 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Lexically Constrained Machine Translation for Morphologically Rich Languages
Paper and Code
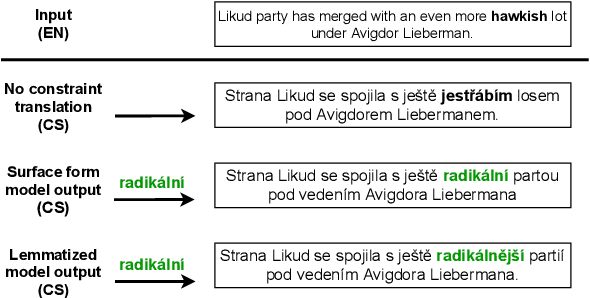
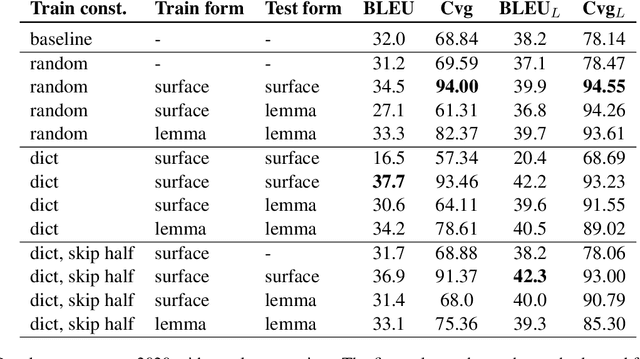
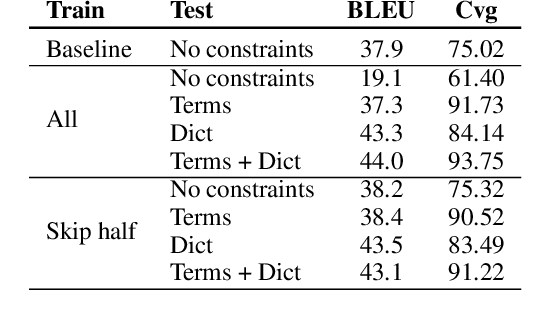
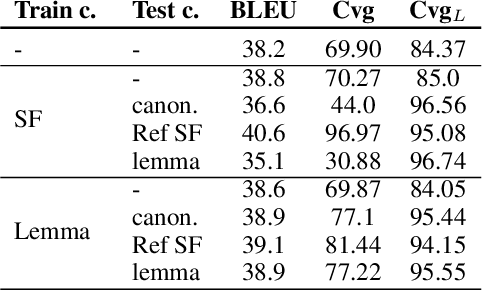
Lexically constrained machine translation allows the user to manipulate the output sentence by enforcing the presence or absence of certain words and phrases. Although current approaches can enforce terms to appear in the translation, they often struggle to make the constraint word form agree with the rest of the generated output. Our manual analysis shows that 46% of the errors in the output of a baseline constrained model for English to Czech translation are related to agreement. We investigate mechanisms to allow neural machine translation to infer the correct word inflection given lemmatized constraints. In particular, we focus on methods based on training the model with constraints provided as part of the input sequence. Our experiments on the English-Czech language pair show that this approach improves the translation of constrained terms in both automatic and manual evaluation by reducing errors in agreement. Our approach thus eliminates inflection errors, without introducing new errors or decreasing the overall quality of the translation.