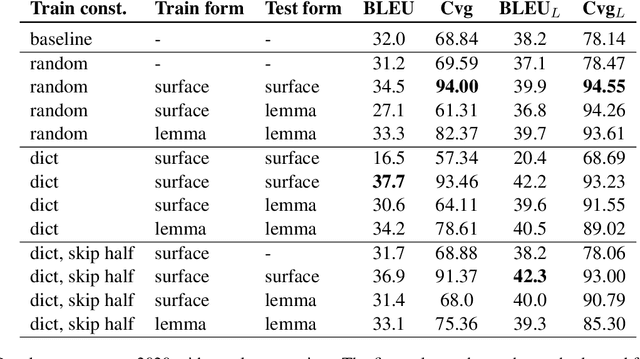
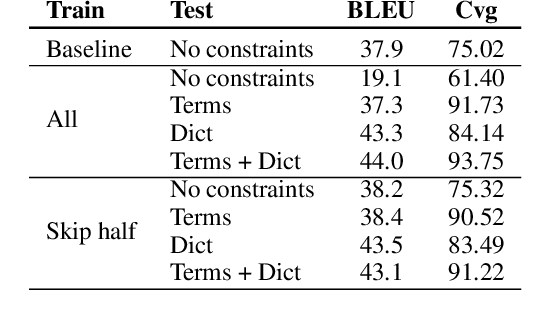
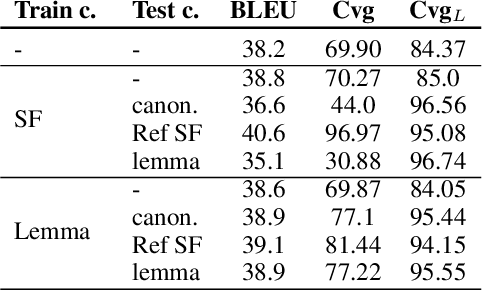
Lexically constrained machine translation allows the user to manipulate the output sentence by enforcing the presence or absence of certain words and phrases. Although current approaches can enforce terms to appear in the translation, they often struggle to make the constraint word form agree with the rest of the generated output. Our manual analysis shows that 46% of the errors in the output of a baseline constrained model for English to Czech translation are related to agreement. We investigate mechanisms to allow neural machine translation to infer the correct word inflection given lemmatized constraints. In particular, we focus on methods based on training the model with constraints provided as part of the input sequence. Our experiments on the English-Czech language pair show that this approach improves the translation of constrained terms in both automatic and manual evaluation by reducing errors in agreement. Our approach thus eliminates inflection errors, without introducing new errors or decreasing the overall quality of the translation.
Image Captioning with Visual Object Representations Grounded in the Textual Modality
Oct 20, 2020



We present our work in progress exploring the possibilities of a shared embedding space between textual and visual modality. Leveraging the textual nature of object detection labels and the hypothetical expressiveness of extracted visual object representations, we propose an approach opposite to the current trend, grounding of the representations in the word embedding space of the captioning system instead of grounding words or sentences in their associated images. Based on the previous work, we apply additional grounding losses to the image captioning training objective aiming to force visual object representations to create more heterogeneous clusters based on their class label and copy a semantic structure of the word embedding space. In addition, we provide an analysis of the learned object vector space projection and its impact on the IC system performance. With only slight change in performance, grounded models reach the stopping criterion during training faster than the unconstrained model, needing about two to three times less training updates. Additionally, an improvement in structural correlation between the word embeddings and both original and projected object vectors suggests that the grounding is actually mutual.
Unsupervised Pretraining for Neural Machine Translation Using Elastic Weight Consolidation
Oct 19, 2020


This work presents our ongoing research of unsupervised pretraining in neural machine translation (NMT). In our method, we initialize the weights of the encoder and decoder with two language models that are trained with monolingual data and then fine-tune the model on parallel data using Elastic Weight Consolidation (EWC) to avoid forgetting of the original language modeling tasks. We compare the regularization by EWC with the previous work that focuses on regularization by language modeling objectives. The positive result is that using EWC with the decoder achieves BLEU scores similar to the previous work. However, the model converges 2-3 times faster and does not require the original unlabeled training data during the fine-tuning stage. In contrast, the regularization using EWC is less effective if the original and new tasks are not closely related. We show that initializing the bidirectional NMT encoder with a left-to-right language model and forcing the model to remember the original left-to-right language modeling task limits the learning capacity of the encoder for the whole bidirectional context.
CUNI System for the WMT18 Multimodal Translation Task
Nov 12, 2018



We present our submission to the WMT18 Multimodal Translation Task. The main feature of our submission is applying a self-attentive network instead of a recurrent neural network. We evaluate two methods of incorporating the visual features in the model: first, we include the image representation as another input to the network; second, we train the model to predict the visual features and use it as an auxiliary objective. For our submission, we acquired both textual and multimodal additional data. Both of the proposed methods yield significant improvements over recurrent networks and self-attentive textual baselines.