 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to ASK: Uncertainty-Gated Language Assistance for Reinforcement Learning
Apr 02, 2026Reinforcement learning (RL) agents often struggle with out-of-distribution (OOD) scenarios, leading to high uncertainty and random behavior. While language models (LMs) contain valuable world knowledge, larger ones incur high computational costs, hindering real-time use, and exhibit limitations in autonomous planning. We introduce Adaptive Safety through Knowledge (ASK), which combines smaller LMs with trained RL policies to enhance OOD generalization without retraining. ASK employs Monte Carlo Dropout to assess uncertainty and queries the LM for action suggestions only when uncertainty exceeds a set threshold. This selective use preserves the efficiency of existing policies while leveraging the language model's reasoning in uncertain situations. In experiments on the FrozenLake environment, ASK shows no improvement in-domain, but demonstrates robust navigation in transfer tasks, achieving a reward of 0.95. Our findings indicate that effective neuro-symbolic integration requires careful orchestration rather than simple combination, highlighting the need for sufficient model scale and effective hybridization mechanisms for successful OOD generalization.
Beyond Mimicry: Toward Lifelong Adaptability in Imitation Learning
Feb 23, 2026Imitation learning stands at a crossroads: despite decades of progress, current imitation learning agents remain sophisticated memorisation machines, excelling at replay but failing when contexts shift or goals evolve. This paper argues that this failure is not technical but foundational: imitation learning has been optimised for the wrong objective. We propose a research agenda that redefines success from perfect replay to compositional adaptability. Such adaptability hinges on learning behavioural primitives once and recombining them through novel contexts without retraining. We establish metrics for compositional generalisation, propose hybrid architectures, and outline interdisciplinary research directions drawing on cognitive science and cultural evolution. Agents that embed adaptability at the core of imitation learning thus have an essential capability for operating in an open-ended world.
Towards Generalisable Imitation Learning Through Conditioned Transition Estimation and Online Behaviour Alignment
Jan 24, 2026State-of-the-art imitation learning from observation methods (ILfO) have recently made significant progress, but they still have some limitations: they need action-based supervised optimisation, assume that states have a single optimal action, and tend to apply teacher actions without full consideration of the actual environment state. While the truth may be out there in observed trajectories, existing methods struggle to extract it without supervision. In this work, we propose Unsupervised Imitation Learning from Observation (UfO) that addresses all of these limitations. UfO learns a policy through a two-stage process, in which the agent first obtains an approximation of the teacher's true actions in the observed state transitions, and then refines the learned policy further by adjusting agent trajectories to closely align them with the teacher's. Experiments we conducted in five widely used environments show that UfO not only outperforms the teacher and all other ILfO methods but also displays the smallest standard deviation. This reduction in standard deviation indicates better generalisation in unseen scenarios.
Explorative Imitation Learning: A Path Signature Approach for Continuous Environments
Jul 05, 2024



Some imitation learning methods combine behavioural cloning with self-supervision to infer actions from state pairs. However, most rely on a large number of expert trajectories to increase generalisation and human intervention to capture key aspects of the problem, such as domain constraints. In this paper, we propose Continuous Imitation Learning from Observation (CILO), a new method augmenting imitation learning with two important features: (i) exploration, allowing for more diverse state transitions, requiring less expert trajectories and resulting in fewer training iterations; and (ii) path signatures, allowing for automatic encoding of constraints, through the creation of non-parametric representations of agents and expert trajectories. We compared CILO with a baseline and two leading imitation learning methods in five environments. It had the best overall performance of all methods in all environments, outperforming the expert in two of them.
Imitation Learning: A Survey of Learning Methods, Environments and Metrics
Apr 30, 2024
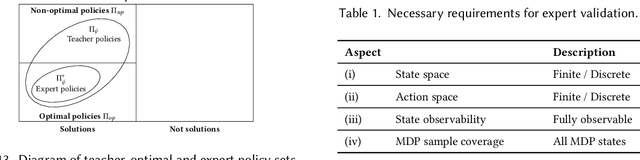

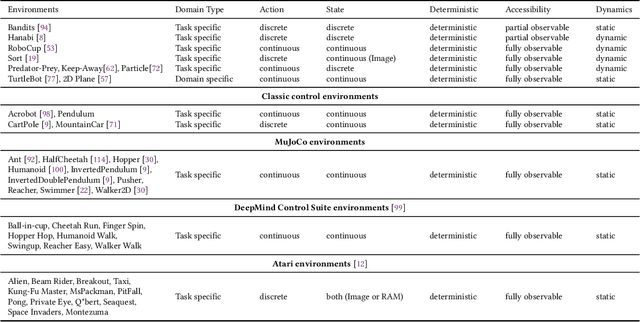
Imitation learning is an approach in which an agent learns how to execute a task by trying to mimic how one or more teachers perform it. This learning approach offers a compromise between the time it takes to learn a new task and the effort needed to collect teacher samples for the agent. It achieves this by balancing learning from the teacher, who has some information on how to perform the task, and deviating from their examples when necessary, such as states not present in the teacher samples. Consequently, the field of imitation learning has received much attention from researchers in recent years, resulting in many new methods and applications. However, with this increase in published work and past surveys focusing mainly on methodology, a lack of standardisation became more prominent in the field. This non-standardisation is evident in the use of environments, which appear in no more than two works, and evaluation processes, such as qualitative analysis, that have become rare in current literature. In this survey, we systematically review current imitation learning literature and present our findings by (i) classifying imitation learning techniques, environments and metrics by introducing novel taxonomies; (ii) reflecting on main problems from the literature; and (iii) presenting challenges and future directions for researchers.
Imitation Learning Datasets: A Toolkit For Creating Datasets, Training Agents and Benchmarking
Mar 01, 2024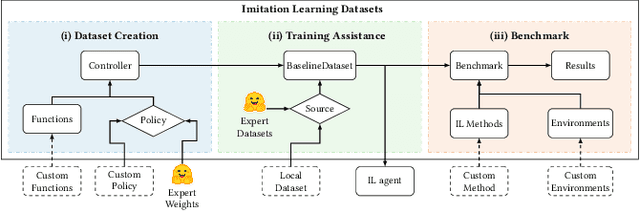
Imitation learning field requires expert data to train agents in a task. Most often, this learning approach suffers from the absence of available data, which results in techniques being tested on its dataset. Creating datasets is a cumbersome process requiring researchers to train expert agents from scratch, record their interactions and test each benchmark method with newly created data. Moreover, creating new datasets for each new technique results in a lack of consistency in the evaluation process since each dataset can drastically vary in state and action distribution. In response, this work aims to address these issues by creating Imitation Learning Datasets, a toolkit that allows for: (i) curated expert policies with multithreaded support for faster dataset creation; (ii) readily available datasets and techniques with precise measurements; and (iii) sharing implementations of common imitation learning techniques. Demonstration link: https://nathangavenski.github.io/#/il-datasets-video
Self-Supervised Adversarial Imitation Learning
Apr 21, 2023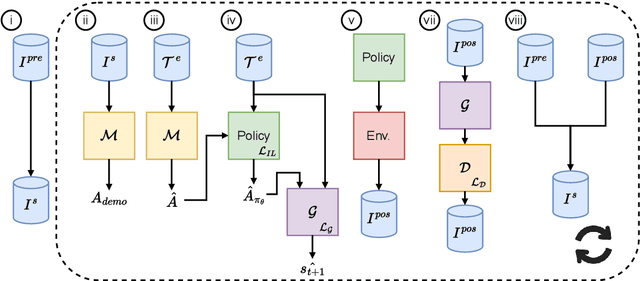
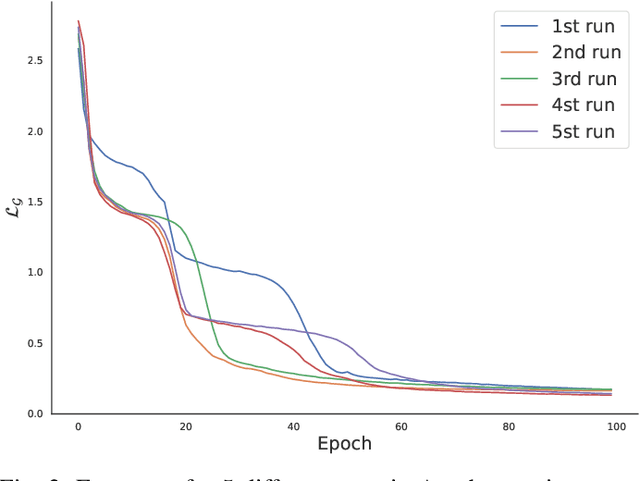
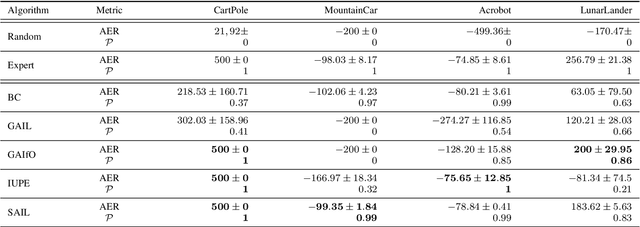
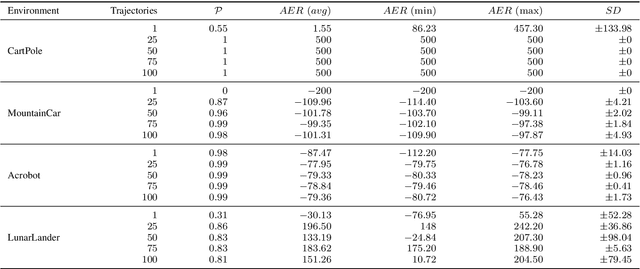
Behavioural cloning is an imitation learning technique that teaches an agent how to behave via expert demonstrations. Recent approaches use self-supervision of fully-observable unlabelled snapshots of the states to decode state pairs into actions. However, the iterative learning scheme employed by these techniques is prone to get trapped into bad local minima. Previous work uses goal-aware strategies to solve this issue. However, this requires manual intervention to verify whether an agent has reached its goal. We address this limitation by incorporating a discriminator into the original framework, offering two key advantages and directly solving a learning problem previous work had. First, it disposes of the manual intervention requirement. Second, it helps in learning by guiding function approximation based on the state transition of the expert's trajectories. Third, the discriminator solves a learning issue commonly present in the policy model, which is to sometimes perform a `no action' within the environment until the agent finally halts.
Imitating Unknown Policies via Exploration
Aug 13, 2020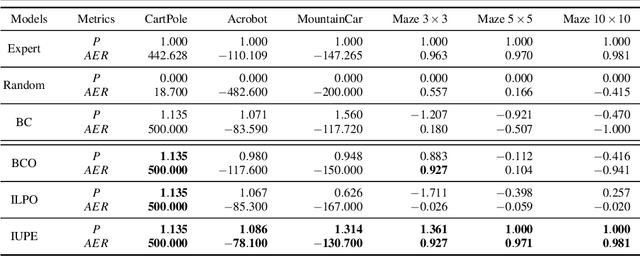
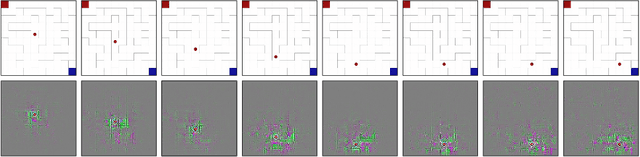

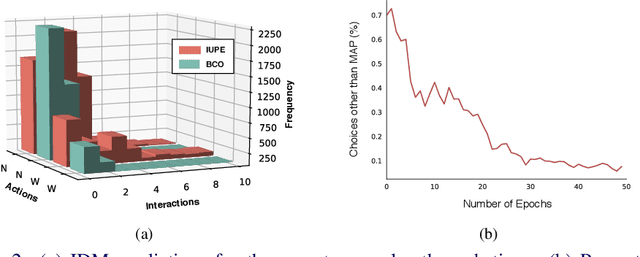
Behavioral cloning is an imitation learning technique that teaches an agent how to behave through expert demonstrations. Recent approaches use self-supervision of fully-observable unlabeled snapshots of the states to decode state-pairs into actions. However, the iterative learning scheme from these techniques are prone to getting stuck into bad local minima. We address these limitations incorporating a two-phase model into the original framework, which learns from unlabeled observations via exploration, substantially improving traditional behavioral cloning by exploiting (i) a sampling mechanism to prevent bad local minima, (ii) a sampling mechanism to improve exploration, and (iii) self-attention modules to capture global features. The resulting technique outperforms the previous state-of-the-art in four different environments by a large margin.
Attention-based 3D Object Reconstruction from a Single Image
Aug 11, 2020
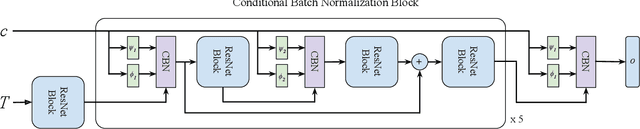


Recently, learning-based approaches for 3D reconstruction from 2D images have gained popularity due to its modern applications, e.g., 3D printers, autonomous robots, self-driving cars, virtual reality, and augmented reality. The computer vision community has applied a great effort in developing functions to reconstruct the full 3D geometry of objects and scenes. However, to extract image features, they rely on convolutional neural networks, which are ineffective in capturing long-range dependencies. In this paper, we propose to substantially improve Occupancy Networks, a state-of-the-art method for 3D object reconstruction. For such we apply the concept of self-attention within the network's encoder in order to leverage complementary input features rather than those based on local regions, helping the encoder to extract global information. With our approach, we were capable of improving the original work in 5.05% of mesh IoU, 0.83% of Normal Consistency, and more than 10X the Chamfer-L1 distance. We also perform a qualitative study that shows that our approach was able to generate much more consistent meshes, confirming its increased generalization power over the current state-of-the-art.
* 8 pages, 4 figures, 3 tables
Augmented Behavioral Cloning from Observation
Apr 28, 2020
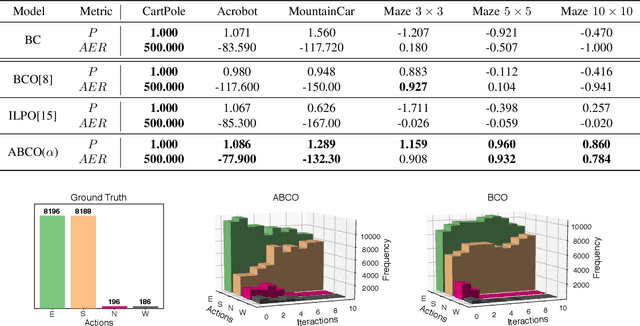

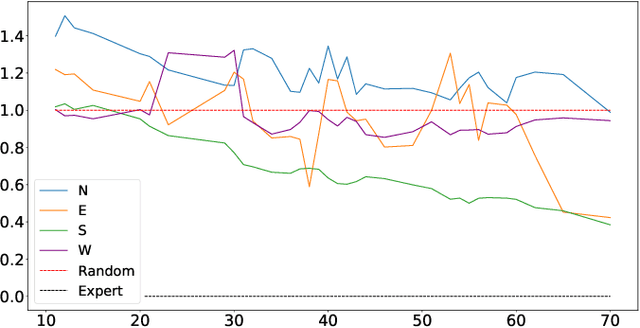
Imitation from observation is a computational technique that teaches an agent on how to mimic the behavior of an expert by observing only the sequence of states from the expert demonstrations. Recent approaches learn the inverse dynamics of the environment and an imitation policy by interleaving epochs of both models while changing the demonstration data. However, such approaches often get stuck into sub-optimal solutions that are distant from the expert, limiting their imitation effectiveness. We address this problem with a novel approach that overcomes the problem of reaching bad local minima by exploring: (I) a self-attention mechanism that better captures global features of the states; and (ii) a sampling strategy that regulates the observations that are used for learning. We show empirically that our approach outperforms the state-of-the-art approaches in four different environments by a large margin.